
✔ DDL
테이블 생성 구문
create [temporary] table [if not exists] 이름( 컬럼이름 자료형 [컬럼 제약 조건 나열], 컬럼이름 자료형 [컬럼 제약 조건 나열], ... [테이블 제약 조건])옵션 나열;
-- 테이블 이름은 contact -- 속성 -- num은 정수이고 일련번호 그리고 기본키 -- name은 한글 7글자까지 저장하고 글자 수 는 변경되지 않는다고 가정 -- address는 한글 100자까지 저장하고 글자 수의 변경이 자주 발생 -- tel은 숫자로된 문자열 11자리이고 글자 수의 변경은 발생하지 않음 -- email은 영문 100자 이내이고 글자 수의 변경이 자주 발생 -- birth 는 날짜만 저장 -- 주로 조회를 하고 일련번호는 1부터 시작하며, 인코딩은 utf8 CREATE TABLE contact( num INTEGER AUTO_INCREMENT PRIMARY KEY, name VARCHAR(21), -- 변경되지 않기 때문에 VARCHAR의 문제가 없다. address TEXT, tel VARCHAR(11), email CHAR(100), birth DATE )ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
자료형
- DB마다 조금씩 다릅니다.
- 숫자형
- INT(INTEGER)
- FLOAT, DOUBLE
- DECIMAL(전체 자릿수[, 소수 자릿수])
- 문자형(알아 둬야 할 것이 있어요)
- CHAR(바이트 수)
- VARCHAR(바이트 수)
- BINARY(바이트 수), VARBINARY(바이트 수)
- TEXT, LONGTEXT
- BLOB, LONGBLOB
- 한글을 저장하는 겨웅는 바이트 수 * 3
- CHAR는 고정된 공간에 저장, VARCHAR는 가변 공간에 저장
- CHAR(30)에 "가나다"저장하면, 30바이트 공간 할당 후 저장
- VARCHAR(30)에 "가나다" 저장하면, 30바이트 공간을 할당 받아서 "가나다"를 저장하고, 남는 21바이트는 다른 데이터를 저장할 수 있도록 할당합니다.(실제로는 9바이트 공간만 할당)
- VARCHAR의 경우, 데이터가 변경되어서 바이트 수가 변경이 된다면 ROW MIGRATION발생 가능성이 있습니다.
- "가나다"->"안녕하세요"로 바뀌면 옮겨야 하느라 시간이 걸릴거야.
- 프로그래밍에서 CHAR를 연결할 때는 뒤의 빈 칸에 주의해야 합니다.
- CHAR는 TRIM을 해주는게 좋아요- MySQL에서 VARCHAR를 쓸 때, 대소문자 구별을 하지 않고 비교를 합니다.
- 저장을 할 때는 대소문자 구별을 합니다.
- SELECT에서 비교할 때는 구별을 하지 않아요.
-BINARY를 만들 때 써준다. (메모리의 코드값 저장)
- 조회할 때 BINARY함수로 감싸서 해도 된다.
- 아니면 VARBINARY를 이용해서 생성을 하던가
- TEXT(655355)와 LOGTEXT(43억정도)는 긴 문자열을 저장하는데 이용하며, 인덱스 설정이 안됩니다.
- 이는 빠르게 검색하기 어렵습니다.- BLOB, LONGBLOB는 대용량의 바이트 배열을 저장하는데 일반적으로는 파일의 내용을 저장할 때 사용합니다.
- 파일을 DB에 저장하는 방법은
- 1. 파일의 경로만 저장하는 방법(권장)
- 2. 파일의 내용을 DB에 직접 저장하는 방법- 4GB까지는 저장 가능 하며, BLOG, LONGBLOG은 파일의 내용을 직접 저장하려고 사용하는 문자열 변수입니다.
- DB가 FILE STORAGE보다 훨씬 비싸기에 경로를 저장하는 방법을 주로 택합니다.
- 날짜와 시간
- DATE : 날짜만 저장
- DATETIME : 날짜와 시간을 저장하는데 초 단위까지 저장
- TIMESTAMP : 날짜와 시가능ㄹ 저장하는데 미세하게 저장
- TIME : 시간만 저장
- YEAR : 년도만 저장
- 기타
- BOOL : TURE OR FALSE
- JSON : JSON 문자열
- GEOMETRY : 공간 데이터
테이블 생성 옵션
ENGINE
- MyISAM : 조회에 유리하도록 만들며, 인덱스 기능이 우수함
- InnoDB : 트랜잭션 처리(삽입, 삭제, 갱신)에 유리하지만, 인덱스 기능이 떨어짐
auto_incremet
- 시퀀스(일련번호)의 초기 값을 설정
ALTER TABLE 테이블 이름 auto_increment=초기값을 이용해서 변경 가능
DEFAULT CHARSET
- 인코딩 방식으로 utf8 이나 utf8mb4 주로 이용
Collation
- 문자 정렬 방식
테이블에 컬럼 추가
-
이미 데이터가 있는 경우는 컬럼에 NULL 이 삽입됩니다.
-ALTER TABLE 테이블이름 ADD 컬럼이름 자료형 [컬럼제약 조건]ALTER TABLE contact ADD age INTEGER;
컬럼 삭제
- 기존의 데이터가 존재하면 데이터는 모두 삭제되며, 복구가 안됩니다.
-alter table 테이블이름 drop 컬럼명ALTER TABLE contact DROP age;
컬럼 수정
- 이름과 자료형을 수정
-alter table 테이블이름 change 기존컬럼이름 새로운컬럼이름 자료형
ALTER TABLE contact CHANGE tel phone INTEGER;
자료형 변경
alter table 테이블이름 modify 컬럼이름 자료형;
- NOT NULL (NULL 일 수 없다) 제약조건의 변경은 제약조건 변경이 아니고, 자료형 변경으로 취급합니다.
- 즉 NOT NULL의 추가나 삭제는 modify로 합니다.
- NOT NULL은 NULL인지 값을 넣어두는 것이 아닌, NULL인지 한 바이트 가져와서 체크하는 개념이기에 그렇다.
MySQL은 컬럼 순서 조정이 가능하다
컬럼 순서 조정
ALTER TABLE 테이블이름 MODIFY COLUMN 컬럼이름 자료형 FIRST/다른컬럼이름;
- 다른컬럼이름 쓰면 그 뒤에 놓는다는 것이다.
테이블 이름 변경
ALTER TABLE 이전 테이블 이름 RENAME 새로운 테이블 이름;
테이블 삭제
DROP TABLE 테이블이름;
- 외래키가 설정되어 있는 테이블은 삭제되지 않습니다.
-- conatact 테이블 삭제 DROP TABLE contact; -- 테이블 삭제 확인 SHOW TABLES;
테이블의 모든 데이터 삭제
TRUNCATE TABLE 테이블 이름;
- 데이터는 복구되지 않기 때문에 주의해야 합니다.
테이블 압축
- CREATE TALBLE의 옵션으로
W_FORAMT=COMPRESSED를 추가하면 압축해서 생성
- 저장 용량은 줄어들지만, 작업 시간이 늘어납니다.
테이블 주석
- `
COMMENT ON TABLE 테이블 이름 IS '주석';
CONSTRAINT - 제약조건
DATA INTEGRITY
- 데이터의 정확성과 일관성을 유지하고 보증하는 것
- Entity Integrity(개체 무결성)
- Primary Key(기본키)는 NULL이거나 중복될 수 없다. - Referentail Integrity(참조 무결성)
- Foreign Key(외래키, 참조키)는 NULL이거나 참조 가능한 값을 가져야 한다. - Domain Integrity(도메인 무결성)
- 컬럼에는 설정한 도메인 값만을 저장해야 한다.
NOT NULL
- 필수 입력을 위한 제약조건
- 컬럼 제약 조건으로만 설정가능합니다.
- DB에서 NULL을 표현할 때, NULL값을 저장하는 것이 아니고, NULL을 표현하기 위한 별도의 메모리를 할당합니다.
- NOT NULL이 적용된 컬럼과 적용되지 않은 컬럼의 크기가 1 차이가 납니다.
- NOT NULL의 제약조건이지만, 데이터의 크기와도 연관성이 있음
-- not null 제약조건 설정 CREATE TABLE tNullable( name CHAR(10) not null, age int ); insert into tNullable(name, age) values("mino","123"); -- 에러 insert into tNullable(age) vaules(44);name이 not null인데 이를 insert를 안하면 오류가 발생한다.
DEFALUT
- 컬럼의 값이 입력이 안될 때 자동으로 설정되는 값
- 컬럼의 자료형 다음에
DEFAULT 값 - 기본 값을 사용하고자 하는 경우는 컬럼을 제외하고 입력하던가, DEFAULT로 입력하면 됩니다.
-- 기본값 설정 CREATE TABLE tDefault( name CHAR(10) not null, age INTEGER DEFAULT 24 ); insert into tDefault(name, age) values("mino",26); insert into tDefault(name) values("mino2"); select * from tDefault; drop table tDefault;
CHECK
- 속성의 값을 제한하는 제약조건
CHECK(컬럼이름 조건)
성별은 남 / 여 만 가져야 한다.
-gender CHAR(3) CHECK(gender in ('남','여'));
점수는 0에서 100사이의 값을 가져야 한다.
-score INTEGER CHECK(score BETWEEN 0 AND 100);
-- name, gender(성별 - 남, 여), age(나이는 양수)를 속성으로 갖는 -- 테이블 생성 CREATE TABLE tCheck( name CHAR(10) NOT NULL, gender CHAR(3) CHECK(gender IN('남','여')), age INTEGER CHECK(age>=0) ); INSERT INTO tCheck(name, gender, age) VALUES ('이민호', '남', 26); INSERT INTO tCheck(name, gender, age) VALUES ('이민호', '남자', 26); INSERT INTO tCheck(name, gender, age) VALUES ('이민호', '남', -26);맨 처음 입력 데이터만 릴레이션에 들어간 것을 확인할 수 있다.
Primary Key
- 기본키를 설정
- 기본키는 NOT NULL이고 UNIQUE 합니다.
- 테이블에서 기본키는 하나만 설정 가능합니다.
- 컬럼 제약 조건으로 설정할 수 있고, 테이블 제약 조건으로 설정할 수 도 있습니다.
- 하나의 속성으로 설정할 수 있고, 여러 개의 속성으로도 설정이 가능합니다.
- 단, 여러 개의 속성으로 설정할 때는 테이블 제약 조건으로 설정해야 합니다.
- 컬럼 제약 조건 : 컬럼의 자료형 뒤에 설정하는 것
- 테이블 제약 조건 : 컬럼을 전부 정의한 후, 제약 조건을 설정하는 것
- 기본키를 설정하면 인덱스가 생성되고 MySQL은 기본키 순서대로 저장됩니다.
컬럼 제약 조건
컬럼 이름 자료형 [CONSTRAINT 제약조건 이름] PRIMARY KEY
테이블 제약 조건
[CONSTRAINT 제약조건 이름] PRIMARY KEY(컬럼 이름 나열)
-- 기본키 설정 : 제약조건 이름없이 생성 CREATE TABLE tPK1( name char(10) primary key, age int ); -- 기본키 설정 : 제약조건 이름과 함께 생성 CREATE TABLE tPK2 ( name char(10) PRIMARY KEY, age int ); -- 기본키 설정 : 테이블 제약 조건 CREATE TABLE tPK3( name char(10), age int, constraint tpk3_pk primary key(name) ); -- 2개의 컬럼으로 기본키 설정: 테이블 생성 시, primary key는 한번만 사용가능 -- 이건 오류 CREATE TABLE tPK4( name char(10) primary key, age int primary key, ); -- 무조건 이건 테이블제약으로 해야함 CREATE TABLE tPK4( name char(10), age int, constraint pk4_pk primary key(name, age) ); insert into tPK1(name, age) values('mino', 24); -- 기본키인 name의 값이 같아서 삽입 실패 insert into tPK1(name, age) values('mino', 25); -- 기본키인 name의 값이 null이라 삽입 실패 insert into tPK1(age) values(26);
UNIQUE
- 중복된 값을 허용하지 않는 제약조건
- NULL은 가능
- 설정하는 방법은 PRIMARY KEY와 동일
- 자동으로 인덱스가 만들어지지만, 순서대로 저장되지는 않습니다.
-- UNIQUE create table tUnique( name char(10), age int unique, constraint tunique primary key(name) ); insert into tUnique(name, age) values('mino', 26); -- age 중복으로 실패 insert into tUnique(name, age) values('mino2',26); -- null 들어가짐, null은 중복체크 대상이 아니라서 가능함 insert into tUnique(name) values('mino3'); select * from tUnique;
FOREIGN KEY(외래키)
- 다른 테이블을 참조하기 위한 속성
- 다른 테이블에서는 primary key 나 unique한 속성이어야 한다.
- 설정 방법
- 컬럼 제약 조건
references 참조할 테이블이름(컬럼이름) [옵션]
- 테이블 제약 조건
[constraint 이름] foreign key(외래키 컬럼 이름) references 참조테이블이름(컬럼이름) - 옵션 없이 외래키를 설정하면 값은 NULL이거나 참조할 테이블에 존재하는 값만 삽입이 가능합니다.
- 참조당하는 테이블에서는 참조되는 데이터를 삭제할 수 없습니다.
- 외래키를 설정할 떄는 1:1 경우는 양 테이블의 기본키를 다른 테이블에 외래키로 추가해야 하며, 1:N 관계에서는 1쪽의 기본키를 N쪽에 외래키로 추가해야하며, N:N의 경우에는 양쪽의 기본키를 외래키를 갖는 별도의 테이블을 생성해야 합니다.
-- 외래키 설정 : 직우너과 프로젝트의 관계는 1:N이다. -- 직원 테이블 create table temployee( name char(10) primary key, salary int not null, addr varchar(30) not null ); insert into temployee values('mino', 550, '서울'); insert into temployee values('mino2', 750, '경기'); insert into temployee values('mino3', 950, '판교'); -- 프로젝트 테이블 -- employee는 프로젝트에 참여한 직원이다. create table tproject( projectID int primary key, employee char(10) not null references temployee(name), project varchar(30) not null, cost int ); -- 테이블 제약 조건 방식(권장) create table tproject( projectID int primary key, employee char(10) not null, project varchar(30) not null, cost int, constraint fk_emp foreign key(employee) references temployee(name) ); show tables; insert into tproject values(1, 'mino', '웹 서비스', 3000); -- temployee 에 없는 mino4인데 입력되는 상황 insert into tproject values(2, 'mino4', 'microservie 구축', 5000); -- mino2는 입력 프로젝트 테이블에 없다. delete from temployee where name='mino2'; -- mino는 프로젝트 테이블에도 존재하기에 에러가 난다. delete from temployee where name='mino'; -- employee테이블은 삭제도 안된다. drop table temployee; select * from temployee; select * from tproject;
옵션
ON DELETE {NO ACTION | CASCADE | SET NULL | SET DEFAULT}
4가지 중 선택해서 사용 가능ON UPDATE {NO ACTION | CASCADE | SET NULL | SET DEFAULT}
4가지 중 선택해서 사용 가능
- NO ACTION : 참조하고 있는 테이블에 변화가 생겨도 아무 액션도 취하지 않음
- CASCADE : 같이 삭제되거나 수정
- (참조당하는 테이블에서 삭제하려하면 외래키 들고있는 테이블에서 동일하게 수정)- SET NULL : NULL로 변경
- (참조당하는 테이블에서 삭제하려하면 외래키 들고있는 테이블에서 NULL로 수정)- SET DEFAULT : 기본값으로 변경
- (참조당하는 테이블에서 삭제하려하면 외래키 들고있는 테이블에서 DEFAULT로 수정)
-- 옵션 공부하기 create table temployee( name char(10) primary key, salary int not null, addr varchar(30) not null ); insert into temployee values('mino', 550, '서울'); insert into temployee values('mino2', 750, '경기'); insert into temployee values('mino3', 950, '판교'); select * from temployee; -- 삭제 / 수정 시 각 테이블에 있는 데이터가 동일하게 진행되도록 create table tproject( projectID int primary key, employee char(10) not null, project varchar(30) not null, cost int, constraint fk_emp foreign key(employee) references temployee(name) on delete cascade on update cascade ); insert into tproject values(1, 'mino', '웹 서비스', 3000); -- mino 가 prjoect에 들어가있음 select * from tproject; -- 역시나 안됨 insert into tproject values(2, 'mino4', 'microservie 구축', 5000); -- employee에서 지워진다. 이제 delete from temployee where name='mino'; select * from tproject; select * from temployee; UPDATE temployee SET name='minomino' where name='mino'; -- 반대는 안된다. UPDATE tproject SET employee='minomino' where employee='mino';
-- 옵션 SET NULL create table temployee( name char(10) primary key, salary int not null, addr varchar(30) not null ); insert into temployee values('mino', 550, '서울'); insert into temployee values('mino2', 750, '경기'); insert into temployee values('mino3', 950, '판교'); select * from temployee; -- 삭제 / 수정 시 set null create table tproject( projectID int primary key, employee char(10), -- set null 할때 not null 빼야해 project varchar(30) not null, cost int, constraint fk_emp foreign key(employee) references temployee(name) on delete SET NULL on update SET NULL ); insert into tproject values(1, 'mino', '웹 서비스', 3000); -- mino 가 prjoect에 들어가있음 select * from tproject; -- employee에 있는 애를 삭제해보자. delete from temployee where name='mino'; -- employee에 있는 애를 바꿔보자. UPDATE temployee SET name='minomino' where name='mino'; select * from tproject; select * from temployee; -- 참조 하는 데이터가 값이 수정당하니까 NULL이 되어버렸다. -- 참조 당하는 데이터는 바로 바뀌었고
외래키 설정 시, 컬럼 제약 조건으로 설정하면 제대로 동작하지 않는 MySQL 버전이 존재합니다. 그러므로 테이블 제약 조건으로 작성합시다.
AUTO_INCREMENT
- MySQL에서 일련번호를 설정하기 위해서 사용하는 것
- 하나의 테이블에서 한 번만 사용 가능
- AUTO_INCREMENT가 설정된 컬럼은 UNIQUE나 PRIMARY KEY 제약 조건이 설정되어야 합니다.
- 테이블 생성 시, 초기 값을 설정할 수 있고, ALTER TABLE 명령을 이용해서 초기 값 변경이 가능합니다.
- AUTO_INCREMENT 설정이 되어 있어도 직접 값을 입력할 수 있지만 권장하지는 않습니다.
- 어떤 값이 들어갈지 예측하기 어려워집니다.
-- 일련번호 사용 -- primary key 지정 혹은 unique를 해줘야 합니다. create table board( num int AUTO_INCREMENT PRIMARY KEY, title char(100), content text ); -- num을 빼고 넣어도 num은 자동으로 증가되면서 들어가진다. insert into board(title, content) values("제목", "안녕하세요?"); insert into board(title, content) values("제목2", "안녕하세요?2"); select * from board; -- 2번 데이터를 삭제하고 하나 넣으면? delete from board where num=2; insert into board(title, content) values("제목3", "안녕하세요?3"); select * from board; -- 이것의 것을 지웠다고 해서 숫자가 줄어드는 것은 아니다. -- auto_increment 값도 직접 넣을 수 있다. 다음 값은 모르겠다. insert into board(num, title, content) values(400,"제목4","안녕하세요?4"); insert into board(title, content) values("제목5","안녕하세요?5"); insert into board(title, content) values("제목6", "안녕하세요?6"); select *from board; -- 중간에 초기값을 변경할 수 있어요 alter table board auto_increment =1000; insert into board(title, content) values("제목7", "안녕하세요?7"); select * from board; drop table board;
제약조건 작업
-
조회
select * from information.schema_table_constraints -
수정
alter table 테이블명 modify 컬럼명 자료형 제약조건 -
추가
alter table 테이블명 add 테이블 제약조건 형태로 작성하기 -
삭제
alter table 테이블명 drop 제약조건이름
✔ DML
- 데이터를 삽입하고 삭제하고 수정하는 명령
- 이론에서는 select도 dml로 간주하지만, 실무에서는 dql로 분리한다.
데이터 삽입
기본 형식
insert into 테이블이름(컬럼이름 나열) values(값을 나열);
- 모든 컬럼에 값을 순서대로 삽입할 때는 컬럼 이름을 생략- 제외된 컬럼은 DEFAULT 값이 있으면
DEFAULT 값(AUTO_INCREMENT 포함)이 설정되고, DEFAULT 값이 없으면 NULL이 삽입됩니다. - ORACLE에서는 INTO 생략가능합니다.
- values 다음에 여러 개의 데이터를 입력해서 한꺼번에 삽입하는 것이 가능합니다.
- select 구문의 결과를 삽입할 수 있습니다.
-insert into 테이블이름(컬럼이름) select 구문 - select 구문의 결과로 테이블을 생성 - 테스트 할 때 주로 이용합니다.
-create table 테이블이름 as select 구문 - 스크립트를 이용해서 삽입할 때, insert 다음에 ignore를 추가하면 에러가 발생해도 다음 스크립트를 수정한다.
-- 데이터 삽입을 위해서 테이블 구조를 확인 DESC tCity; -- 컬럼 이름을 나열해서 데이터를 삽입하기 insert into tCity(name, area, popu, metro, region) values("영등포", 600, 200, 'y', '서울'); -- 모든 컬럼의 값을 순서대로 입력하는 경우는 컬럼 이름 생략이 가능 insert into tCity values('구로', 40,60,'y','서울'); -- not null이 설정된 컬럼을 제외하고는 생략하고 삽입 가능합니다. insert into tCity(name, area,metro,region) values('양천구',60,'y', '서울'); -- 한꺼번에 삽입도 가능합니다. insert into tCity(name, area, popu, metro, region) values("문래동", 90, 20, 'y', '서울'),('목동',230,29,'y', '서울'); select * from tCity;
데이터 삭제
기본 형식
delete from 테이블이름 [where 조건];
- where절을 생략하면 테이블의 모든 데이터를 삭제합니다.
delete from tCity where name in("구로","목동","문래동","양천구","영등포"); select * from tCity;where에 조건을 잘 써서 효과적으로 삭제를 하자.
데이터 갱신
기본 형식
update 테이블이름 set 컬럼이름=수정할 내용, ...[where 조건]
- where절을 생략하면 테이블의 모든 데이터를 수정합니다.
-- tCity 테이블에서 name이 마산인 데이터의 popu를 40으로 수정하기 -- 단 조건문이 안맞으면 업데이트를 제대로 하지 못한다. 에러는 안나네? update tCity set popu=40 where name='마산'; select * from tCity;
✔ TCL (Transaction Control Language)
Transaction
개념
- 논리적으로 한 번에 이루어져야 하는 작업의 단위
성질
- Atomicity
- All or Nothing (전부 아니면 전무) - Consistency
- 트랜잭션 수행 전과 수행 후의 결과가 일관성 있어야 한다. - Isolation
- 트랜잭션 작업 중 다른 트랜잭션이 사용중인 데이터에 접근해선 안된다. - Durability
- 한 번 완료된 트랜잭션은 계속 되어야 한다.
동작
DB 작업은 원본에 하는 것이 아니다. 복사본 (세션)에서 작업합니다.
복사본에서 작업하고 저장(Commit)해서 원본에 영향을 줄건지 고민해야 합니다.
해당 작업을 하다 나가면 "세션"이 끊어졌습니다. 라고 합니다. 세션은 문자열 키를 사용자에게 다 주고 연결을 합니다. 세션이 끊어졌다는 것은 해당 키가 없어졌다는 것입니다.
- Commit : 작업 내역을 원본에 반영
- 원본에 덮어 씌우기 - Rollback : 작업 내역을 원본에 반영하지 않는 것
- 작업한거 원본에 안덮어 씌우고 나가기
생각해보기
- DB에서 물리적인 단위 : SQL 문장 1개
- 물리적인 단위가 뭐야? insert into 이름 values(값)
- 실행되는 단위인가 - 논리적인 단위 : Transaction
- SQL과는 상관없이 한 번에 이루어져야 하는 작업
ex) UserA가 UserB에게 item을 500gold에 판매하려 한다.
- 물리적 단위
- a에서는 item에 대한 update가 필요함
- b에서 item에 대한 update가 필요함
- b에서 gold가 update 되어야 함.
- a도 gold가 update 되어야 함.- 논리적 단위는
- 저 4개의 작업을 합친 것이다. (한번에 되어야 하기 때문이다.)
- 해당 작업은 전부 되어야 하거나 아예 안되어야 한다.(Atomicity)
- 내가 생각했던것과 결과가 같아야 한다.(consistency)
- 만약 b가 500gold가 있는데 a랑 c에게 동시에 item을 구매하는 경우가 생길 수 있음. 이를 막아야 함(Isolation)
- 한 transaction이 끝나면 해당 transaction을 다시 작업하는게 아닌 새로운 transaction을 작업을 해야 한다. (Durability)
Transaction 관련 명령어
Commit: 현재까지 작업 내역을 원복에 반영Rollback [to 세이브포인트이름]: 세이브포인트 자리로 작업을 이동
- 세이브포인트 작성을 안하면, 트랜잭션 생성한 위치로 이동savepoint 이름: 세이브포인트 생성
Transaction 생성 시점
- transaction이 없는 시점에 DML(insert, delete, update)문장을 처음 실행할 때
Transaction 종료 시점
- COMMIT 이나 ROLLBACK이 수행되면 TRANSACTION은 자동 종료
COMMIT 하는 방법
- 명시적으로 COMMIT 명령을 수행
- DDL이나 DCL문장을 수행 : ATUO COMMIT
- 접속 프로그램 정상종료
Rollback 하는 방법
- 명시적으로 ROLLBACK 명령을 수행
- 접속 프로그램을 비정상 종료(우리가 종료하는 것이 아님)
- 특수한 사항이 발생해서 비정상적으로 종료될 때
Transaction 모드
- MANUAL COMMIT : Transaction 동작을 직접 조작
- ATUO COMMIT : 하나의 SQL을 수행하면 바로 COMMIT이 이루어지는 것
- java, DBeaver는 기본적으로 atuo commit
-
COMMIT 할 때는 LOCK 걸려서 다른 작업을 못합니다.
- 그래서 COMMIT 을 하면 속도가 느립니다. -
하나의 테이블에서 두개 이상의 쓰기 작업을 못합니다.
- 한 작업이 Insert, delete, update 하면 다른 작업은 앞선 작업이 COMMIT 하기 전까지는 select만 가능합니다.
- 안그러면 작업한 데이터가 삭제됩니다.
- ex) python - dbeaver 연동 후, python 에서 작업하고 commit 안하고 dbeaver에서 작업하려 하면 계속 돌아가서 작업이 안될 것이다.
- 그래서 dbeaver가 atuo commit 모드를 만들어 둔거에요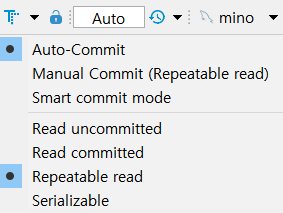
-
Transaction 공부할 땐, Manual Commit으로 설정하자.

글 잘 봤습니다, 많은 도움이 되었습니다.