
✔ DB 개요 맛보기(정리해서 다시 쓰기)
컴퓨터에서 일을 하는 프로세서(CPU, GPU)는 데이터를 메인 메모리에서만 가져올 수 있지만, 메인메모리는 가격이 비싸며 휘발성이라는 문제가 존재한다.
이에 대한 대안은?
휘발성 -> 보조기억장치(Auxiliary Memory), 좋긴 하지만 메인메모리가 가져오고 그걸 프로세서가 쓰는거라서 속도가 엄청 빠르진 않다.
Flat File(txt,csv)로 저장(보조기억)
파일은 무조건 위에서부터 순서대로 읽어야 합니다.(조금 느리다. 인덱스를 설정할 수 없기 때문이다.)
-> 그럼 데이터에다 인덱스를 설정해서 좀 해보면 어떨까?
--> index를 설정한 파일을 만들자.
---> 단순히 인덱스만 두지 말고 구조를 분리시켜보자.(검색이 뛰어난)
-----> 이게 Database이다.
(근데 인덱스는 결국 포인터이기때문에 비용이 발생한다.)
(근데 이런 db를 엑셀처럼 해보면 편하지 않을까 해서 rdbms(table구조, SQL)을 만들었음
-> 내 컴퓨터를 포맷하면 데이터가 날아가는데??
---> 데이터를 다른 곳에 두자.
-----> 네트워크를 사용하자(local 말고 network)
NoSQL (SQL이 아닌 function 베이스인)을 만들었다.
-> db를 따로 만들었더니 개발자들이 너무 힘들어, 질의를 던지는 것을 function 형태로 만들어보자. SQL은 모델링이 매우 강하지만 NoSQL은 그게 아니다.
네트워크를 타면서 "분산파일시스템" 이 생겨남(하지만 나눠서 저장하는건 아님), 컴퓨터 한대에다 다 떄려박기가 힘들다.
-> 데이터를 분산 저장하는 것을 배웠음
-> 분산 : 처리를 생각해야해 -> 이때 나온 것이 hadoop입니다.
아니 rdbms, nosql싹 공부하니 hadoop이 나왔네// 언제하냐.. 했는데 하둡 에코시스템은 db에 옮겨서 할 수 있게 했다.
(hive->NoSQL로 보내고 RDBMS로 보내는 것도 있다.)
아마존 RDS라는 서비스도 존재한다. 설치도와주는 친구
백업 자체도 말이 안된다-> IDC(data center)를 이용하자.
이제 시간이 지나서 mainmemory램의 가격이 이전 대비 떨어진다. 이제 여기에도 db를 두자. -> in memory db(ex : radis)
-> 약간 비싸긴 하고, 많은 양의 데이터를 넣기엔 부담이긴 하지만, 변수를 쓰듯이 빠르게 쓸 수 있다.
-> 부담을 제거하기 위해서 programming으로 인메모리db처럼 해보겠어 한 것이 ORM 이다.
-> python 웹프밍 방식 (2가지면, 프레임워크 이용 or 직접짜기)
-> 프레임워크 (플라스크, 장고) 고르기
-> 플라스크는 자유도가 높다. 하지만 다 따로 설치를 해야한다.
-> 장고는 orm 설치되어있다. 자유도가 낮다. 편하다.
우리가 flat file은 해봤으니 Db를 해봐야겠지. RDBMS가 먼저 나와서 대중화 되어있으니 얘를 해보자. MySQL!
MySQL설치? : 데이터 저장소 하나를 마련한 것이다.
-> 여기에 실제로 sql을 보내서 작업해야함
-> db 접속도구 혹은 application을 개발해서 해야 함.
-> db 접속도구는 ui 손댈 수 없고
-> 개발한거면 ui를 마음대로 할 수 있다.
-> 접속 도구 중 사용할 것은 dbeaver이다.
-> 금융은 오렌지나 토드, 오라클은 sqldeveloper, ..
-> 우린 db 2,3가지 써봐야 하기에 다 가능한 dbeaver를 쓰는거야!
data store랑 접속도구 간 해석(interface)을 도와주는 것이 필요한다.
Driver : application 과 databse의 인터페이스
4가지 정보가 필요함
정보 : db 종류, URL(위치), 계정(account, id), 비밀번호(pwd) 총 4 가지 정보가 필요한 것이다.
db는 mysql, 내컴퓨터(localhost), db이름 user 이름, user비밀번호
모든 db는 시스템 계정이 존재하며, 관리자는 local에서만 접속해야 한다.(외부 접근 금지, 보안을 위해서)
authentication(인증) - 신원검증
autherization(인가) - 어떤 권한까지?
db종류
db: mysql
포트번호 : 컴퓨터 안에서 프로그램을 구분해준다.
뒤에mysql : mysql 자체 포트번호
앞에mysql : 외부에서 사용할 때 쓰는 번호
sample 데이터 설치해봐야겠다!
-> 일반적인 개발에서는 5개를 본다.
DDL, DML, DCL
(definition) 정의 : create, alter, drop, (rename, truncate)
--> 설계의 영역
(manpulation) 조작
-> insert, update, delete
-> select (조회, 데이터의 변경을 가하지 않음, 분리를 시키자 : DQL)
-> 이 부분이 개발자나 사용자의 영역이다.
(Control) 제어
-> grant, revoke(권한 부여, 회수) : 전통적, 관리의 영역
-> commit, rollback(작업 완료, 처리 : TCL(트랜잭션 제어, 관리의 영역이 아닌 개발의 영역이다.))
CQRS : 조회랑 조작은 따로 있어야 하니 개발 때 부터 아예 따로 만들어라. (분리시키자.)
✔ Docker에서 MySQL 실행
이미지 다운로드 및 실행
docker run --name mysql -dit -e MYSQL_ROOT_PASSWORD= 관리자비밀번호 -e MYSQL_DATABASE=데이터베이스이름 -e MYSQL_USER= 사용자이름 -e MYSQL_PASSWORD= 사용자비밀번호 -p 3306:3306 mysql --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci --default-authentication-plugin=mysql_native_password코드상 \n을 한 것은 다 없애주자.
collation-server : 정렬순서
--character-set-server=utf8mb4 : 한국어도 가능하게 utf8하고 mb4는 이모지 사용 가능하도록
--default-authentication-plugin=mysql_native_password 이중화가 아닌 이전 버전처럼 비밀번호 입력하면 되되록 하자.
- 이미지만 존재하는 경우는 명령어를 다시 실행
- 이미지와 컨테이너가 존재하는 겨웅에는 컨테이너만 실행
- 이미지는 프로그램이에요
DBeaver에서 MySQL 접속
- [파일]-[새로 만들기] 선택 후, DBeaver 탭에서 [데이터베이스 연결] 선택 후 next , [원하는 언어] 선택
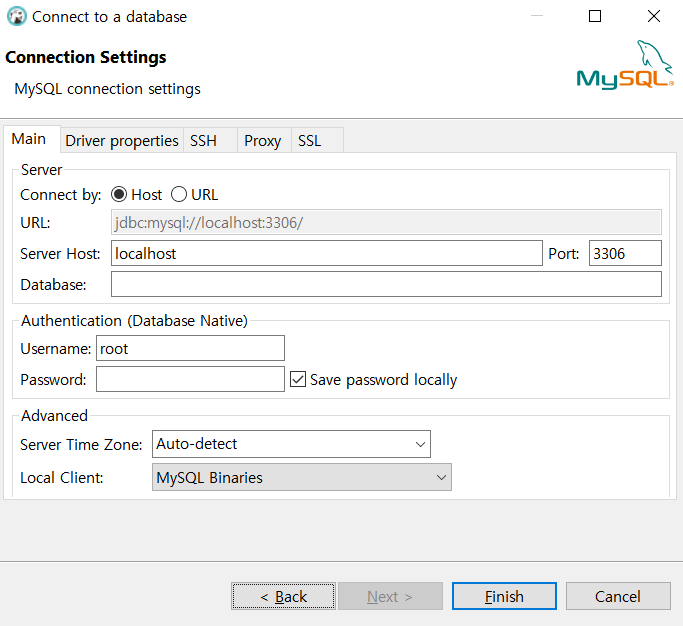
- server host : db가 위치한 컴퓨터의 ip
- 자신의 컴퓨터는 localhost - port 번호 설정 : 기본은 mysql은 3306 처음 컨테이너 설치할때랑 맞아야겠지?
- database : db 이름
- Username: 유저의 id
- Password : 유저의pwd
- 컨테이너 설치 명령에서 한 것 처럼 해보자.
만들어진 Connection을 선택하고 마우스 우클릭으로 연결을 누르자.
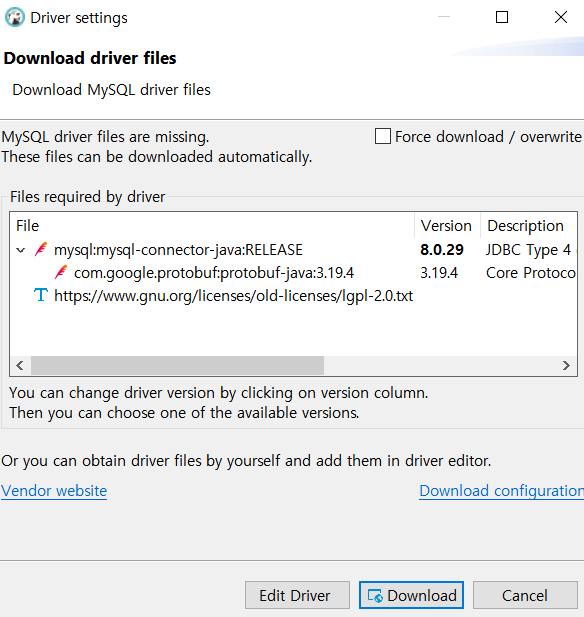
- 연결을 하려고 하니, 드라이버를 받아야 한다고 한다.
- 다운로드 버튼을 누르자
- 연결이 잘 된다면 연결 버튼이 비활성화 된 것이다.

- 새 sql 편집기 쓰면 sql 쓸 수 있는 창이 생긴다.

- sql실행은 한줄만
- sql 스크립트는 전부다 : 그래서 블럭을 잡고 실행시키는게 좋다.
DBeaver에서 명령 수행
- ctrl+enter : 커서 위치의 하나 명령어 실행
- 마우스 우클릭 sql문 실행과 같은 효과 - 마우스 우클릭 + [sql 스크립트 실행]
- 블럭을 한 경우는 블럭 안의 모든 구문 실행
- 블럭을 하지 않은 경우에는 모든 구문 실행
✔ DB
db 관련 명령
- db 목록 보기
show databases; - db 생성
create database 이름; - db 삭제
drop database 이름; - db 사용
use db이름; - table 목록 보기
show tables;
MySQL의 작업단위는 Database>Table 이다.
Oracle은 SID(Service Name)>User>Table 이다.
Oracle은 user별 데이터 공유가 안된다.
테이블 구조
- 테이블 구조 확인 명령 :
DESC 테이블이름; - 오라클에서는 sqlplus로 접속했을 때 만 가능
- 그럼 오라클 샘플과 비슷한 예제를 확인해보자.
EMP Table - 사원 테이블
- EMPNO - 사원번호, 정수 4자리, Primary Key
- Primary Key : Not Null, Unique, 테이블에 1개씩만 존재- ENAME - 이름, 문자
- JOB - 직무, 문자
- MGR - 관리자 사원번호, 정수 4자리
- HIREDATE - 입사일, DATE
- SQL - 급여, 실수이고 소수 2자리
- COMM - 상여금, 실수이고 소수 2자리(NULL 포함)
- DEPTNO - 부서번호, 정수 2자리, DEPT 테이블의 DEPTNO를 참조
- Foreign Key
DEPT Talbe - 부서 테이블
- DEPTNO - 부서번호, 정수 2자리, Primary Key
- DNAME - 부서이름, 문자
- LOC - 위치, 문자
EMP, DEPT 테이블은 DEPTNO로 연결되어있다.
SALGRADE Table - 호봉 테이블
- GRADE - 호봉, 숫자, Primary Key
- LOSAL - 호봉의 최소 급여, 정수
- HISAL - 호봉의 최대 급여, 정수
tCity Table - 도시 테이블
- NAME - 도시이름, 문자, Primary Key
- AREA - 면적, 정수
- POPU - 인구, 정수
- METRO - 대도시 여부, 문자
- REGION - 도, 문자
tStaff Table - 직원 테이블
- NAME - 이름, 문자, Primary Key
- DEPART - 부서이름, 문자
- GENDER - 성별, 문자
- JOINDATE - 입사일, 날짜
- GRADE - 직무, 문자열
- SALARY - 급여, 정수
- SCORE - 고과 점수, 실수, 소수 2자리
✔ SQL 작성 방법
- 예약어는 대소문자 구분을 하지 않음
- 하나의 명령문 끝은 ; 이다.
- 명령문의 끝은 ; 이지만, 접속도구를 사용하거나 응용 프로그램을 직접 작성할 때는 ;을 생략 가능함 - 프로그래밍 언어에서는 ; 이 하나의 명령문은 끝을 의미하기 때문에 ; 을 포함하면 에러가 발생함
SQL 종류
- DQL(Select) : 조회
- DDL(Definition) : 데이터 구조, 관련 명령
- create, alter, drop, truncate, rename - DML(Manipulation) : 데이터 조작 관련 명령
- inset, update, delete - TCL(Transaction) : 트랜잭션 조작 명령
- DML과 관련이 있다.
- commit, rollback, savepoint - DCL(Control) : 데이터 제어 명령
- grant, revoke
Select
- 기본 구조
5select 1from 2where 3group by 4having 6order by앞에 순서가 작동 순서이다.
실행순서와 작동순서가 다르다.(비 절차적)
- from : 조회할 테이블 이름 나열(필수)
- where : 검색 조건 - 행을 분할
- group by : 그룹화
- having : 그룹화 한 이후의 조건
- select : 조회할 열 - 열을 분할(필수)
- order by : 정렬 조건
mysql(maria db에도 존재) 같은 경우에는 마지막에 limit을 사용하는 것이 가능
sql 튜닝 : 먼저 걸러내라
테이블의 모든 데이터 조회
select * from 테이블이름;
특정 컬럼의 데이터를 조회
select 컬럼 이름 나열(, 로 구분하면서 나열) from 테이블 이름
- MySQL의 경우는 테이블 이름은 대소문자를 구분하고 컬럼 이름은 대소문자를 구분하지 않음
- Oracle의 경우는 테이블이름 과 컬럼 이름 모두 대소문자를 구분하지 않음
컬럼 이름에 별명 사용
- 컬럼 이름 다음에 as를 추가하고 문자열을 삽입하면, 컬럼 이름에 별명이 부여되서 출력될 때, 컬럼 이름 대신에 별명이 출력됩니다.
- 별명에 영문 대문자, 공백이 있다면
" "로 감싸줘야 합니다. - 물론 as는 생략이 가능합니다.
컬럼에 연산식 출력이 가능
+,-,*,/를 이용해서 컬럼에 연산을 수행한 후, 출력이 가능합니다.- 컬럼 이름은 연산식이 되기 때문에, 대부분 별명을 이용해서 출력
- 실제 컬럼이 만들어 지는 것이 아니고, 내부적 연산을 통해 출력 만 하는 것이다.
- select 절에 단순 연산식이 가능한데 MySQL에서는 from 생략이 가능함 Oracle은 아님.(from dual)
컬럼 연결 조회
concat함수 이용
- 이 함수의 역할은 2개의 데이터를 하나로 묶어주는 것
중복 제거
distinct함수를 이용함
- select 바로 뒤에 한 번만 기재해서 컬럼의 중복 값을 제거하고 출력- distinct 뒤에 컬럼 이름이 1개인 경우는 그 컬럼의 값이 동일한 경우만 제거, 2개 이상이 나오는 경우는 모든 컬럼의 값이 동일해야만 제거됨
group by를 이용해서도 작성이 가능함
-- tCity 에서 region값을 조회하고 싶어 // 중복없이 보고싶어 select DISTINCT region from tCity; select region from tCity group by region; -- group by 는 동일한거 묶는거여서 되는거야 -- 해당 결과의 CARDINALITY 는 5, DEGREE 는 1이다. -- 두 개 이상을 검색하려면 둘 다 같아야지 중복으로 본다. select DISTINCT region, name from tCity;
SORT - 정렬
- 정렬의 종류
- Ascending : 오름차순(작은 것에서 큰 순으로 나열, Default)
- Descending : 내림차순(큰 것에서 작은 것 순으로 나열, 지정필수) - 정렬을 수행하는 위치에 따라서 내부 정렬과 외부 정렬로 나누기도 함
- 내,외부의 기준은 메모리이다.
- 정렬을 할 때, 수행하는 알고리즘의 방식에 따라 분류하기도 합니다. - 오름차순
- 숫자나 문자, 날짜는 작은 것에서 큰 순으로, NULL은 가장 나중 - 내림차순은 반대로
- SQL에서 정렬
-ORDER BY 컬럼이름 (ASC)|DESC - 컬럼 이름 대신에 SELECT 절에서 만든 별명도 사용이 가능하고, 인덱스를 이용해서도 가능
- select 절에서 조회하는 순서인데, 첫번째는 1이다. - 연산식으로 정렬하는 것도 가능
- 2개 이상의 정렬 조건을 기재할 수 있는데, 이 경우는 앞의 정렬 조건이 같은 값일 때, 뒤의 조건이 적용
- select를 할 때, 2개 이상의 행이 리턴되면
ORDER BY를 해주는 것이 좋다.
- 하지 않아도 에러는 아니지만, 데이터가 어떤 순서로 출력되는지 알 수 없기 때문이다.
- Oracle 경우 : 입력순서를 기억해서 그대로 리턴
- SQL server와 MySQL(Maria DB)는 Primary key 순서대로 리턴
-- tCity 에서 region, name, area, popu 조회하는데, -- region 오름차순 조회 select region, name, area, popu from tCity order by region; -- tCity 에서 region, name, area, popu 조회하는데, -- region 오름차순 조회이지만 동일한 값이면 area가 큰 것이 먼저 select region, name, area, popu from tCity order by region asc, area DESC ; select region as "지역", name as "이름", area, popu from tCity order by 지역 asc, 3 DESC ;오른차순 asc는 생략 가능합니다. 내림차순은 desc 붙여야 합니다. 그리고 컬럼 순서를 별명, 이름 대신해서 쓸 수 있따.
where
- 테이블의 데이터를 selection 하는 절
- selection : 행을 선택하는
- select 절은 projection(열을 선택하는) 절 - 조건을 기재해서 조건에 맞는 데이터를 골라내는 것
- 기본 연산자
>, >=, <, <= ,=, != ,<>, ^=, not 컬럼이름 연산자 값
- 값을 표기할 떄는 숫자는 그냥 표기하면 되지만, 문자열과 날짜는 '' 안에 기재
- mariaDB나 MySQL은 "" 안에 기재해도 되며, 대소문자 구분 X
- 하지만 저장할 때는 구분함 - 대소문자를 구분해서 조회하고자 하는 방법
- 테이블을 만들 때,varchar대신varbinary를 이용(만들기 전)
- 테이블을 만들 때,varchar를 이용하면 뒤에binary를 추가해서 생성(위에보단 이것을 권장, 만들기전)
- 테이블이 이미 만들어진 경우는, 조회를 할 때COLLATE utf8_bin을 추가(만든 후)
- 컬럼이름을binary로 감싸서 조회(만든 후)
null 조회
- null 은 데이터가 존재하지 않거나 아직 알려지지 않은 값
- null인 데이터나 null이 아닌 데이터를 조회할 때,
=null이나!=null은 사용할 수 없음
- 문법적으로 에러는 아니지만 데이터 조회는 안됨 - 최근에 등장한 프로그래밍 언어나 DB는 NULL을 저장하는 방법이 기존 방식과는 다름
- DB에서는 NULL 조회할 때,is NULLis not NULL을 사용합니다.
-- tStaff 테이블에서 score null인모든 컬럼 조회 select * from tStaff where score is null;
논리연산자
- NOT : 결과를 반대로
- AND : 그리고
- OR : 또는
- AND가 OR보다 우선순위가 높다.
-- tCity 테이플에서 popu가 100이상이고 area가 700 이상인 데이터 조회 -- and나 or에서 조건의 순서는 결과에 영향을 미치지 않고, 과정에 영향을 미친다. select * from tCity where POPU>=100; -- 2개 데이터 select * from tCity where AREA>=700;-- 5개 데이터 select * from tCity where POPU>=100 and AREA>=700; -- 2개 데이터 고르고 뒤의 조건 확인 -- tStaff 테이블에서 salary 가 300미만이거나 score가 60이상인 직원의 모든 컬럼 조회 select * from tStaff where salary <300; -- 5개 데이터 select * from tStaff where score >=60; -- 10개 데이터 select * from tStaff where score >=60 or salary <300; -- 10개 데이터 고른 뒤 5개 데이터 보기DON'T CARE 조건을 여기서도 생각 할 수 있다.
LIKE
- 부분 일치하는 문자열을 찾을 때 사용(날짜도 가능함)
- 와일드 카드 문자
- % : 글자 수 와 상관이 없이
- _ : 딱 한 글자
-%a:aaa, bba, a, ba도 가능함 즉, a로 끝나는
-_a:ba,ca는 가능하지만aaa, bba불가능
-[글자열]: 나열된 글자 중 하나 (표준 x)
-[^글자열]: 나열된 글자가 아닌 (표준x)
NOT LIKE
- LIKE가 아닌
와일드카드 문자를 검색하고자 하는 경우는 ESCAPE를 이용
-- tCity 테이블에서 name에 천이 포한됨 모든 데이터 조회 select * from tCity where name like'%천%'; -- EMP 테이블에서 ename에 L이 2개 포함된 데이터를 조회 select * from EMP where ENAME like '%L%L%'; -- sale에 30%가 포함된 데이터를 조회 -- select * from ~~ where sale like '%30#%%' ESCAPE '#' ; #뒤에 나오는 것은 일반 문자로 취급 -- tStaff 테이블에서 joindate(입사일)가 10월인 사원을 조회 select * from tStaff where joindate like '%-10-%';
between
>=A AND <=B의미를 가지고 있다.between A and B로 사용하며, 순서를 바꾸면 안된다.
- a, b 바꾸면 데이터 하나도 안나오겠네
- 명시적으로 많이 씀
- 쇼핑몰 얼마부터 얼마까지- DB에서는 문자열과 날짜도 크기비교가 가능하다.
- DB에서는 날짜가 1이다.
-- tCity table에서 popu가 50에서 100사이인 데이터 조회
select * from tCity where popu >=50 and popu<= 100;
select * from tCity where popu BETWEEN 50 and 100;
-- tStaff table에서 joindate 가 2018인 데이터 조회
select * from tStaff where joindate like '2018-%';
select * from tStaff where joindate BETWEEN
'2018-01-01' and '2018-12-31';in
in(데이터 나열)형태로 작성하는데, 데이터에 포함된 데이터를 조회NOT IN(데이터 나열)은 데이터에 포함되지 않은 데이터 조회
행의 개수 제한(표준은 아님)
- ORACLE 에서는
ROWNUM이나INLINE VIEW또는FETCH~OFFSET - MS-SQL SERVER는
TOP을 이용 - MySQL(MariaDB)에서는 SELECT 구문의 마지막에
LIMIT으로 제한
-LIMIT [건너뛸 개수,] 조회할 개수
- 건너뛸 개수를 생략하면 0
-LIMIT 조회할 개수 OFFSET 건너뛸 개수형태로 입력 가능(권장)
- 이 구문은 TOP-N이라고 부르기 때문에ORDER BY와 같이 사용됨
Scala Function
- 데이터베이스에서의 함수
- Maker Function과 User Define Function으로 나눌 수 있음
- Maker Function의 분류
- Scala Function : 행 단위로 연산
- Group Function : 그룹화해서 연산
- System Function : 데이터와 상관없이 수행되는 연산 - Scala Function은 일반적으로 SELECT 절이나 WHERE절 또는 ORDER BY에도 사용이 가능함
- 수치 함수
ABS
ROUND(데이터, 반올림할 자릿수 설정) : 음수 이용하면 0자리부터 위로감
TRUNCATE
CEILING, FLOOR
MOD(나머지)
- 문자열 함수
ASCII(문자), CHAR(숫자) : 문자와 코드 값 변환
BIT_LENGTH, CHAR_LENGTH, LENGTH : 길이
select CHAR_LENGTH("문자열"), LENGTH("문자열");
char_length : 진짜 길이
length : 바이트 단위 길이 (한글은 3, 영어는 1)
bit : 8bits -> 1byte 그러니 *8하면 되겠지
UPPER, LOWER : 영문 대소문자 변환
LTRIM, RTRIM : 좌, 우 공백 제거
TRIM : 양쪽 공백 제거
REPLACE(문자열, 원래 문자열, 변경할 문자열) : 문자열 변경
SUBSTRING(문자열, 시작위치, 자를 개수) : 문자열 자르기
CONCAT(문자열 나열) : 문자열을 하나로 결합
-- EMP table에서 HIREDATE가 1981년인 데이터 조회 select * from EMP where HIREDATE like '1981%'; select * from EMP where SUBSTRING(HIREDATE,1,4)='1981'; -- EMP table에서 ENAME이 E로 끝나는 사원 정보를 조회 select * from EMP where ENAME like '%E'; select * from EMP where SUBSTRING(ENAME, -1, 1) ='E'; select * from EMP where SUBSTRING(ENAME, CHAR_LENGTH(ENAME),1) ='E'; -- 만약 ENAME에 한글이름이 있었따면 char_length이용, 영어면 같으니 length 가능 select LENGTH(ENAME) from EMP; select CHAR_LENGTH(ENAME) from EMP;
- 날짜 관련 함수
- DB에서는 날짜를 숫자로 취급합니다.
- 날짜와 날짜 그리고 날짜와 정수 사이 연산이 가능합니다.
- 하루를 1로 간주합니다.
- 현재 날짜 및 시간
- CURRENT_DATE(), CURDATE() : 현재 날짜
- CURRENT_TIME(), CURTIME() : 현재 시간
- NOW(), LOCALTIME(), LOCALTIMESTAMP(), CURRENT_TIMESTAMP() : 현재 날짜 및 시간 (timestamp가 들어간 것이 더 정확함 1/1000초, 1/1000000초였나..)
- 날짜 및 시간 추출 함수
- YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, MICROSECOND
- 날짜 및 시간 계산 함수
- ADDDATE(날짜, 차이), SUBDATE(날짜, 차이)
- ADDTIME(날짜, 차이), SUBTIME(날짜, 차이)
- DATEDIFF(날짜1, 날짜2), TIMEDIFF(날짜1, 날짜2)
- 특정 날짜 생성
- STR_TO_DATE(날짜 문자열, 서식)- 날짜에 특정 기간을 추가
- 날짜 + INTERVAL 값 단위
✔ SQL 파일을 DBeaver에서 실행
- SQL 파일을 DBeaver에서 열기
- users\user\appdata\local에 있음
- 열고나서 SQL 편집기 메뉴에서 활성화된 DB 연결을 누르고 DB와 SQL 파일을 연결
- SQL을 작업할 떄는 SQL 파일이나 문서 편집기에 작성한 후 옮기면서 실행해야 합니다.

저도 개발자인데 같이 교류 많이 해봐요 ㅎㅎ! 서로 화이팅합시다!