CS224W 5강 - Message Passing and Node Classification
본격적으로 deep encoding해서 graph/node embedding을 생성하는 GNN 파트에 앞서 GNN을 이해하는데 직관적으로 도움이 되는 중간 토픽을 다룸.
- Message Passing
- Task: Semi-supervised "Collective" Node Classification
(Collective Classification: Iteratively reclassify nodes altogether until convergence) - Idea: 그래프에 존재하는 Correlation을 활용
- Homophily: 개인 집단
- Influence: 집단 개인
- 종류
- Relational Classification
- Potential-type: Homophily
- 그래프 구조 + 이웃 노드의 labels
- 원리: 1) 노드 class 확률 초기화 2) 랜덤 순서로 노드의 class 확률 업데이트 (이웃 노드 확률의 가중평균) 3) 수렴까지/ fixed iteration까지 반복
- 수렴이 보장되지 않음
- Iterative Classification
- Potential-type: Homophily
- 그래프 구조 + 이웃 노드의 labels + 자신 그리고 이웃 노드의 attributes
- 원리:
- Train
- : 노드 attribute만 활용하여 label classification 학습
- : 노드 attribute + 이웃 노드 label summary vector을 활용하여 label classifcation 학습
- Test: 학습된 , 를 기반으로
- 1단계: 을 사용해서 노드 attribute 기반 initial label을 얻음
- 2단계: 1단계에서 얻은 initial label을 활용하여 label summary vector 업데이트
- 3단계: 를 사용해서 노드 attribute & 2단계에서 업데이트된 label summary vector을 활용하여 node label을 업데이트
- 수렴까지/ fixed iteration까지 반복
- Train
- 수렴이 보장되지 않음
- Questions
- Train dataset은 모두 ground truth label이 존재하는가? 그렇지 않다면 label이 존재하는 노드들만 가지고 summary vector을 만드는가? 그리고 test dataset은 모두 ground truth label이 존재하지 않는가? 만약 일부가 존재한다면 존재하지 않는 노드만 label classification하는 것인가?
- Belief Propagation
- Potential-type: Homophily 뿐만 아니라, 더 복잡한 노드간 상관관계 패턴도 고려할 수 있음
- Message passing 기반: = "Each neighbor passes a message to its beliefs of the state of "
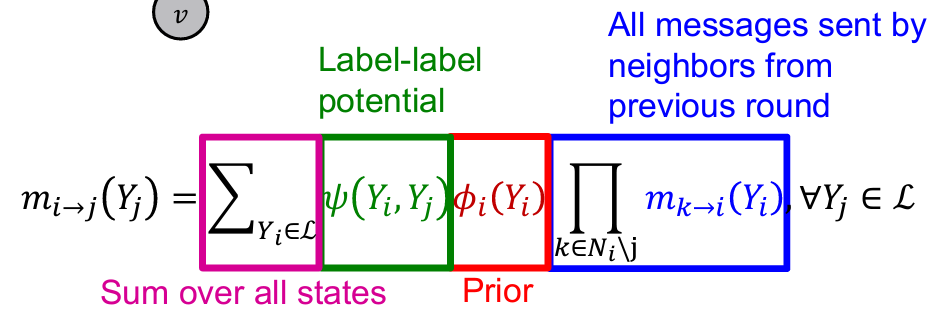
- : Source 노드가 클래스에 속할때 target 노드가 에 속할 확률을 나타내는 행렬 만약 homophily가 존재한다면 행렬의 대각선 값이 클 것임
- : 노드가 클래스에 속할 근원적인(?) 확률
- : 모든 label class의 집합
- All messages sent by neighbors from previous round: "Belief"
- 수렴 후,
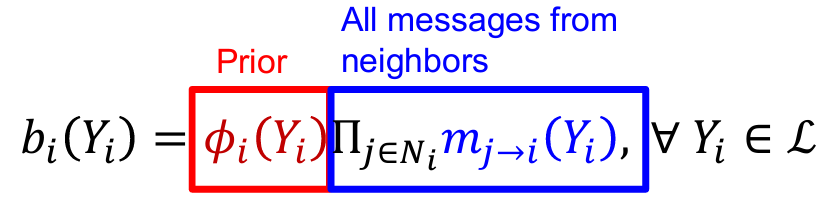
- 수렴이 보장되지 않음, 특히 closed-loop가 많은 그래프에서
- Questions
- 학습의 대상이 되는 것이 label-label potential이고 prior은 고정된 초기 확률값인가? Source 노드가 클래스에 속할 확률이 이전 라운드에 i에 in-link가 있는 노드들이 전달한 메세지 총곱으로 해서 0-1(?) 사이의 값이 되고 이를 prior에 곱해서 결국 source 노드가 클래스일 확률이 되는건가? 즉 메세지가 0-1 사이 값인가??? 그럼 곱하면 더 작아지잖아...?
- Relational Classification
- Task: Semi-supervised "Collective" Node Classification
