CS224W 2강 - Traditional Methods for Machine Learning in Graphs
- Traditional ML pipeline uses hand-designed features
각 node / link/ graph마다 structural / attribute feature가 존재하지만, 본 강에서는 structural feature에만 집중한다. - Traditional ML Pipeline = Hand-crafted feature + ML model
-
Node-level Features: Characterize the structure and position of a node in the network
-
Node degree [Structure-based features]
-
Node centrality [Importance-based features]: 이웃 노드를 셀 때, 각 노드의 중요도도 함께 고려하는 방법
중요도란?- Eigenvector centrality: 중요한 노드와 많이 연결된 노드가 더 중요하다.
나중에 PageRank와 연관되니 잘 알아두기!
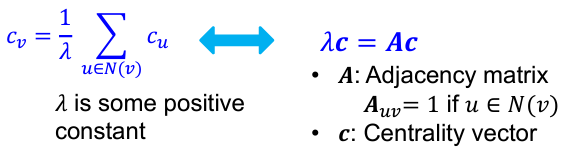 재귀 수식을 matrix form으로 다시 쓰면 다음과 같다.
재귀 수식을 matrix form으로 다시 쓰면 다음과 같다.
여기서 C는 인접행렬 A의 eigenvector, 는 A의 eigenvalue이다.
따라서, 인접행렬을 가지고 적절한 값에 대한 eigenvector을 계산하면 이것이 중심성을 나타내는데 쓰일 수 있다. - Betweenness centrality: 어느 한 노드가 좋은 transit 노드라면, 즉 교통의 중심지라면 중요하다. 다른 말로, 많은 다른 노드 간 최단 경로에 등장하는 노드가 더 중요하다.

- Closeness centrality: 다른 모든 노드와의 최단 경로 길이의 합이 가장 작은 노드일수록 중심에 위치한 노드일 확률이 크고, 고로 더 중요하다.
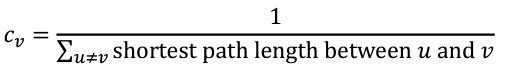
- Eigenvector centrality: 중요한 노드와 많이 연결된 노드가 더 중요하다.
-
Clustering coefficient [Structure-based features]
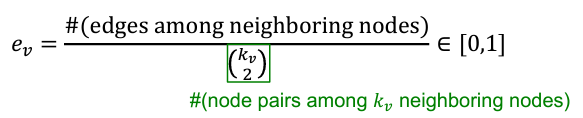
사실은 삼각형의 갯수를 세는 것! -
Graphlets [Structure-based features] 삼각형 말고, 미리 정의된 subgraph 형태의 갯수를 세는 것!
그 pre-defined subgraphs를 'Graphlets'이라고 한다.
Graphlet Degree Vector(GDV)을 node feature로 사용함. "Rooted at that node"
-
-
Link-level Features: Design features for a pair of nodes
-
Distance-based feature: 두 노드간 최단 경로의 길이
단점: neighborhood overlap의 정보는 사용되지 않음 -
Local neighborhood overlap: 두 노드 사이에 공유되는 이웃 노드의 갯수
 cf. Adamic-Adar index: high deg의 common neighborhood이 많은 것보다 low deg의 common neighborhood이 많은 것을 더 크게 쳐줌
cf. Adamic-Adar index: high deg의 common neighborhood이 많은 것보다 low deg의 common neighborhood이 많은 것을 더 크게 쳐줌
단점: 2-hop만 고려 -
Global neighborhood overlap: 전체 그래프를 고려함으로써 local neighborhood overlap의 단점을 극복
Katz Index: # of paths of all lengths btw two nodes (인접행렬의 n제곱으로 구함)

-
-
Graph-level Features: Design kernels instead of feature vectors
Kernel measures similarity between data- Graphlet Kernel: Bag-of-Graphlets로 feature vector 만들고, kernel 계산
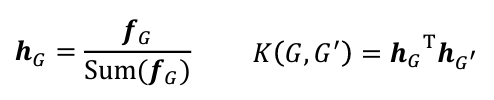 단점: graphlet counting은 expensive! efficiency
단점: graphlet counting은 expensive! efficiency - Weisfeiler-Lehman Kernel: Bag-of-Colors
[Color Refinement]: After K steps of color refinement, the structure of K-hop neighborhood is summarized
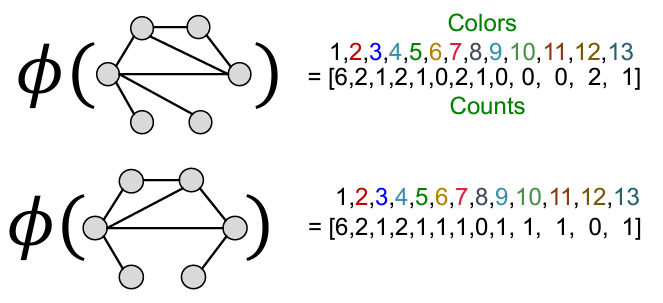
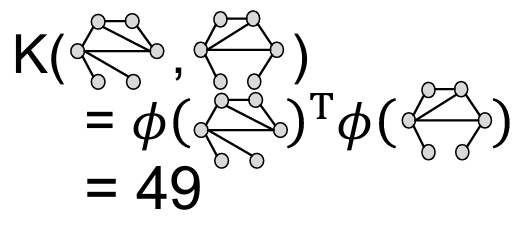
장점: efficient, 전체 시간 복잡도 O(# of edges)
나중에 GNN과 연관되니 잘 알아두기!
- Graphlet Kernel: Bag-of-Graphlets로 feature vector 만들고, kernel 계산
