NerveNet: Learning Structured Policy with Graph Neural Networks
-
풀고자 하는 task: Continous control (Locomotion control 포함) Infinite-horizon discounted MDP
(Infinite-horizon: 각 episode에 대한 time step이 무한할 수 있음) -
Model-free RL: Agent가 직접 Environment와 상호작용을 하면서 Policy 혹은 Value funtion을 직접 learn함
< Model-based vs Model-free for 복잡한 multi-joint agent >- Model-based
- Sample efficiency가 높음
- 최적의 Model 또한 함께 학습해야하는 과정이 추가로 생김 논문에서는 이러한 이유 때문에 locomotion control과 같은 복잡한 문제 상황에서는 Model-free가 낫다고 판단한 것 같음. 또한, 여기서 중점적으로 보는 task 중의 하나인 multi-task learning에서는 model-based로 하면 여러 모델을 만들어야하는것 아닌지...?
- Model-free
- 아무래도 environment와 지속적으로 상호작용 해야하므로 sample efficiency가 보다 낮을 수밖에 없음
- Model-based
-
아이디어
사실 RL agent는 수많은 서로 연결된 sub-component들로 구성되어 있다. 하지만, 기존의 policy network는 주로 MLP를 사용하여 environment으로 부터 획득한 state observation에서 추출한 각 component에 대한 정보를 단순 concatenation하고 MLP의 인풋으로 활용하였다. MLP 기반 policy network는 observation의 단순 concatenation을 받아서 각 component이 취해야 할 action을 각기 따로 출력해야 한다. Sub-component 정보를 한번 뭉뚱거린 후 각 component에 대한 명령값을 출력하기 보다 GNN을 활용하여 각 component를 독자적으로 처리해서 action을 뽑아내는 것이 어떨까?
따라서 NerveNet에서는 agent의 구조적인 특성을 고려하는 inductive bias를 부과하기 위해 policy network를 GNN으로 구성하였다. -
Graph Construction Tree graph 형태
- Nodes
- Body nodes (features O)
- Joint nodes (features O)
- Root node (features O): 논문에 확실하게 명시되지는 않았지만, 그래프 중 하나의 노드를 root node로 활용하는 것 같음. Root node는 agent의 추가적인 정보를 갖고 있는 노드임. 예를 들어, MuJoCo의 Reacher agent를 생각해보면 도달해야 하는 target place에 대한 정보를 root node가 갖고 있음.
- P개의 node types {Body, Joint, Root, ...} 노드별 중요도의 차이
- Edges
- Edges (features X): 그냥 이어진 노드끼리 연결함. Directed 일수도, undirected 일수도 있음. 특별한 weight나 feature이 없으니까 간단한 이진 adjacency matrix로 표현할 수 있음.
- C개의 edge types 서로 다른 노드간 관계, 관계에 따라 message propagation도 다르게 가져감 (Relational GCN 아이디어네 이거!)
- Nodes
-
NerveNet (Policy network)
전체 RL 알고리즘에서의 시간 가 고정되어 있다고 생각하고 설명하겠음-
Input Model
시간 에서의 concatenate된 observation 가 들어오면 이게 노드별로 각각 분리됨. 물론 노드 타입이 여러개니까 타입에 따라 들어온 feature의 차원이 다르겠지? 첨에 이걸 동일 차원으로 맞춰주기 위해 MLP로 구성된 Input Model에 넣어줌. 이 아웃풋을 이라고 하고 여기서 subscript는 노드 인덱스, superscript는 propagation step을 나타냄. 즉 초기에 시작하는 노드 임베딩인거임. Input Model은 입력 차원이 모두 같아야 하므로 노드별로 다른 차원일 때 zero padding을 해줌. -
Propagation Model
여러번(번) internal propagation이 반복됨. 즉 한 노드의 feature를 업데이트 할 때, 그 노드로부터 -hop 떨어진 노드까지 보겠다는 의미임. 여기서는 간단하게 로 propagation 되는 과정을 보겠음.
1) Message Computation Edge type별로 다르게
타겟 노드로 들어오는 엣지를 가진 이웃 노드들에 대해 타겟 노드로 전달해줄 메시지를 계산함. 메시지도 단순하게 MLP 혹은 Identity Mapping으로 정의되는 Message Function에 를 넣어줌으로써 구할 수 있음. 이 때 edge type에 따라 각각 다른 Message Function을 둔다는 점에 주의하기.
2) Message Aggregation Permutation-invariant 해야 함
이제 타겟 노드로 in-link가 있는 이웃 노드들이 전달할 메세지가 모두 준비 되었음. 그럼 이 메시지들을 한데 모아서 타겟 노드로 전달해 줘야 하는데, 이 때 각 계산된 메시지들에 대해 summation, average, 또는 max-pooling을 해서 이웃으로부터의 메시지를 한데 모아줌.
3) States Update Node type별로 다르게
Update Function로는 recurrent 모델인 GRU, LSTM을 쓰거나 간단한 MLP를 활용함. 업데이트시 현재 스텝에서의 타겟 노드 feature와 2)과정에서 합쳐진 메시지를 모두 사용하는데, 이를 수식으로 나타내면 임. 이 때 node type에 따라 각각 다른 Update Function을 사용함.
-
Output Model Actuator type별로 다르게 (Optional)
일반적인 'Gaussian MLP Policy'는 observation에 대한 action의 분포에 대해 mean과 std를 출력함. 이 때, mean은 항상 MLP의 아웃풋으로 뽑지만, std는 그냥 따로 학습 파라미터로 두는 경우도 있고, mean과 함께 MLP의 아웃풋으로 뽑는 경우도 있다.(https://garage.readthedocs.io/en/latest/_autoapi/garage/tf/policies/gaussian_mlp_policy/index.html 참조)
최종 internal propagation이 끝났으면 노드 중 action을 뽑아내야하는 actuator 노드의 최종 feature 벡터 를 MLP로 구성된 Output Model에 넣어줌으로써 action distribution의 mean 를 얻음. 이 때 actuator type에 대해 각기 다른 Output Model을 쓸 수도 있고, 통일된 한 모델을 사용할 수도 있음.
최종적으로 Gaussian policy를 통해 만들어지는 이번 observation(state)에서의 action은 다음과 같음.
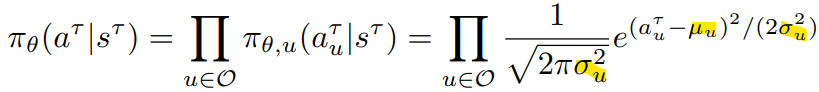
-
-
학습 알고리즘 (PPO 그대로 사용함)
-
NerveNet variants (Value network)
- NerveNet-MLP: GNN(Policy) + MLP(Value)
- NerveNet-2: GNN1(Policy) + GNN2(Value)
- NerveNet-1: GNN1(Policy) + GNN1(Value)
-
실험
- 단순히 GNN policy와 MLP policy의 성능 비교
사실 GNN policy가 MLP policy에 비해서 성능이 확 더 낫거나 그러지 않음. MLP policy에 비해 살짝 낮거나 비슷한 수준.. 즉, 성능 측면으로 볼 때는 GNN policy에 대한 이점이 크게 없으므로, 다른 과업에서의 우수성을 필요로 함! - Transferability by pretraining
- 쟁점: 한 agent에 대해 학습된 policy가 동일 environment의 다른 agent에게도 얼마나 잘 적용되는지
- GNN에 내재된 inductive property 때문에 transferability는 당연히 보장됨 (특히 여기서 다룬 '바뀐' agent가 단순히 학습 agent의 반복 구조 혹은 특정 노드 탈락 구조이기 때문에) 만약에 아예 생판 다른 agent라도 이만큼의 transferability가 보장될까?
- Multi-task learning
- 쟁점: 하나의
- (이외) Walk cycle & Feature distribution & Trajectory density
논문에서처럼 이런 visualization도 추가하려면 MLP와 비교해서 넣어야하지 않았나 싶음. 또한, 취할 수 있는 자세에 구조적인 제한이 걸리므로 이게 원활한 exploration을 방해한다고 생각해야할지, 아니면 방대한 search space상에서 구조적으로 불가능한 state는 아예 배제해서 더 효율적이라고 봐야하는가?
- 단순히 GNN policy와 MLP policy의 성능 비교
