
EDA
import numpy as np
import pandas as pd
import os
import glob
import cv2
import matplotlib.pyplot as plt
import seaborn as sns
import torch
import yaml
import tensorrt
from tqdm import tqdm
from google.colab import drive
%matplotlib inline
drive.mount('/content/drive')print('train images', len(glob.glob('/content/drive/MyDrive/딥러닝_프로젝트/vehicle dataset/train/images/*')))
print('train labels', len(glob.glob('/content/drive/MyDrive/딥러닝_프로젝트/vehicle dataset/train/labels/*')))
print('test images', len(glob.glob('/content/drive/MyDrive/딥러닝_프로젝트/vehicle dataset/valid/images/*')))
print('test labels', len(glob.glob('/content/drive/MyDrive/딥러닝_프로젝트/vehicle dataset/valid/labels/*')))
# train images 2100
# train labels 2100
# test images 900
# test labels 900path = '/content/drive/MyDrive/딥러닝_프로젝트/vehicle dataset/'
dataset = {
'image_path' : [],
'image_name' : [],
'where' : []
}
# 이미지
for where in os.listdir(path):
if (where == 'train') | (where == 'valid'):
for status in os.listdir(path + where):
if status != '.DS_Store':
for image in glob.glob(path + where + '/images/*'):
# 이미지 path 저장
dataset['image_path'].append(image)
# 이미지 파일명 저장
image_name = os.path.splitext(image.split('/')[-1])[0]
dataset['image_name'].append(image_name)
# train/val 저장
dataset['where'].append(where)data = pd.DataFrame(dataset)
data['textfile_name'] = ''
data['label'] = ''
data['index'] = ''
# 텍스트파일
for where in os.listdir(path):
if (where == 'train') | (where == 'valid'):
for status in os.listdir(path + where):
if status != '.DS_Store':
for label in tqdm(glob.glob(path + where + '/labels/*')):
txt_file_name = os.path.splitext(label.split('/')[-1])[0]
for idx, row in data.iterrows():
if txt_file_name == row['image_name']:
# 텍스트 파일명 저장
data.loc[idx, 'textfile_name'] = txt_file_name
with open(label, 'r') as f:
content = f.read().split(' ')
data.loc[idx, 'label'] = content[0] # label(class) 저장
data.loc[idx, 'index'] = content[1:] # index 저장
data['label'] = data['label'].astype(int)
data['vehicle'] = ''
for idx, row in data.iterrows():
if row['label'] == 0:
data.loc[idx, 'vehicle'] = 'car'
elif row['label'] == 1:
data.loc[idx, 'vehicle'] = 'threewheel'
elif row['label'] == 2:
data.loc[idx, 'vehicle'] = 'bus'
elif row['label'] == 3:
data.loc[idx, 'vehicle'] = 'truck'
elif row['label'] == 4:
data.loc[idx, 'vehicle'] = 'motorbike'
elif row['label'] == 5:
data.loc[idx, 'vehicle'] = 'van'
data = data[['label','vehicle','index','where','textfile_name','image_name','image_path']]sns.countplot(x=data['where'].sort_values());
plt.title('Valid & Train data Count')
plt.show()
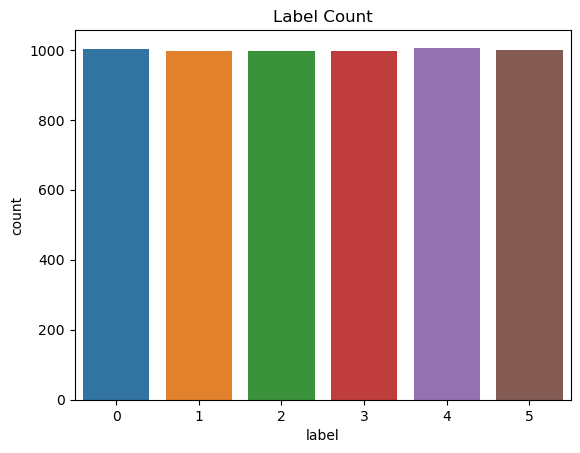
sns.countplot(x=data['label'].sort_values());
plt.title('Label Count')
plt.show()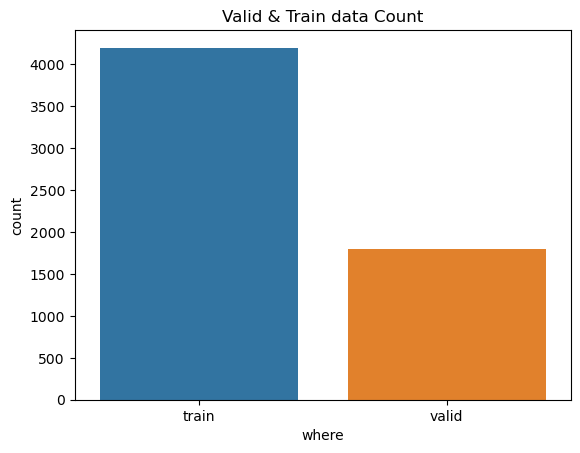
# 이미지 데이터 보기
plt.figure(figsize=(12,5))
for i in range(6):
label_df = data[data['label'] == i]
idx = label_df.index[0]
plt.subplot(2,3, i+1)
plt.imshow(cv2.imread(data.loc[idx, 'image_path']))
plt.title(str(i) + ' : ' + data.loc[idx, 'vehicle'])
plt.xticks([])
plt.yticks([])
plt.show()
YOLO
%cd /content/drive/MyDrive/딥러닝_프로젝트
!mkdir tmp
%cd tmp
# yolov7 가져오기
!git clone https://github.com/WongKinYiu/yolov7 # clone repo
%cd yolov7
%pip install -qr requirements.txt
%cd ../
print(f"Setup complete. Using torch {torch.__version__} ({torch.cuda.get_device_properties(0).name if torch.cuda.is_available() else 'CPU'})")
# dataset
%cp -r '/content/drive/MyDrive/딥러닝_프로젝트/vehicle dataset' /content/drive/MyDrive/딥러닝_프로젝트/tmp/kaggle/tmp
# data_yaml
data_yaml = dict(
train = '/content/drive/MyDrive/딥러닝_프로젝트/tmp/kaggle/tmp/train',
val = '/content/drive/MyDrive/딥러닝_프로젝트/tmp/kaggle/tmp/valid',
nc = 6,
names = ['car', 'threewheel', 'bus', 'truck', 'motorbike', 'van']
)
yaml_path = '/content/drive/MyDrive/딥러닝_프로젝트/tmp/data.yaml'
with open(yaml_path, 'w') as outfile:
yaml.dump(data_yaml, outfile, default_flow_style=True)
%cd /content/drive/MyDrive/딥러닝_프로젝트/tmp/yolov7
# 학습
!wandb disabled
!python train.py --img 500 --batch 4 --epochs 15 --data ../data.yaml --weights 'yolov7.pt'결과
img = cv2.imread("/content/drive/MyDrive/딥러닝_프로젝트/tmp/yolov7/runs/train/exp4/results.png")
plt.figure(figsize=(10, 5))
plt.xticks([])
plt.yticks([])
plt.imshow(img);
img = cv2.imread("/content/drive/MyDrive/딥러닝_프로젝트/tmp/yolov7/runs/train/exp4/test_batch0_pred.jpg")
plt.figure(figsize=(10, 5))
plt.xticks([])
plt.yticks([])
plt.imshow(img);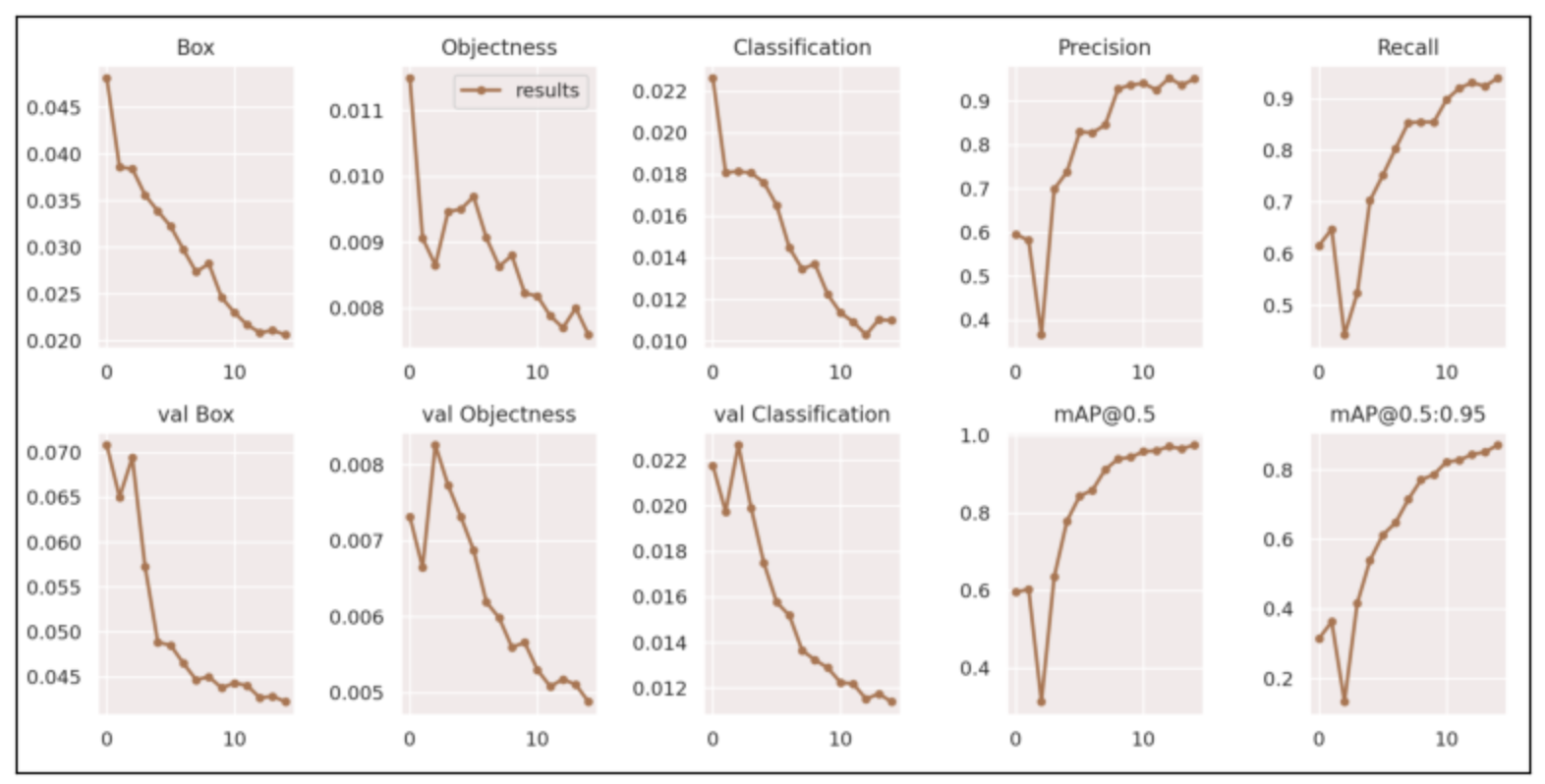


21세기 주인공