
- PCA에서는 scaler 과정이 중요하다.
- KNN과 같이 잘 쓰인다.

PCA
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# 데이터 만들기
rng = np.random.RandomState(13)
X = np.dot(rng.rand(2,2), rng.randn(2,200)).T
plt.scatter(X[:,0], X[:,1])
plt.axis('equal')
from sklearn.decomposition import PCA
pca = PCA(n_components=2, random_state=13)
pca.fit(X)
# 벡터와 분산값
pca.components_
# array([[ 0.47802511, 0.87834617],
# [-0.87834617, 0.47802511]])
# 설명력
pca.explained_variance_ # array([1.82531406, 0.13209947])
pca.explained_variance_ratio_
# 함수(벡터 그리기)
def draw_vector(v0, v1, ax=None):
ax = ax or plt.gca()
arrowprops = dict(
arrowstyle='->',
linewidth=2,
color='black',
shrinkA=0,
shrinkB=0)
ax.annotate('', v1, v0, arrowprops=arrowprops)
# 벡터 그리기
plt.scatter(X[:,0], X[:,1], alpha=0.4)
for length, vector in zip(pca.explained_variance_, pca.components_):
v = vector * 3 * np.sqrt(length)
draw_vector(pca.mean_, pca.mean_ + v)
plt.axis('equal')
plt.show()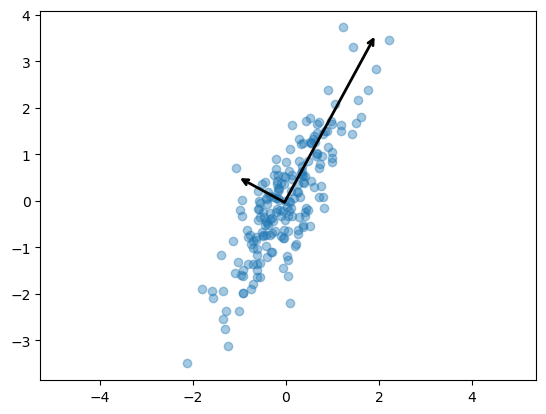
함수 만들기
# get_pca_data
def get_pca_data(ss_data, n_components=2):
pca = PCA(n_components=n_components)
pca.fit(ss_data)
return pca.transform(ss_data), pca
# get_pd_from_pca
def get_pd_from_pca(pca_data, cols=['PC1','PC2']):
return pd.DataFrame(pca_data, columns=cols)
# get_pd_from_pca2
def get_pd_from_pca2(pca_data, col_num):
cols = ['pca_'+str(n) for n in range(pca.components_.shape[0])]
return pd.DataFrame(pca_data, columns=cols)
# rf_scores
def rf_scores(X, y, cv=5):
rf = RandomForestClassifier(random_state=13, n_estimators=100)
scores_rf = cross_val_score(rf, X, y, scoring='accuracy', cv=cv)
print('Score : ', np.mean(scores_rf))
# print_variance_ratio
def print_variance_ratio(pca):
print('variance_ratio : ', pca.explained_variance_ratio_)
print('sum of variance_ratio : ', np.sum(pca.explained_variance_ratio_))
# results
def results(y_pred, y_test):
from sklearn.metrics import classification_report, confusion_matrix
print(classification_report(y_test, y_pred))iris 데이터 분석
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
iris = load_iris()
iris_pd = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_pd['species'] = iris.target
# 전처리
iris_ss = StandardScaler().fit_transform(iris.data)
# pca
iris_pca, pca = get_pca_data(iris_ss, 2)
# DataFrame
iris_pd_pca = get_pd_from_pca(iris_pca)
iris_pd_pca['species'] = iris.target
# 시각화
sns.pairplot(iris_pd_pca, hue='species', height=5, x_vars=['PC1'], y_vars=['PC2'])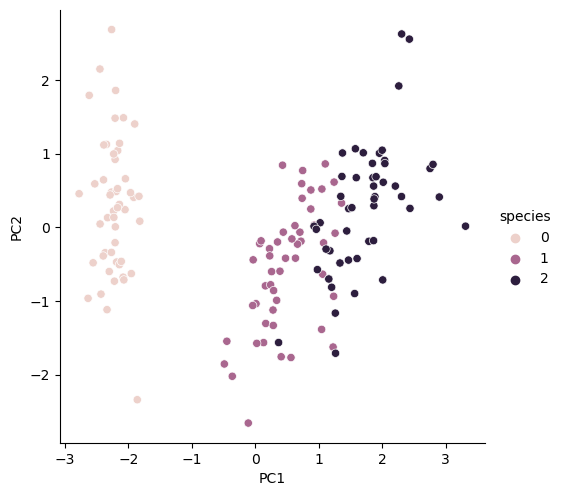
# 전처리 한 데이터
rf_scores(iris_ss, iris.target) # 0.96
# 주성분분석 한 데이터
pca_X = iris_pd_pca[['PC1', 'PC2']]
rf_scores(pca_X, iris.target) # 0.9066666666666666wine 데이터 분석
wine_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/wine.csv'
wine = pd.read_csv(wine_url, index_col=0)
wine_X = wine.drop(['color'], axis=1)
wine_y = wine['color']
# 전처리
wine_ss = StandardScaler().fit_transform(wine_X)주성분 2개
# pca
pca_wine, pca = get_pca_data(wine_ss, n_components=2)
print_variance_ratio(pca)
# variance_ratio : [0.25346226 0.22082117]
# sum of variance_ratio : 0.4742834274323627
# DataFrame
pca_columns = ['PC1','PC2']
pca_wine_pd = get_pd_from_pca(pca_wine, pca_columns)
pca_wine_pd['color'] = wine_y.values
# 시각화
sns.pairplot(pca_wine_pd, hue='color', height=5, x_vars=['PC1'], y_vars=['PC2'])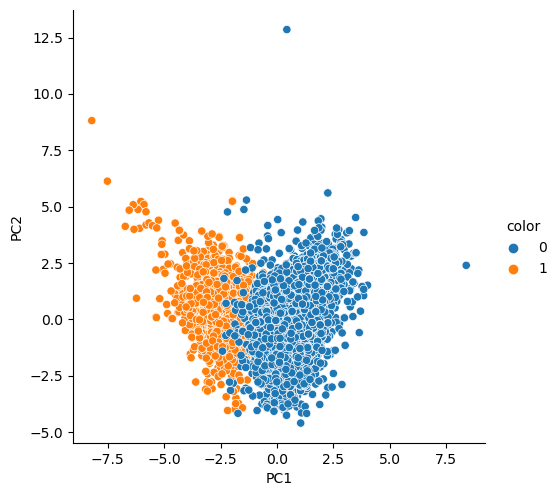
# 전처리 한 데이터
rf_scores(wine_ss, wine_y) # 0.9935352638124
# 주성분분석 한 데이터
pca_X = pca_wine_pd[['PC1', 'PC2']]
rf_scores(pca_X, wine_y) # 0.981067803635933주성분 3개
# pca
pca_wine, pca = get_pca_data(wine_ss, n_components=3)
print_variance_ratio(pca)
# variance_ratio : [0.25346226 0.22082117 0.13679223]
# sum of variance_ratio : 0.6110756621838705
# DataFrame
pca_columns = ['PC1','PC2','PC3']
pca_wine_pd = get_pd_from_pca(pca_wine, pca_columns)
pca_wine_pd['color'] = wine_y.values
pca_X = pca_wine_pd[pca_columns]
rf_scores(pca_X, wine_y) # 0.9832236631728548# 시각화
import plotly.express as px
pca_wine_plot = pca_X
pca_wine_plot['color'] = wine_y.values
fig = px.scatter_3d(pca_wine_plot, x='PC1', y='PC2', z='PC3', color='color', opacity=0.4)
fig.update_layout(margin=dict(l=0, r=0, b=0, t=0))
fig.show()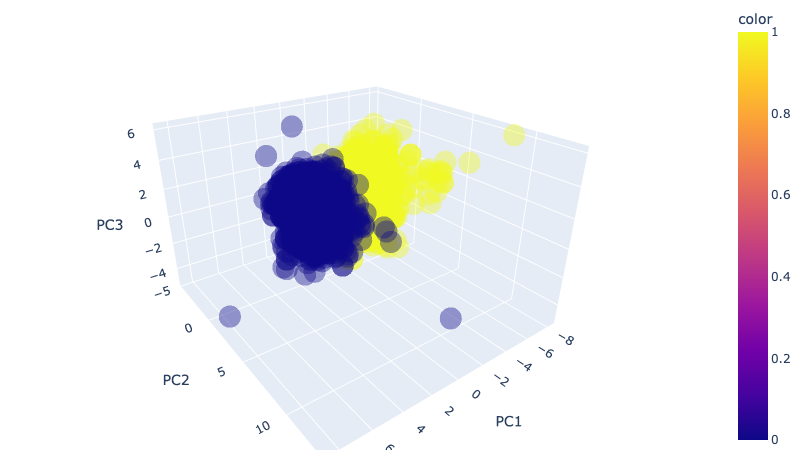
Olivetti 데이터
from sklearn.datasets import fetch_olivetti_faces
faces_all = fetch_olivetti_faces()
# 20번 째 사람
k = 20
faces = faces_all.images[faces_all.target == k]
# Olivetti 데이터의 2번 사람 그리기
N = 2
M = 5
fig = plt.figure(figsize=(10,5))
plt.subplots_adjust(top=1, bottom=0, hspace=0, wspace=0.05)
for n in range(N*M):
ax = fig.add_subplot(N, M, n+1)
ax.imshow(faces[n], cmap=plt.cm.bone)
ax.grid(False)
ax.xaxis.set_ticks([])
ax.yaxis.set_ticks([])
plt.suptitle('Olivetti20')
plt.tight_layout()
plt.show()
# pca
pca = PCA(n_components=2)
X = faces_all.data[faces_all.target == k]
W = pca.fit_transform(X)
X_inv = pca.inverse_transform(W)
# pca 후 Olivetti 데이터의 2번 사람 그리기
N = 2
M = 5
fig = plt.figure(figsize=(10,5))
plt.subplots_adjust(top=1, bottom=0, hspace=0, wspace=0.05)
for n in range(N*M):
ax = fig.add_subplot(N, M, n+1)
ax.imshow(X_inv[n].reshape(64,64), cmap=plt.cm.bone)
ax.grid(False)
ax.xaxis.set_ticks([])
ax.yaxis.set_ticks([])
plt.suptitle('PCA result')
plt.tight_layout()
plt.show()
face_mean = pca.mean_.reshape(64,64)
face_p1 = pca.components_[0].reshape(64,64)
face_p2 = pca.components_[1].reshape(64,64)
plt.figure(figsize=(12,7))
plt.subplot(131)
plt.imshow(face_mean, cmap=plt.cm.bone)
plt.grid(False); plt.xticks([]); plt.yticks([]); plt.title("mean")
plt.subplot(132)
plt.imshow(face_p1, cmap=plt.cm.bone)
plt.grid(False); plt.xticks([]); plt.yticks([]); plt.title("face_p1")
plt.subplot(133)
plt.imshow(face_p2, cmap=plt.cm.bone)
plt.grid(False); plt.xticks([]); plt.yticks([]); plt.title("face_p2")
plt.show()
# 가중치 선정
N = 2
M = 5
w = np.linspace(-5, 10, N*M)
# array([-5. , -3.33333333, -1.66666667, 0. , 1.66666667,
# 3.33333333, 5. , 6.66666667, 8.33333333, 10. ])# face_p1, face_p2에 가중치 곱해서 평균 얼굴에 적용
fig = plt.figure(figsize=(10,5))
plt.subplots_adjust(top=1, bottom=0, hspace=0, wspace=0.05)
for n in range(N*M):
ax = fig.add_subplot(N, M, n+1)
ax.imshow(face_mean + w[n] * face_p1, cmap=plt.cm.bone) # face_p2
ax.grid(False)
ax.xaxis.set_ticks([])
ax.yaxis.set_ticks([])
plt.title('Weight : ' + str(round(w[n])))
plt.tight_layout()
plt.show()

# 두 개의 성분 모두 표현
nx, ny = (5,5)
x = np.linspace(-5, 8, nx)
y = np.linspace(-5, 8, ny)
w1, w2 = np.meshgrid(x, y)
w1 = w1.reshape(-1,)
w2 = w2.reshape(-1,)
# 그리기
fig = plt.figure(figsize=(10,5))
plt.subplots_adjust(top=1, bottom=0, hspace=0, wspace=0.05)
for n in range(N*M):
ax = fig.add_subplot(N, M, n+1)
ax.imshow(face_mean + w1[n]*face_p1 + w2[n]*face_p2, cmap=plt.cm.bone)
ax.grid(False)
ax.xaxis.set_ticks([])
ax.yaxis.set_ticks([])
plt.title(str(round(w1[n])) + ', ' + str(round(w2[n])))
plt.tight_layout()
plt.show()
HAR 데이터
url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/features.txt'
feature_name_df = pd.read_csv(url, sep='\s+', header=None, names=['column_index','column_name'])
feature_name = feature_name_df.iloc[:,1].values.tolist()
X_train_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/train/X_train.txt'
X_test_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/test/X_test.txt'
X_train = pd.read_csv(X_train_url, sep='\s+', header=None)
X_test = pd.read_csv(X_test_url, sep='\s+', header=None)
X_train.columns = feature_name
X_test.columns = feature_name
y_train_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/train/y_train.txt'
y_test_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/test/y_test.txt'
y_train = pd.read_csv(y_train_url, sep='\s+', header=None)
y_test = pd.read_csv(y_test_url, sep='\s+', header=None)# pca
HAR_pca, pca = get_pca_data(X_train, n_components=2)
HAR_pd_pca = get_pd_from_pca2(HAR_pca, pca.components_.shape[0])
HAR_pd_pca["action"] = y_train
# 시각화
sns.pairplot(HAR_pd_pca, hue='action', height=5, x_vars=['pca_0'], y_vars=['pca_1']);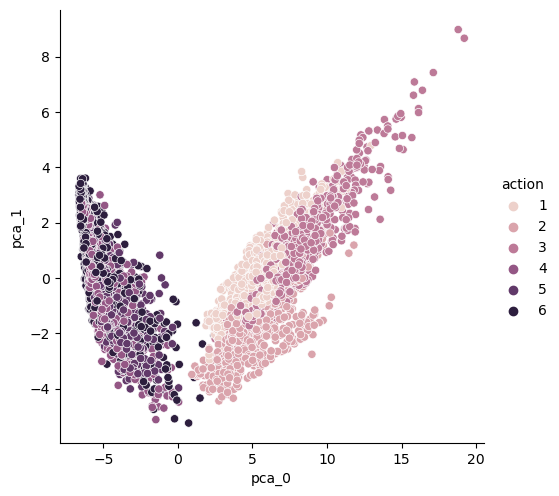
# 설명력 확인
print_variance_ratio(pca)
# variance_ratio : [0.6255444 0.04913023]
# sum of variance_ratio : 0.6746746270487951GridSearchCV, RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
params = {
'max_depth' : [6,8,10],
'n_estimators' : [50,100,200],
'min_samples_leaf' : [8,12],
'min_samples_split' : [8,12]
}
rf_clf = RandomForestClassifier(random_state=13, n_jobs=-1)
grid_cv = GridSearchCV(rf_clf, param_grid=params, cv=2, n_jobs=-1)
grid_cv.fit(HAR_pca, y_train.values.reshape(-1,))
# 성능 확인
cv_results_df = pd.DataFrame(grid_cv.cv_results_)
target_col = ['rank_test_score','mean_test_score','param_n_estimators','param_max_depth']
cv_results_df[target_col].sort_values('rank_test_score').head()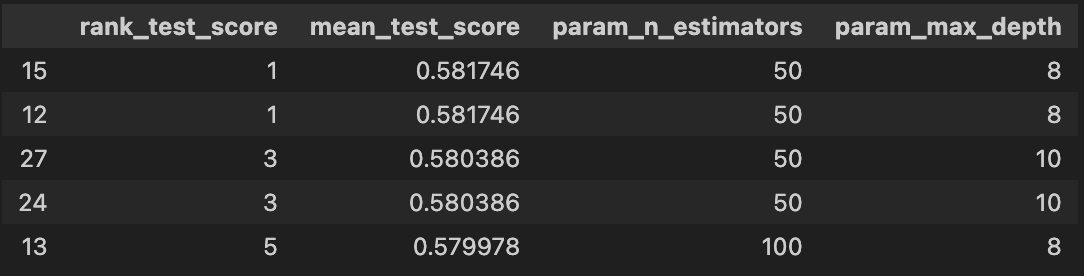
grid_cv.best_params_
# {'max_depth': 8,
# 'min_samples_leaf': 8,
# 'min_samples_split': 8,
# 'n_estimators': 50}
grid_cv.best_score_ # 0.5817464635473341# 테스트
from sklearn.metrics import accuracy_score
rf_clf_best = grid_cv.best_estimator_
rf_clf_best.fit(HAR_pca, y_train.values.reshape(-1,))
pred1 = rf_clf_best.predict(pca.transform(X_test))
accuracy_score(y_test, pred1) # 0.5965388530709196XGBoost
import time
from xgboost import XGBClassifier
start_time = time.time()
evals = [(pca.transform(X_test), y_test)]
xgb = XGBClassifier(n_estimators=400, learning_rate=0.1, max_depth=3)
xgb.fit(HAR_pca, y_train.values.reshape(-1,))
print('Fit time : ', time.time() - start_time) # Fit time : 2.3767359256744385
xgb_pred = xgb.predict(pca.transform(X_test))
accuracy_score(y_test-1, xgb_pred) # 0.5748218527315915MNIST
import random
df_train = pd.read_csv('../data/mnist_train.csv')
df_test = pd.read_csv('../data/mnist_test.csv')
df_train.shape, df_test.shape # ((60000, 785), (10000, 785))
X_train = np.array(df_train.iloc[:, 1:])
y_train = np.array(df_train['label'])
X_test = np.array(df_test.iloc[:, 1:])
y_test = np.array(df_test['label'])
# 샘플 데이터 확인
samples = random.choices(population=range(0,60000), k=16)
plt.figure(figsize=(14,12))
for idx, n in enumerate(samples):
plt.subplot(4,4,idx+1)
plt.imshow(X_train[n].reshape(28,28), cmap='Greys', interpolation='nearest')
plt.title(y_train[n])
plt.show()
Pipeline, GridSearchCV, PCA, KFold
from sklearn.neighbors import KNeighborsClassifier
start_time = time.time()
clf = KNeighborsClassifier(n_neighbors=5)
clf.fit(X_train, y_train)
print('Fit time : ', time.time() - start_time)from sklearn.pipeline import Pipeline
from sklearn.model_selection import StratifiedKFold
pipe = Pipeline([
('pca', PCA()),
('clf', KNeighborsClassifier())
])
parameters = {
'pca__n_components' : [2,5,10],
'clf__n_neighbors' : [5,10,15]
}
kf = StratifiedKFold(n_splits=5, shuffle=True, random_state=13)
grid = GridSearchCV(pipe, parameters, cv=kf, n_jobs=-1, verbose=1)
grid.fit(X_train, y_train)
# 결과 확인
print(grid.best_estimator_)
# Pipeline(steps=[('pca', PCA(n_components=10)),
# ('clf', KNeighborsClassifier(n_neighbors=10))])
grid.best_score_ # 0.9311
results(grid.predict(X_train), y_train)# 확인
n = 700
plt.imshow(X_test[n].reshape(28,28), cmap='Greys', interpolation='nearest')
plt.show()
print('Answer is : ', grid.best_estimator_.predict(X_test[n].reshape(1,784)))
print('Reat Label is : ', y_test[n])
# 틀린 데아터 확인
preds = grid.best_estimator_.predict(X_test)
wrong_results = X_test[y_test != preds]
samples = random.choices(population=range(0, wrong_results.shape[0]), k=16)
plt.figure(figsize=(14,12))
for idx, n in enumerate(samples):
plt.subplot(4,4,idx+1)
plt.imshow(wrong_results[n].reshape(28,28), cmap='Greys')
pred_digit = grid.best_estimator_.predict(wrong_results[n].reshape(1,784))
plt.title(str(pred_digit))
plt.show()
군집(Clustering)
iris 데이터
from sklearn.preprocessing import scale
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
%matplotlib inline
iris = load_iris()
cols = [each[:-5] for each in iris.feature_names]
iris_df = pd.DataFrame(data=iris.data, columns=cols)
feature = iris_df[['petal length','petal width']]
# 군집화
model = KMeans(n_clusters=3)
model.fit(feature)
# 군집 중심값 확인
model.cluster_centers_
predict = pd.DataFrame(model.predict(feature), columns=['cluster'])
feature = pd.concat([feature, predict], axis=1)
centers = pd.DataFrame(model.cluster_centers_, columns=['petal length','petal width'])
center_x = centers['petal length']
center_y = centers['petal width']
plt.figure(figsize=(12,8))
plt.scatter(feature['petal length'], feature['petal width'], c=feature['cluster'], alpha=0.5)
plt.scatter(center_x, center_y, s=50, marker='D', c='r')
plt.show()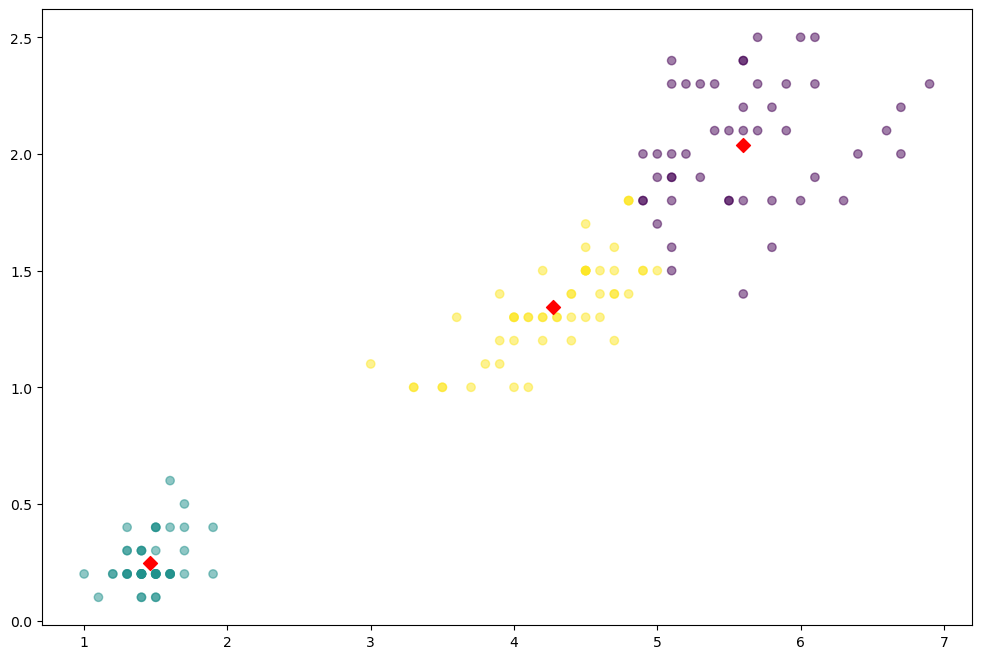
군집 평가
iris = load_iris()
feature_names = ['sepal length', 'sepal width', 'petal length', 'petal width']
iris_df = pd.DataFrame(data=iris.data, columns=feature_names)
kmeans = KMeans(n_clusters=3, init='k-means++', max_iter=300, random_state=0).fit(iris_df)
iris_df['cluster'] = kmeans.labels_from sklearn.metrics import silhouette_samples, silhouette_score
from yellowbrick.cluster import silhouette_visualizer
avg_value = silhouette_score(iris.data, iris_df['cluster'])
score_values = silhouette_samples(iris.data, iris_df['cluster'])
silhouette_visualizer(kmeans, iris.data, colors='yellowbrick')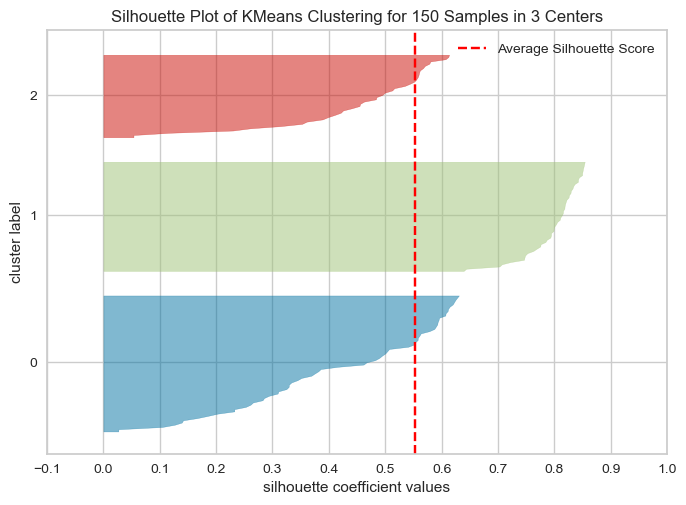
이미지 분할
from matplotlib.image import imread
image = imread('../data/ladybug.png')
plt.imshow(image);
from sklearn.cluster import KMeans
X = image.reshape(-1, 3)
kmeans = KMeans(n_clusters=8, random_state=13).fit(X)
segmented_img = kmeans.cluster_centers_[kmeans.labels_]
segmented_img = segmented_img.reshape(image.shape)
plt.imshow(segmented_img);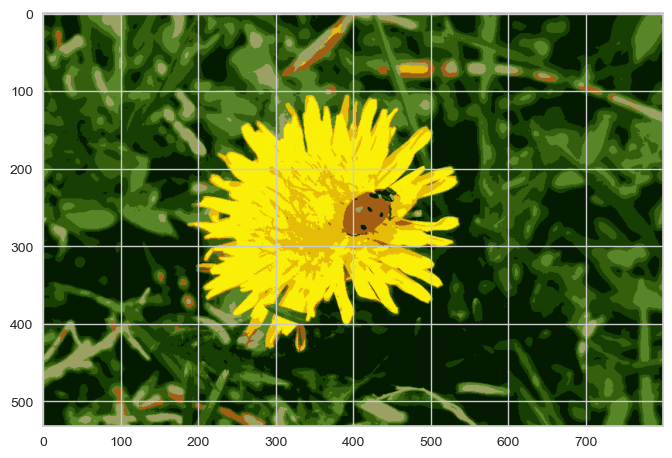
# 여러개의 군집 비교
segmented_imgs = []
n_colors = (10,8,6,4,2)
for n_clusters in n_colors:
kmeans = KMeans(n_clusters=n_clusters, random_state=13).fit(X)
segmented_img = kmeans.cluster_centers_[kmeans.labels_]
segmented_img = segmented_img.reshape(image.shape)
segmented_imgs.append(segmented_img)
plt.figure(figsize=(10,5))
plt.subplots_adjust(wspace=0.05, hspace=0.1)
plt.subplot(231)
plt.imshow(image)
plt.title("Original image")
plt.axis('off')
for idx, n_clusters in enumerate(n_colors):
plt.subplot(232 + idx)
plt.imshow(segmented_imgs[idx])
plt.title("{} colors".format(n_clusters))
plt.axis("off")
plt.show()

21세기 주인공