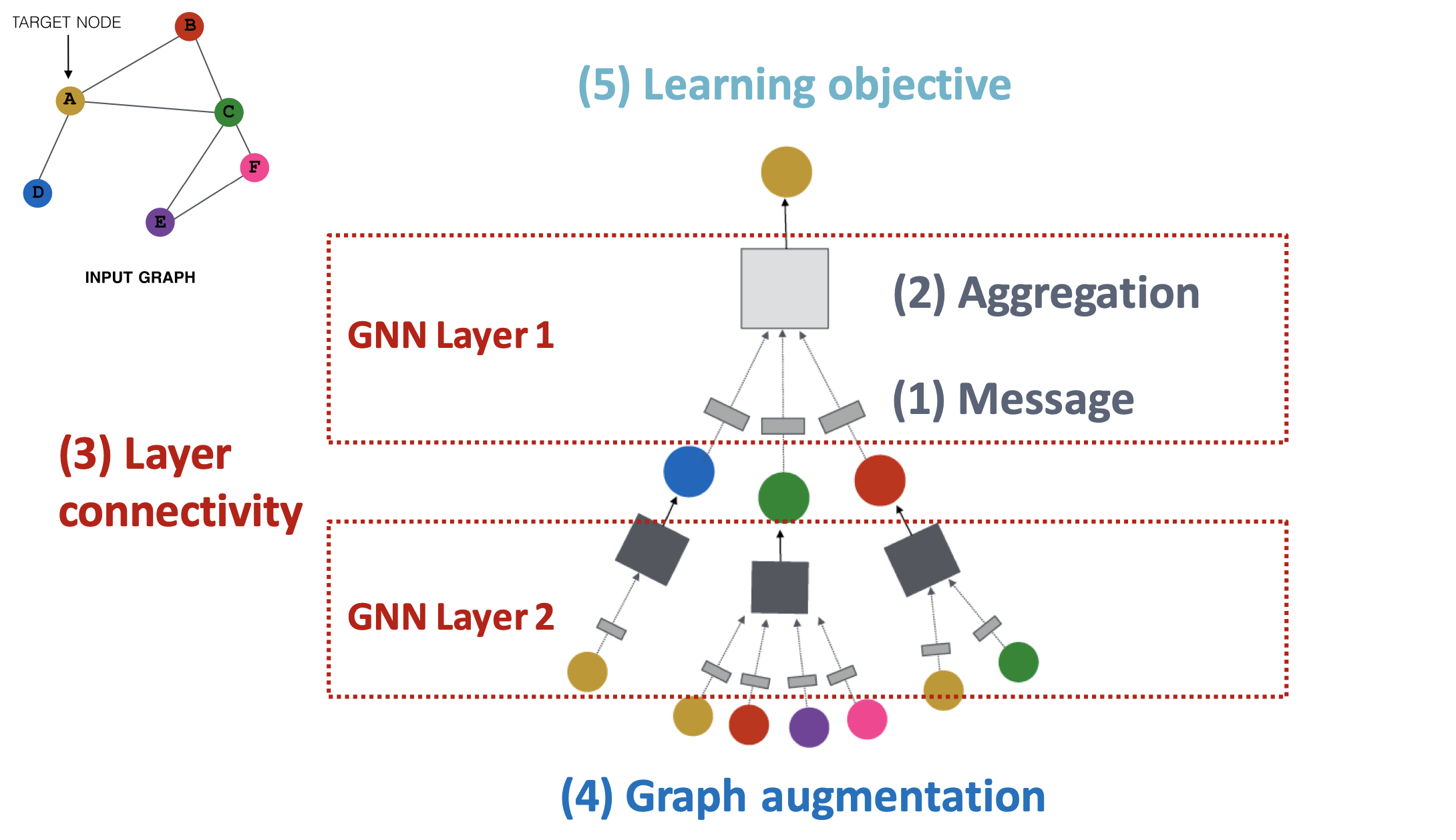
GNN 프레임워크
일반적인 GNN 모델의 프레임워크는 다음과 같다.
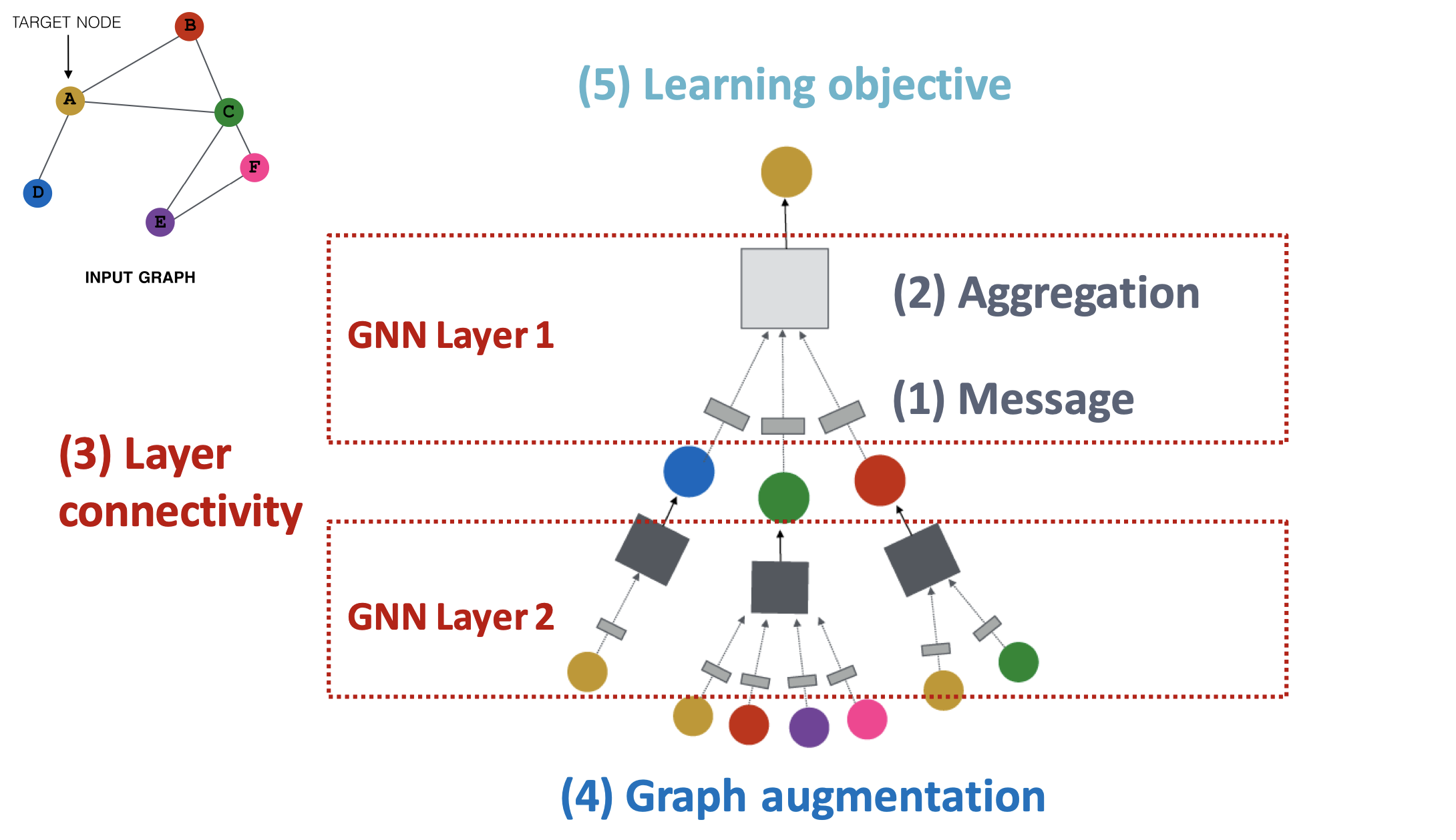
GNN 모델의 디자인 요소는 크게 5가지로 나눠 볼 수 있다.
- Message
: GNN 레이어에서 이웃 노드들로부터 메시지를 계산하는 방법- Aggregation
: GNN 레이어에서 이웃 노드들의 메시지를 취합하는 방법- Layer connectivity
: 신경망 형태로 만들기 위해 여러 레이어를 쌓는(연결하는) 방법- Graph augmentation
: 입력 그래프를 적절하게 수정하는 방법- Learning objective
: task에 따른 모델의 학습 방향
단계적으로 살펴보도록 하자.
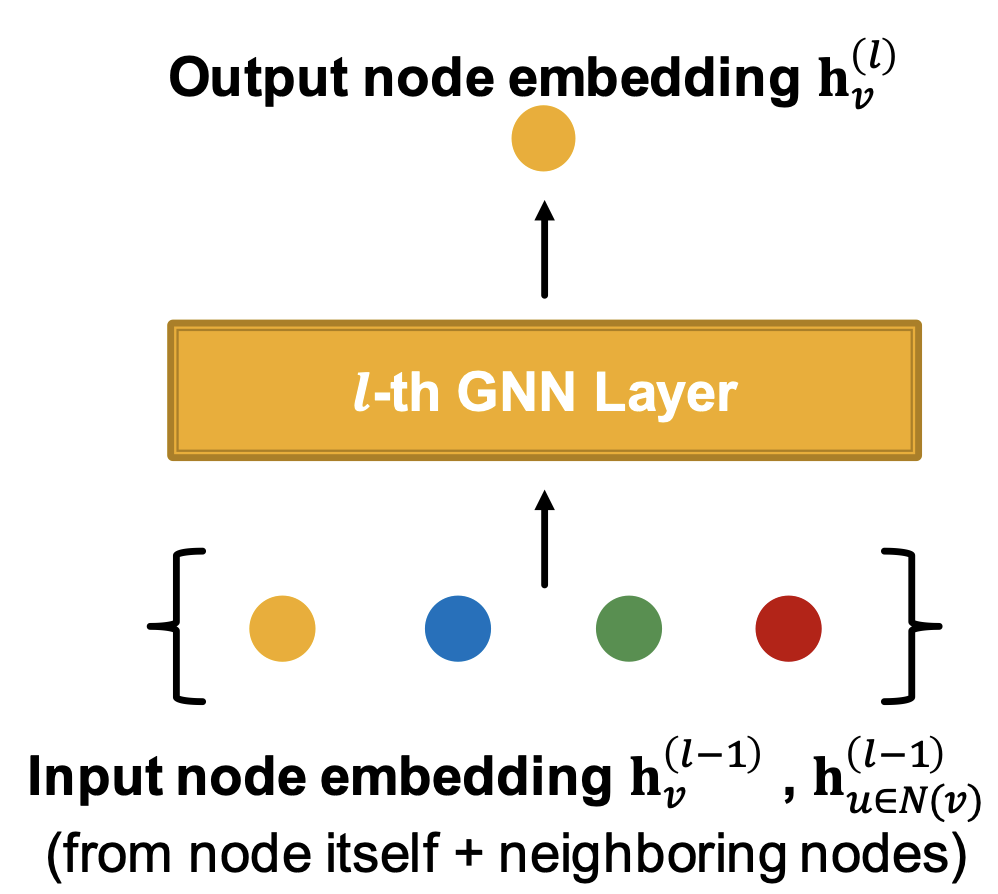
1. GNN 레이어
GNN 레이어에서 연산은 (1) Message computation과 (2) Aggregation의 두 단계로 진행된다.
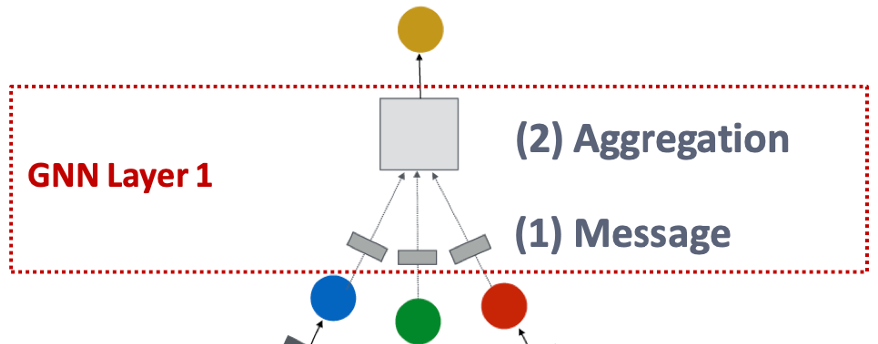
순서대로, 이웃 노드들이 입력되면 (1) 각 노드들로부터 메시지를 계산하고 (2) 계산된 메시지들을 하나로 종합하여 중심 노드의 정보인 노드 임베딩을 출력하는 방식이다.
1.1. Message (computation)
메시지를 계산하는 과정을 수식으로 나타내면 다음과 같다.
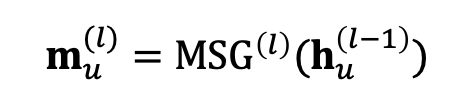
이웃 노드들 에 대해, 현재 레이어에서의 메시지 은 이전 레이어에서 온 정보 이 현재 레이어에서 메시지를 계산하는 함수 을 거쳐 계산된다.
이러한 메시지 계산 함수의 설계 방식이 GNN 모델의 첫 번째 디자인 요소로, 간단하게는 weight matrix를 함수로 사용하여 선형 변환 형태로 구현할 수 있다.
표기를 자세히 보면 메시지나 노드 임베딩 뿐만 아니라 메시지 계산 함수도 레이어에 따라 달라지는 것도 확인할 수 있다.
1.2. Aggregation
이웃 노드들 의 메시지를 계산하였다면, 이들을 중심 노드 하나의 정보를 나타내는 벡터로 모아야 한다. 수식으로 나타내면 다음과 같다.
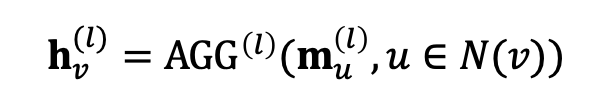
이 과정을 수행하는 의 설정이 GNN 모델의 두 번째 디자인 요소에 해당된다. 여기서 주의할 점은 반드시 순서에 영향을 받지 않는(order invariant) 함수로 설정되어야 한다는 것인데, 이는 이웃 노드들이 순서에 따라 다른 영향을 주지 않는 그래프의 구조적 특성 때문이다. 간단하게는 합이나 평균, 최댓값을 사용할 수 있다.
1.2.1. Issue
결국 연산의 목적은 중심 노드 의 정보 계산에 있고 이를 위해 이웃 노드들 의 정보를 사용하는 것이다.
그런데 한 가지 문제가 있다. 의 정보를 계산하는데 가 기존에 갖고 있던 정보는 사용하지 않는다.
이렇게 되면 자기 자신의 정보가 소실되어 버릴 수 있기 때문에 해결할 필요가 있다.
방법은 간단하다. 의 계산에 도 포함시키면 된다.
단, 중심 노드는 이웃 노드들과 엄연히 다르기 때문에 위의 두 과정을 따로 수행한다.
이웃 노드들로부터 메시지를 계산하는데 를 사용했다면, 중심 노드에 대해서는 을 사용한다. 또한, 이나 을 이용하여 aggregation 과정에서 그 정보를 보존시킨다.
1.3. Non-linearity
앞선 과정들에서 모델의 표현력이 부족하다고 판단된다면 비선형성을 더해주기 위해 비선형 활성 함수 를 도입할 수도 있다. 예를 들어, 선형 변환을 통해 메시지를 계산하고 이를 단순히 더해 종합한다고 하면,
모든 과정은 하나의 선형 변환으로 표현될 수 있을 것이다. 이에 따라 GNN 레이어에서도 여타 딥러닝 모델들처럼 ReLU나 Sigmoid 같은 비선형 활성 함수의 도입이 가능하다. 레이어의 두 단계에 모두 적용이 가능하나 주로 aggregation이 끝난 결과에 사용된다.
최종적으로 중심 노드 의 번째 노드 임베딩을 계산하는 과정은 다음과 같다.
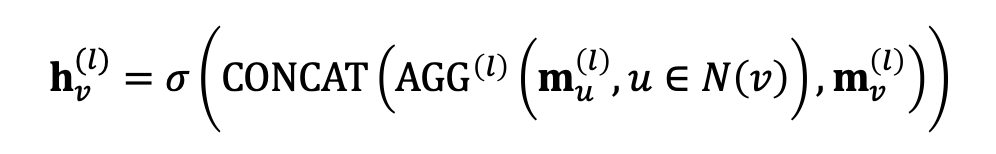
2. 클래식 GNN 레이어
GNN 모델을 디자인하는 요소 중 두 가지가 GNN 레이어에서의 연산 방법을 결정하는 것이었다.
이는 모델의 가장 기본적인 작동 방식이 되기 때문에, 어떻게 정의되는지가 모델을 구분 짓는 기준이 된다.
몇 가지 중요한 GNN 모델에서 레이어 내부의 message computation과 aggregation을 어떻게 구성하는지 알아보자.
2.1. GCN (Graph Convolutional Networks)
먼저, 가장 기본적인 모델인 GCN에서는 중심 노드의 이웃에 중심 노드도 포함되는 self-edges를 가정하고 다음과 같은 식을 사용한다. 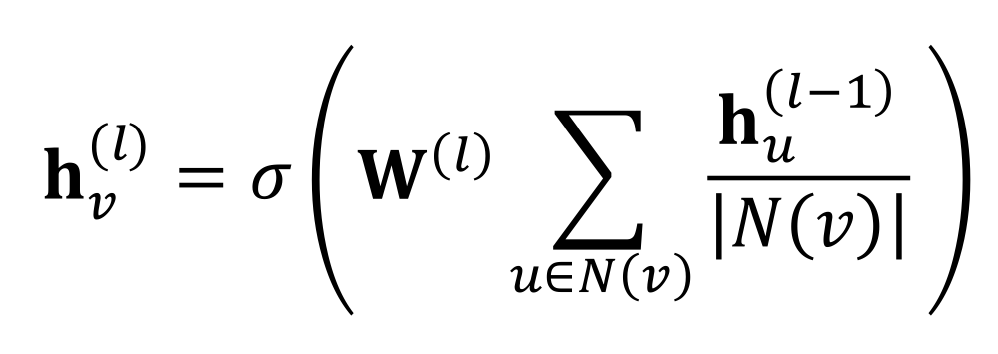
여기서 은 summation에 영향을 주지 않으니 식을 조금 수정하면 다음과 같다.
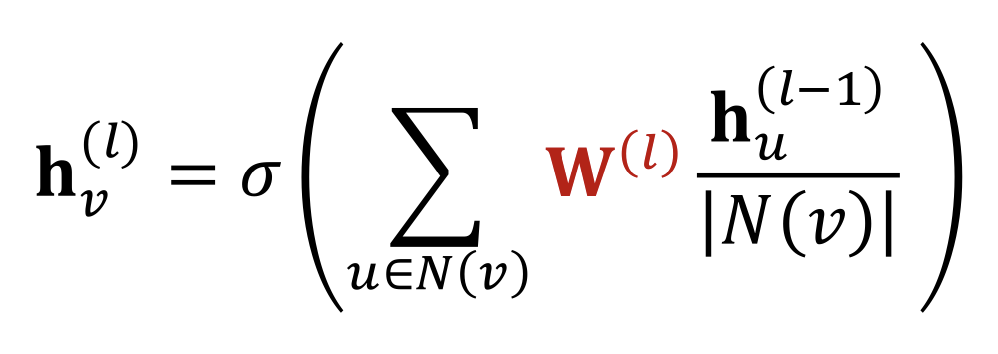
이렇게 보면 message와 aggregation 부분을 나누기 편하다.
message는 이웃 노드의 정보에 대해 선형 변환한 값을 중심 노드의 degree로 normalize하여 계산한다.
이후, 계산된 message들을 합하여 aggregation을 진행하고 비선형 활성 함수를 거치게 된다.
2.2. GraphSAGE
GraphSAGE에서는 self-edges 가정을 제외했다. 그에 따라 중심 노드의 정보를 연산에 포함시키기 위해 2단계 aggregation을 사용한다. 일단 전체 식은 다음과 같다.
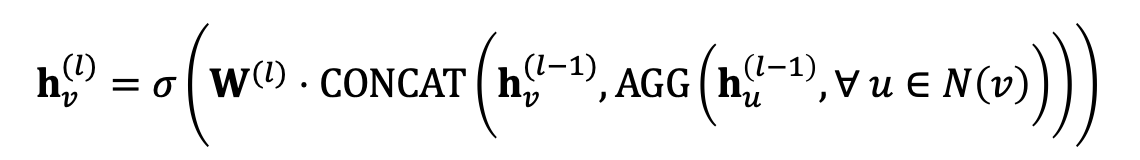
2단계라 했으니 나누어 접근하면,
1단계에서는 이웃 노드들의 정보만 먼저 모은다. 이 과정에서 이웃 노드들의 message 계산은 에서 수행한다. 로는 다양한 함수를 사용할 수 있으며 대표적으로 Mean, Pool, LSTM 등이 있다.
Mean
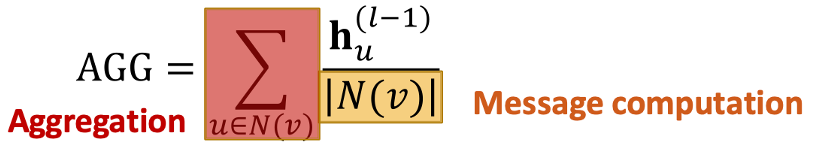
: 중심 노드의 degree로 normalize하여 message 계산 + 합하여 aggregation
Pool
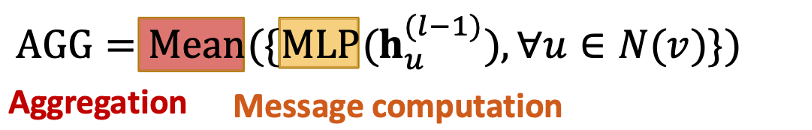
: MLP를 통과시켜 message 계산 + 평균(또는 최댓값)으로 aggregation
LSTM
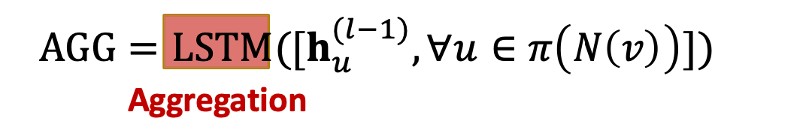
: LSTM으로 aggregation도 가능한데 이 경우에는 LSTM이 순서를 학습하는 모델이기 때문에 학습 과정에서 이웃 노드들의 순서를 섞어줘야 함..
2단계에서는 1단계에서 모은 이웃 노드들의 정보와 중심 노드의 정보를 concatenation하고, 그 결과에 선형 변환과 활성 함수를 적용한다.
추가적으로 GraphSAGE에서는 매 레이어를 통해 도출된 에 l2 normalization을 적용할 수 있다.
임베딩 벡터들의 분포가 너무 넓은 경우, l2 normalization을 통해 모든 노드 임베딩의 l2 norm이 같도록 만들어 성능을 향상시킬 수도 있다.
2.3. GAT (Graph Attention Networks)
GAT는 이웃 노드의 영향에 따라 다른 가중치를 적용하여 message aggregation을 수행하는 GNN 모델이다.
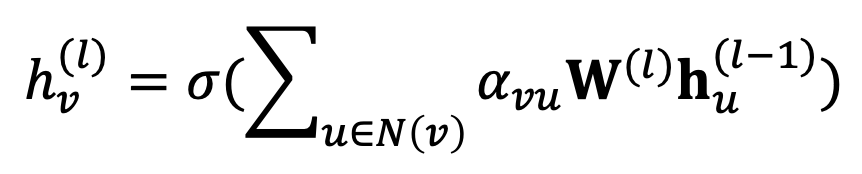
식을 살펴보면 전반적으로 GCN과 비슷한데 이 로 바뀌어 있다.
는 attention weights로 중심 노드 의 aggregation에서 이웃 노드 의 message를 얼마나 많이 반영시킬지를 나타낸다.
그렇다면 GCN에서는 attention weights가 모두 로 같다는 의미로 볼 수 있다. 즉, 이전 방식들에서는 aggregation에서 모든 이웃 노드들의 message를 동일하게 반영했음을 알 수 있다.
그러나 중심 노드 입장에서는 이웃 노드들이 모두 동일하게 느껴지지 않는다. 이웃 노드들마다 중요한 정도는 다르며, 이에 따라 더 중요한 이웃 노드의 정보를 더 많이 반영할 수 있도록 적절한 를 사용할 필요가 있다.
2.3.1. Attention Mechanism
그럼 이 는 어떻게 정해지느냐? 직역하자면 어텐션 메커니즘 의 '부산물'로 를 얻을 수 있다.
어텐션 메커니즘은 일종의 함수로 어텐션 계수 를 계산하는데, 이 가 바로 중심 노드 에 대한 이웃 노드 의 중요도이다.
는 중심 노드 에게 있어 이웃 노드들의 상대적인 중요도를 의미한다. 이에 따라 중심 노드 와 그 이웃 노드들 에 대해 의 합이 1이 되도록 소프트맥스 함수를 이용한다.
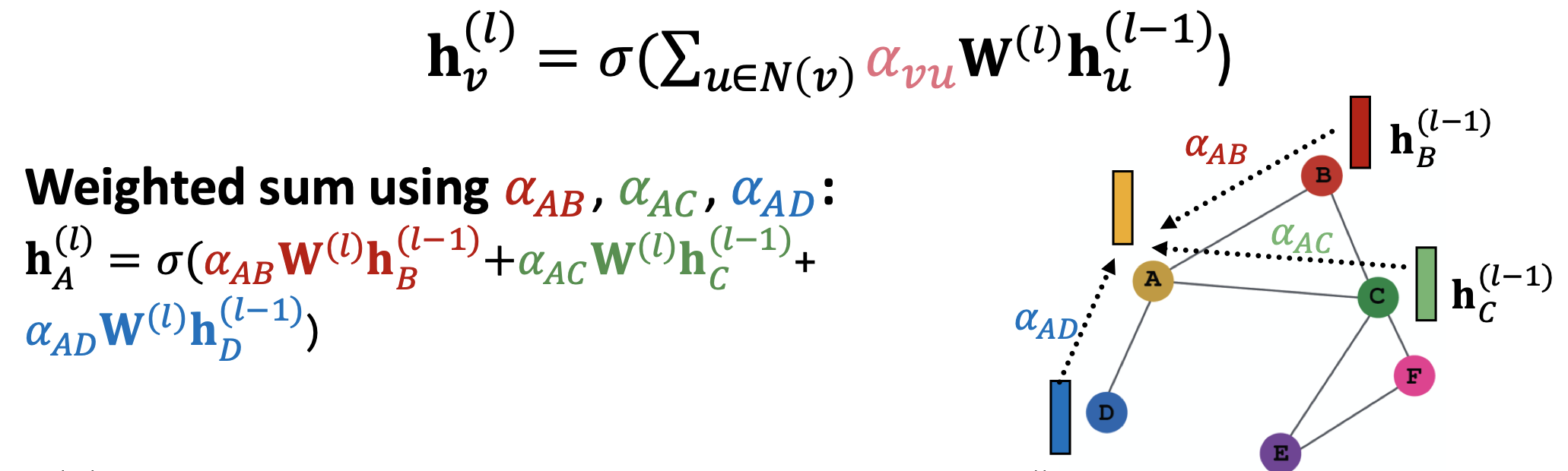
를 모두 구했다면 GAT의 식에 따라 가중합을 통해 aggregation을 진행한다.
한 가지를 빠트린 것 같다면 바로 일 것이다. 그래서 어떻게 를 구하는지가 정의되지 않았다.
일단 접근법 자체는 어텐션 메커니즘의 형태에 크게 구애받지 않는다. 어텐션 메커니즘의 파라미터도 전체 모델의 학습 과정에서 함께 업데이트 되기 때문이다. 따라서 어떤 함수를 쓰는지는 사용자가 지정하기 나름이다.
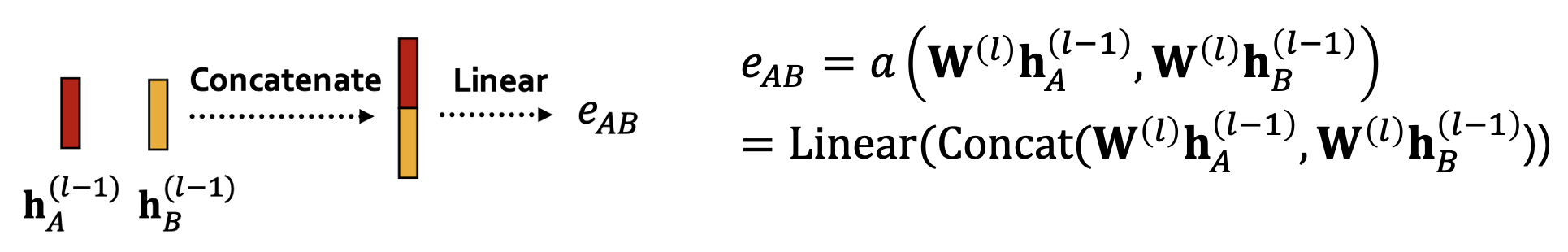
단순한 형태로는 입력된 두 벡터를 concatenation한 다음에 선형 변환 시키는 것이 있다.
2.3.2. Multi-head attention
의도한대로 전체 모델의 학습에서 어텐션 메커니즘의 파라미터도 최적화가 잘 이뤄지면 좋겠지만 그 과정이 꽤나 까다로운 듯하다. 그래서 multi-head attention을 통해 어텐션 메커니즘의 학습 과정을 안정시키고자 한다.
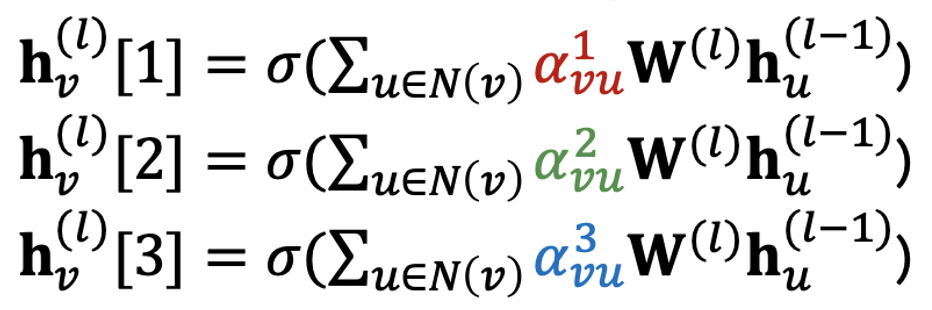
Multi-head attention은 파라미터가 각각 다르게 초기화 된 여러 개의 어텐션 메커니즘에 대해 동시에 학습을 진행한다. 이렇게 하면 하나의 어텐션 메커니즘이지만 각각 다른 를 도출할 수 있고 그에 따라 여러 개의 노드 임베딩을 얻을 수 있다.
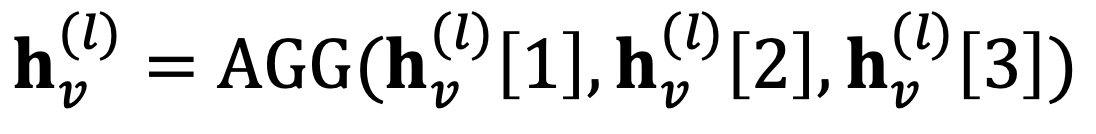
이후, 이렇게 얻어진 여러 개의 노드 임베딩을 하나로 합쳐 최종 임베딩을 계산한다.
각각의 어텐션 메커니즘은 local minima에 수렴할 수 있지만, 이들을 모두 합침으로써 전체 모델이 local minima에서 수렴하는 것을 막고 강건하게 만들 수 있다.
2.3.3. Benefits
이전 방식들과 달리 를 통해 이웃 노드들의 중요도를 다르게 고려하면 얻을 수 있는 이점이 몇 가지 있다.
- 효율적인 계산: 어텐션 계수의 계산은 모든 엣지에 대해 병렬로 계산될 수 있고, aggregation도 모든 노드에 대해 병렬로 계산될 수 있음
- 효율적인 저장 공간: 그래프의 크기와 상관없이 파라미터의 수는 고정적
- Localized: 이웃 노드들에만 집중
- Inductive capability: edge-wise 메커니즘으로 전체 그래프 구조와 상관없이 적용 가능
3. GNN Layer in Practice
2에서 다룬 클래식 GNN 레이어들을 바탕으로, 다른 딥러닝 모델들에서 사용되는 기법들을 적용하여 더 우수한 GNN 레이어를 디자인할 수도 있다.
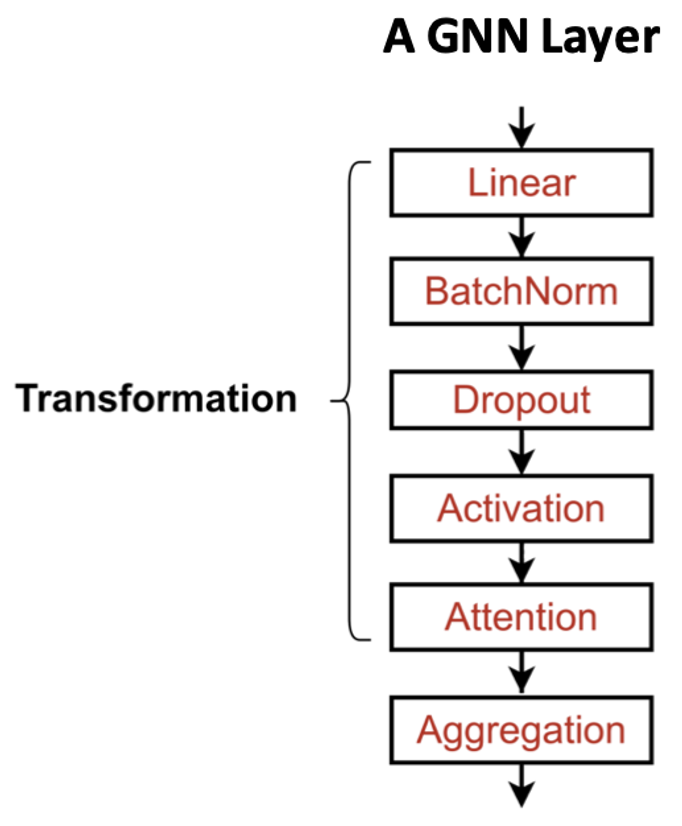
앞서 다룬 비선형 활성 함수나 어텐션 외에도 배치 정규화나 드롭아웃 등이 적용될 수 있다. 기법 자체의 적용 방식은 다른 딥러닝 모델에서와 크게 다르지 않다.
다만 이러한 기법들은 하나의 GNN 레이어가 있다고 치면, 주로 message를 계산하는 단계에서 적용된다.
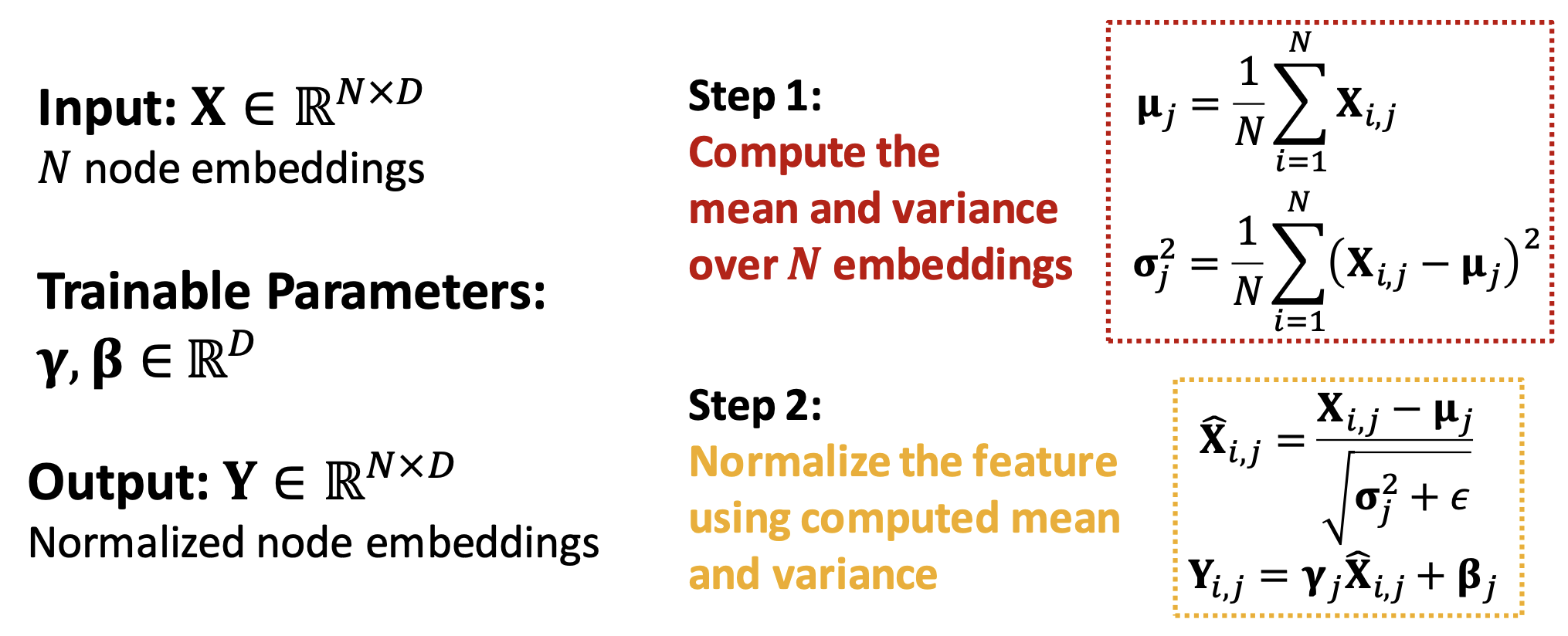
이를테면, 배치 정규화는 입력되는 노드 임베딩들의 분포를 조정한다.
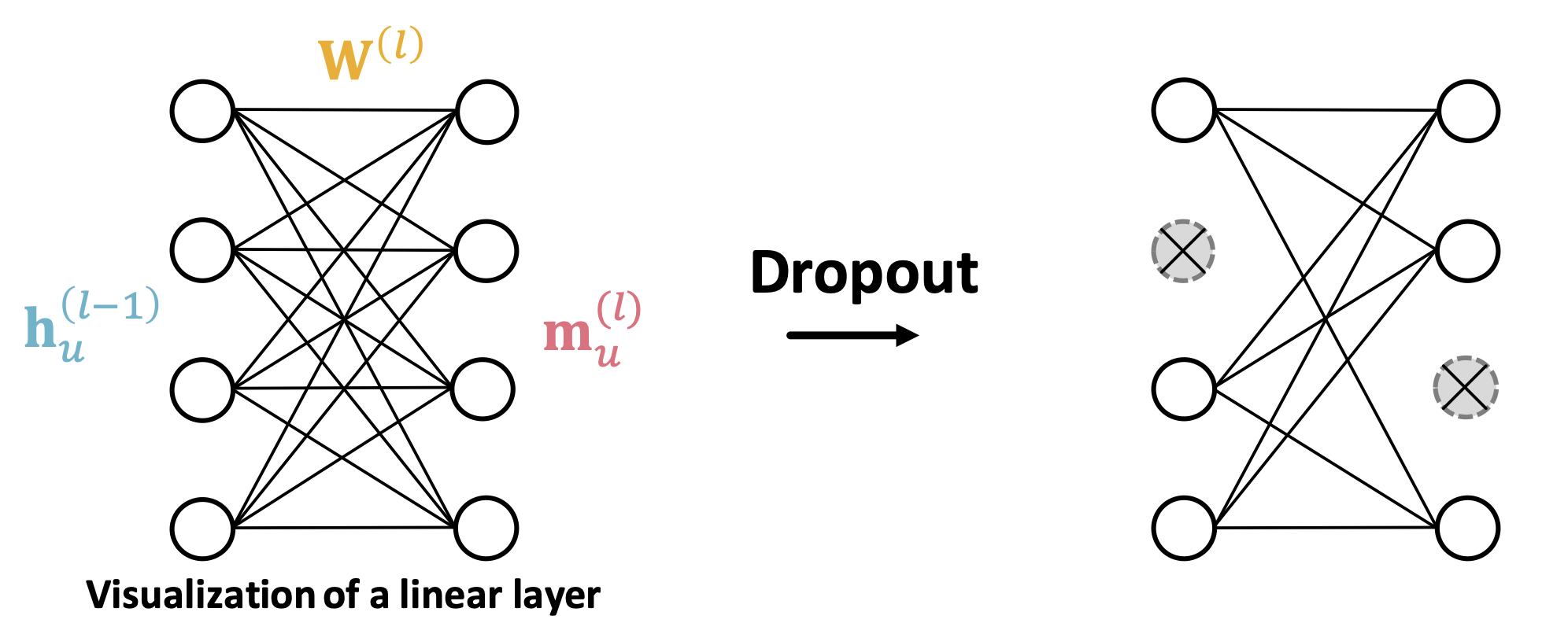
드롭아웃 역시 입력된 이전 레이어의 노드 임베딩을 선형 변환해서 message를 계산하는 과정에서 적용되는 방식이다.
