스터디 범위 20장 ~ 24장
참여자 총 7명
- @LIAM
- @BRANDON
- @CHRIS
- @LEO
- @PARKER
- @ODIN
- @BUZZ
@CHRIS
업무 규칙
업무 규칙은 사업적으로 수익을 얻거나 비용을 줄일 수 있는 규칙 또는 절차다.
자동화된 소프트웨어 시스템이 없더라도 그대로 존재한다.
핵심 업무 규칙과 핵심 업무 데이터(상품 - 상품 카달로그, 상품 카테고리)는 본질적으로 결합되어 있기 때문에 객체로 만들 좋은 후보가 된다.
이러한 유형의 객체를 엔티티Entity라고 하겠다.
- 엔티티 Entity 엔티티는 컴퓨터 시스템 내부의 객체로서, 핵심 업무 데이터를 기반으로 동작하는 일련의 조그만 핵심 업무 규칙을 구체화한다. 엔티티 객체는 핵심 업무 데이터를 직접 포함하거나 핵심 업무 데이터에 매우 쉽게 접근할 수 있다. 엔티티의 인터페이스는 핵심 업무 데이터를 기반으로 동작하는 핵심 업무 규칙을 구현한 함수들로 구성된다. 이 클래스는 데이터베이스, 사용자 인터페이스, 서드파티 프레임워크에 대한 고려사항들로 인해 오염되어서는 절대 안 된다.
엔티티는 순전히 업무에 대한 것이며, 이외의 것은 없다.(정말 strict 하게는 JPA 쓰는 것은 bad practice - 항상 protected no args constructor가 필요함) 참고) 좀 더 깊게 들어가서 Entity v.s. VO Entity vs Value Object: the ultimate list of differences
- 유스케이스 Use Cases 유스케이스는 사용자가 제공해야 하는 입력, 사용자에 보여줄 출력, 그리고 해당 출력을 생성하기 위한
처리 단계를 기술한다.

유스케이스는 엔티티 내부의 `핵심 업무 규칙을 어떻게, 그리고 언제 호출 할지를 명시하는 규칙`을 담는다.
엔티티가 어떻게 춤을 출지를 유스케이스가 제어하는 것이다.
⇒ 유스케이스는 업무 규칙을 직접 구현하지 않고 엔티티를 조합하여 하나의 트랜잭션 내에서 실행되어야할 일련의 과정을 만들어나간다.
유스케이스는 시스템에서 데이터가 들어오고 나가는 방식(사용자 인터페이스)은 유스케이스와는 무관하다.
엔티티는 자신을 제어하는 유스케이스에 대해 아무것도 알지 못한다. (Usecase → Entity)
- 엔티티와 같은 고수준 개념은 유스케이스와 같은 저수준 개념에 대해 아무것도 알지 못한다.
- 반대로 저수준인 유스케이스는 고수준인 엔티티에 대해 알고 있다.
(유스케이스는 엔티티보다 입출력에 가까우므로 상대적으로 저수준이다)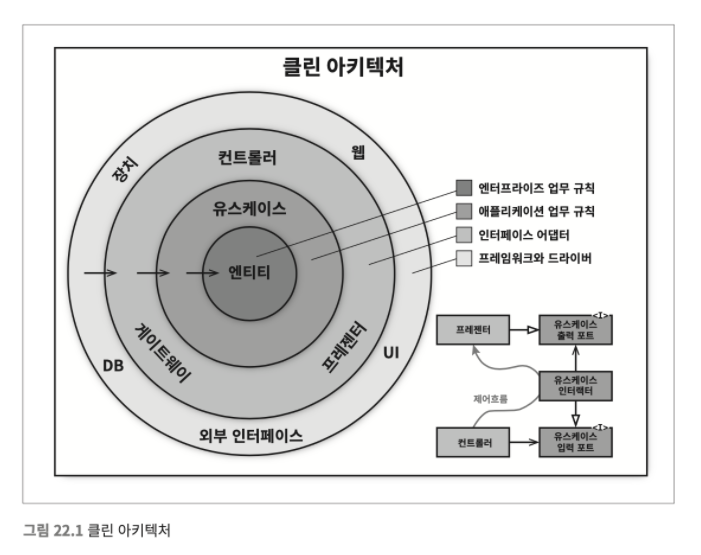
21. 소리치는 아키텍처
- 아키텍처의 테마 아키텍처는 프레임워크에 대한 것이 아니다(그리고
절대로그래서도 안 된다). 프레임워크는 사용하는 도구일 뿐, 아키텍처가 준수해야 할 대상이 아니다. 아키텍처를 프레임워크 중심으로 만들어버리면 유스케이스가 중심이 되는 아키텍처는 절대 나올 수 없다.
Spring Framework
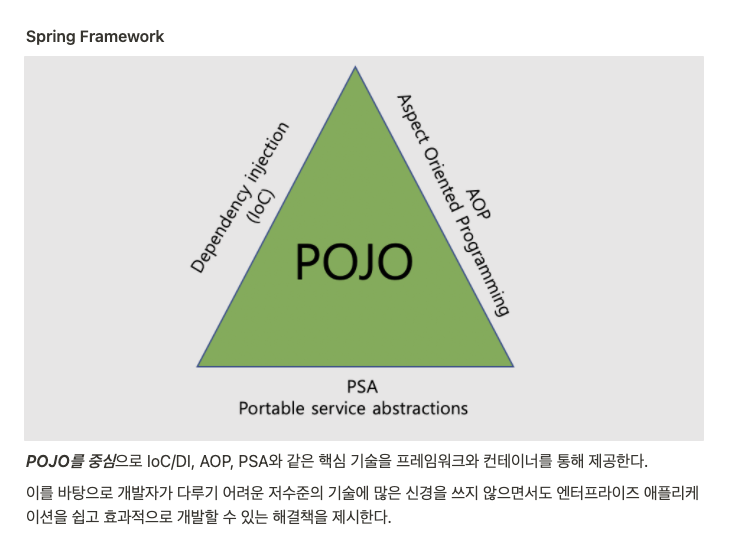
***POJO를 중심***으로 IoC/DI, AOP, PSA와 같은 핵심 기술을 프레임워크와 컨테이너를 통해 제공한다.
이를 바탕으로 개발자가 다루기 어려운 저수준의 기술에 많은 신경을 쓰지 않으면서도 엔터프라이즈 애플리케이션을 쉽고 효과적으로 개발할 수 있는 해결책을 제시한다.
**Nest.js**
> In recent years, thanks to Node.js, JavaScript has become the “lingua franca” of the web for both front and backend applications. This has given rise to awesome projects like **[Angular](https://angular.io/)**, **[React](https://github.com/facebook/react)** and **[Vue](https://github.com/vuejs/vue)**, which improve developer productivity and enable the creation of fast, testable, and extensible frontend applications. However, while plenty of superb libraries, helpers, and tools exist for Node (and server-side JavaScript), none of them effectively solve the main problem of - **Architecture**.
[https://docs.nestjs.com/](https://docs.nestjs.com/)
>
---- 아키텍처의 목적 좋은 소프트웨어 아키텍처는 프레임워크, 데이터베이스, 웹 서버, 그리고 여타
개발 환경 문제나 도구에 대해서는 결정을 미룰 수 있도록만든다. 뿐만 아니라 이러한 결정을 쉽게 번복할 수 있도록 한다. (plugin만 갈아끼면 되기 때문에) (SpringBoot의 경우 WAS로 Undertow를 쓴다고 할 경우 Tomcat dependency를 제거하고 Undertow dependency를 추가하면 된다, 번복도 동일하다) 좋은 아키텍처는 유스케이스에 중점을 두며, 지엽적인 관심사에 대한 결합은 분리시킨다.
- 프레임워크는 도구일 뿐, 삶의 방식은 아니다 어떻게 하면 아키텍처를 유스케이스에 중점을 둔 채 그대로 보존할 수 있을지를 생각하라. 프레임워크가 아키텍처의 중심을 차지하는 일을 막을 수 있는 전략을 개발하라. Sequelize vs TypeORM (프레임워크 기반으로 개발을 하기 때문에 해당 프레임워크를 어느정도 잘 알아야할 필요는 있고 해당 프레임워크의 철학을 어느정도 따르는 것이 해당 프레임워크 개발자 끼리 컨벤션이 맞춰지기도 하지만 프레임워크에 너무 종속되면 해당 프레임워크를 잘 알지못하면 코드를 이해하지 못하는 코드가 나올 수 있다)
- 테스트하기 쉬운 아키텍처 아키텍처가 유스케이스를 최우선으로 한다면, 그리고 프레임워크와는 적당 한 거리를 둔다면, 프레임워크를 전혀 준비하지 않더라도 필요한 유스케이스 전부에 대해
단위 테스트를 할 수 있어야 한다. → 테스트를 돌리는 데 웹 서버/데이터베이스가 반드시 필요한 상황이 되어서는 안 된다.프레임워크로 인한 어려움을 겪지 않고도반드시 이 모두를 있는 그대로 테스트할 수 있어야 한다.
22. 클린 아키텍처
- 육각형 아키텍처Hexagonal Architecture
- DCI Data, Context and Interaction
- BCE Boundary-Control-Entity 이들 아키텍처는 모두 세부적인 면에서는 다소 차이가 있더라도 그 내용은 상당히 비슷하다. 이들의 목표는 모두 같은데, 바로
관심사의 분리separation of concerns다. 이들은 모두소프트웨어를 계층으로 분리함으로써 관심사의 분리라는 목표를 달성할 수 있었다.
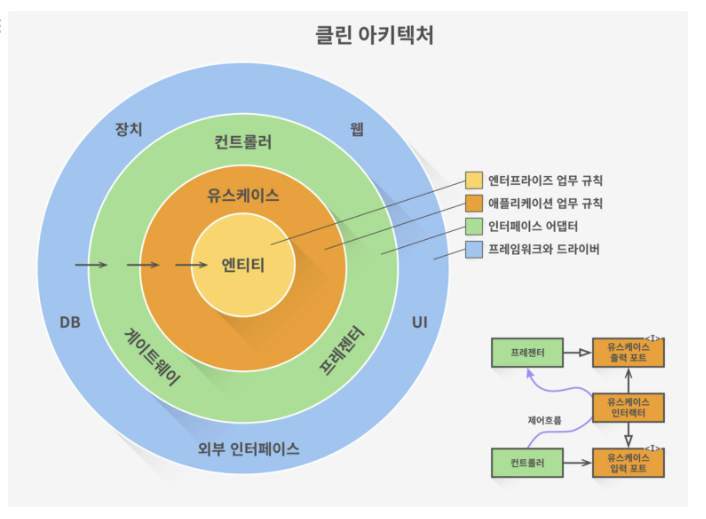
아래 다이어그램은 이들 아키텍처 전부를 실행 가능한 하나의 아이디어로 통합하려는 시도다.
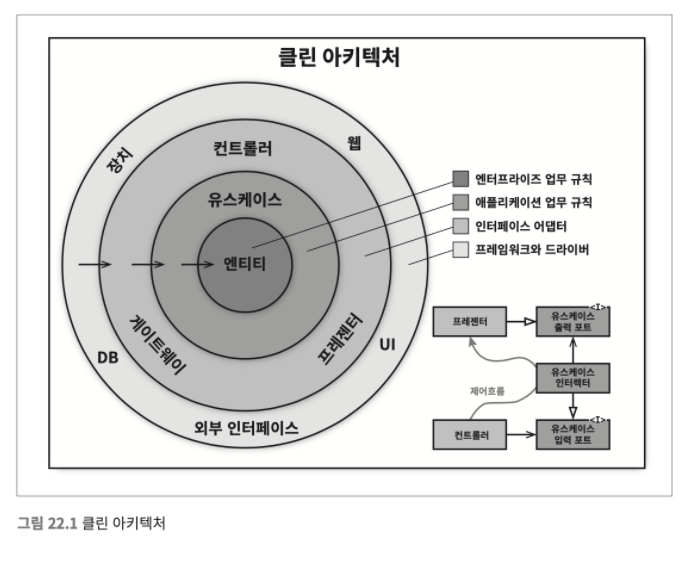
- 의존성 규칙 소스 코드 의존성은 반드시 안쪽으로, 고수준의 정책을 향해야 한다. (역참조를 허락하지 않는다) 내부의 원에 속한 코드는 외부의 원에 선언된 어떤 것에 대해서도 그 이름(함수, 클래스, 변수...)을 언급해서는 절대 안 된다.
- 엔티티 엔티티는 전사적인
핵심 업무 규칙을 캡슐화한다. 엔티티는 메서드를 가지는 객체이거나 일련의 데이터 구조와 함수의 집합일 수도 있다. 운영 관점에서 특정 애플리케이션에 무언가 변경이 필요하더라도 엔티티 계층에는 절대로 영향을 주어서는 안 된다.
- 유스케이스 유스케이스 계층의 소프트웨어는 애플리케이션에 특화된 업무 규칙을 포함한다. 또한 유스케이스 계층의 소프트웨어는
시스템의 모든 유스케이스를 캡슐화하고 구현한다. 유스케이스는 엔티티로 들어오고 나가는 데이터 흐름을 조정하며, 엔티티가 자신의 핵심 업무 규칙을 사용해서 유스케이스의 목적을 달성하도록 이끈다. 운영 관점에서 애플리케이션이 변경된다면 유스케이스가 영향을 받으며, 따라서 이 계층의 소프트웨어에도 영향을 줄 것이다. 유스케이스의 세부사항이 변하면 이 계층의 코드 일부는 분명 영향을 받을 것이다. (회원가입 후 메일로 환영 메시지를 보내야한다로 기능이 추가될 때, 엔티티는 변경되지 않지만 유스케이스에 변경이 생긴다)
- 인터페이스 어댑터 Interface Adaptor 데이터를 유스케이스와 엔티티에게 가장 편리한 형식에서 데이터베이스나 웹 같은 외부 에이전시에게 가장 편리한 형식으로 변환한다. (유스케이스 입/출력 → 인터페이스 어뎁터 → 인터페이스 입출력) e.g.) 이 계층은 데이터를 엔티티와 유스케이스에게 가장 편리한 형식에서 영속성용으로 사용 중인 임의의 프레임워크(즉, 데이터베이스)가 이용하기에 가장 편리한 형식으로 변환한다.
- 프레임워크와 드라이버 프레임워크와 드라이버 계층은 웹, 데이터베이스와 같은 모든 세부사항이 위치하는 곳이다. 우리는 이러한 것들을 모두
외부에 위치시켜서 피해를 최소화한다.
원은 꼭 네 개일 필요는 없으나 어떤 경우에도 의존성 규칙은 적용된다.
- 경계를 횡단하는 데이터는 어떤 모습인가 기본적인 구조체(Map 등)나 간단한 데이터 전송 객체DTO 등 원하는 대로 고를 수 있다. 중요한 점은 격리되어 있는 간단한 데이터 구조가 경계를 가로질러 전달된다는 사실이다. 우리는 데이터 구조가 어떤 의존성을 가져 의존성 규칙을 위배하게 되는 일은 바라지 않는다. 경계를 가로질러 데이터를 전달할 때, 데이터는 항상 내부의 원에서 사용하기에 가장 편리한 형태를 가져야만 한다. (Controller에서 HTTP Header 데이터를 UseCase에 전달하는 것은 적절하지 않다)
- 전형적인 시나리오 (복습하면서 확인해보세요~)
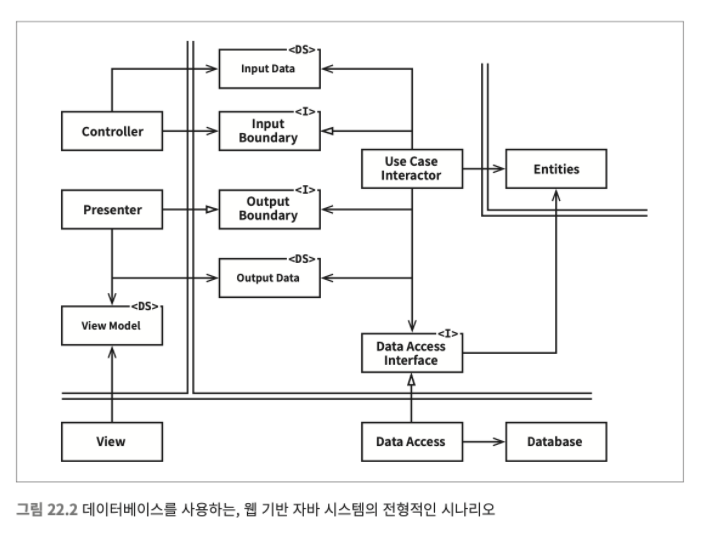
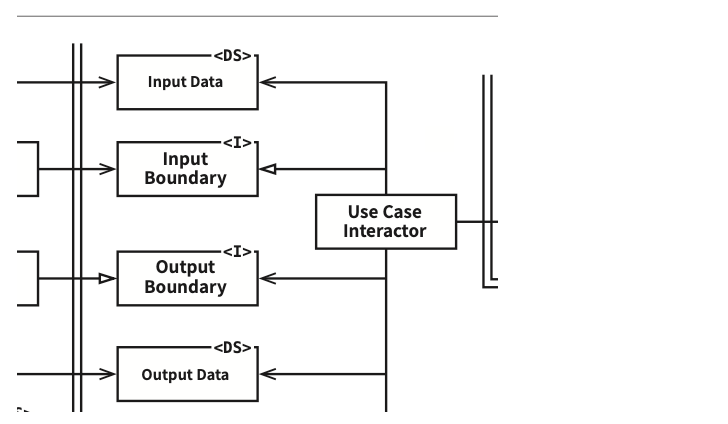
- 웹 서버는 사용자로부터
입력데이터를 모아서 좌측 상단의 Controller로 전달한다. - Controller는 데이터를 평범한 자바 객체POJO로 묶은 후, InputBoundary 인터페이스를 통해 UseCaseInteractor로 전달한다.
- UseCaseInteractor는 이 데이터를 해석해서 Entities가 어떻게 춤 출지를 제어하는 데 사용한다. 또한 UseCaseInteractor는 DataAccessInterface 를 사용하여 Entities가 사용할 데이터를 데이터베이스에서 불러와서 메모리로 로드한다. Entities가 완성되면, UseCaseInteractor는 Entities로부터 데이터를 모아서 또 다른 평범한 자바 객체인 OutputData를 구성한다.
- OutputData는 OutputBoundary 인터페이스를 통해 Presenter로 전달된다.
- Presenter가 맡은 역할은 OutputData를 ViewModel과 같이 화면에 출력 할 수 있는 형식으로 재구성하는 일이다. ViewModel 또한 평범한 자바 객체다.
- View에서는 이 데이터를 화면에 출력한다.
- Presenter는 ViewModel을 로드할 때 Date와 같은 객체를 사용자가 보기에 적절한 형식의 문자열로 변환한다. 따라서 ViewModel에서 HTML 페이지로 데이터를 옮기는 일을 빼면, View에서 해야 할 일은 거의 남아 있지 않다. (View를 위한 데이터 변환 처리는 Presenter에서 하기 때문에)
23. 프레젠터와 험블 객체
- 험블 객체 패턴
험블 객체 패턴은 디자인 패턴으로, 테스트하기 어려운 행위와 테스트하기 쉬운 행위를 단위 테스트 작성자가 분리하기 쉽게 하는 방법으로 고안되었다. 가장 기본적인 본질은 남기고, 테스트하기 어려운 행위를 모두 험블 객체로 옮긴다. 나머지 모듈에는 험블 객체에 속하지 않은, 테스트하기 쉬운 행위를 모두 옮긴다.
- 프레젠터와 뷰
- 프레젠터는 테스트하기 쉬운 객체다. 프레젠터의 역할은 애플리케이션으로부터 데이터를 받아 화면에 표현할 수 있는 포맷으로 만드는 것이다. (애플리케이션 → 프레젠터 → 뷰 → GUI) 이를 통해 뷰는 데이터를 화면으로 전달하는 간단한 일만 처리하도록 만든다.
- 뷰는 험블 객체이고 테스트하기 어렵다. 이 객체에 포함된 코드는 가능한 한 간단하게 유지한다. 뷰는 데이터를 GUI로 이동시키지만, 데이터를 직접 처리하지는 않는다.
- 프레젠터는 테스트하기 쉬운 객체다. 프레젠터의 역할은 애플리케이션으로부터 데이터를 받아 화면에 표현할 수 있는 포맷으로 만드는 것이다. (애플리케이션 → 프레젠터 → 뷰 → GUI) 이를 통해 뷰는 데이터를 화면으로 전달하는 간단한 일만 처리하도록 만든다.
e.g.)
애플리케이션은 프레젠터에 Currency 객체를 전달한다.
프레젠터는 해당 객체를 소수점 과 통화 표시가 된 포맷으로 적절하게 변환하여 문자열을 생성한 후 뷰 모델 에 저장한다.
뷰는 뷰 모델의 데이터를 화면으로 로드할 뿐이며, 이 외에 뷰가 맡은 역할은 전혀 없다.
따라서 뷰는 보잘것없다humble.
- 서비스 리스너 (서비스 간 통신) 애플리케이션은 데이터를 간단한 데이터 구조 형태로 로드한 후, 이 데이터 구조를 경계를 가로질러서 특정 모듈로 전달한다. 그러면 해당 모듈은 데이터를 적절한 포맷으로 만들어서 외부 서비스로 전송한다. (애플리케이션 == 데이터 구조 ==> 특정 모듈 == 통신할 수 있는 포맷의 데이터 ==> 외부 서비스)
반대로 외부로부터 데이터를 수신하는 서비스의 경우, 서비스 리스너service listener가 서비스 인터페이스로부터 데이터를 수신하고, 데이터를 애플리케이션에서 사용할 수 있게 간단한 데이터 구조로 포맷을 변경한다.
(서비스 인터페이스 == 수신받은 데이터 ==> 서비스 리스너 == 애플리케이션에서 사용할 수 있는 포맷의 데이터 ==> 애플리케이션)
그런 후 이 데이터 구조는 서비스 경계를 가로질러서 내부로 전달된다.
경계를 넘나드는 통신은 거의 모두 간단한 데이터 구조를 수반할 때가 많고, 대개 그 경계는 테스트하기 어려운 무언가와 테스트하기 쉬운 무언가로 분리될 것이다.
그리고 이러한 아키텍처 경계에서 험블 객체 패턴을 사용하면 전체 시스템의 테스트 용이성을 크게 높일 수 있다.
24. 부분적 경계
애자일 커뮤니티에 속한 사람 중 많은 이가 엄청난 노력을 기울여야하는 "완벽한" 선행적인 설계를 탐탁치 않게 여기는데,
YAGNI(You Aren’t Going to Need It) 원칙을 위배하기 때문이다.
하지만 아키텍트라면 이 문제를 검토하면서 그래, 하지만 어쩌면 필요 할지도.라는 생각이 들 수도 있다. 🤔
만약 그렇다면 부분적 경계partial boundary를 구현해볼 수 있다.
When do you need a persistence model?
- 마지막 단계를 건너뛰기 부분적 경계를 생성하는 방법 하나는 독립적으로 컴파일하고 배포할 수 있는 컴포넌트를 만들기 위한 작업은 모두 수행한 후, 단일 컴포넌트에 그대로 모아만 두는 것이다. (모듈은 나누되 단일 애플리케이션에 모든 모듈을 담아 사용하기) 쌍방향 인터페이스도 그 컴포넌트에 있고, 입력·출력 데이터 구조도 거기에 있으며, 모든 것이 완전히 준비되어 있다. 하지만 이 모두를
단일 컴포넌트로 컴파일해서 배포한다. (경계만 나누되 이를 컴포넌트 형식으로 분리하진 않는다)
추적을 위한 버전 번호도 없으며, 배포 관리 부담도 없다.
⇒ 이 차이는 가볍지 않다.
- 일차원 경계 완벽한 형태의 아키텍처 경계는 양방향으로 격리된 상태를 유지해야 하므로 쌍방향 Boundary 인터페이스를 사용한다
하지만 양방향으로 격리된 상태를 유지하 려면 초기 설정할 때나 지속적으로 유지할 때도 비용이 많이 든다.
추후 완벽한 형태의 경계로 확장할 수 있는 공간을 확보하고자 할 때 활용할 수 있는 더 간단한 구조가 아래에 나와 있다.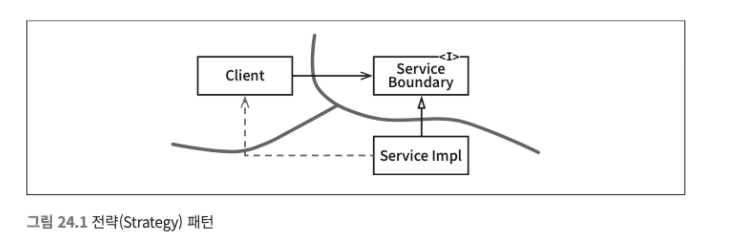
Client를 ServiceImpl로부터 격리시키는 데 필요한 의존성 역전이 이미 적용되었기 때문에
이 방식이 미래에 필요할 아키텍처 `경계`를 위한 무대를 마련한다는 점은 명백하다.
하지만 쌍방향 인터페이스가 없고 개발자와 아키텍트가 근면 성실하고 제대로 훈련되어 있지 않다면, 이 점선과 같은 비밀 통로가 생기는 일을 막을 방법이 없다.
(의존의 방향이 무너지기 쉬운 구조이다)- Facade 클라이언트는 서비스 클래스에 직접 접근할 수 없되, Facade 클래스에 모든 서비스 클래스를 메서드 형태로 정의하고, 서비스 호출이 발생하면 해당 서비스 클래스로 호출을 전달한다.

하지만 Client가 이 모든 서비스 클래스에 대해 추이 종속성을 가지게 되었다.각 접근법은 완벽한 형태의 경계를 담기 위한 공간으로써, 적절하게 사용할 수 있는 상황이 서로 다르다.
아키텍처 경계가 언제, 어디에 존재해야 할지, 그리고 그 경계를 완벽하게 구현할지 아니면 부분적으로 구현할지를 결정하는 일 또한 아키텍트의 역할이다.
@BUZZ
- 20 업무 규칙
엔티티
엔티티는 핵심 업무 데이터를 기반으로 동작하는 일련의 조그만 핵심 업무 규칙을 구체화한다. 엔티티의 인터페이스는 핵심 업무 데이터를 기반으로 동작하는 핵심 업무 규칙을 구현한 함수들로 구성된다. 이러한 종류의 클래스를 생성할 때, 업무에서 핵심적인 개념을 구현하는 소프트웨어는 한데 모으고, 구축 중인 자동화 시스템의 나머지 모든 고려사항과 분리시킨다.-
Entity
- 핵심 업무 규칙을 캡슐화한다
- 메서드가 있는 객체이거나 데이터 구조 및 함수의 집합일 수 있다.
- 특정 애플리케이션에 대한 운영 변경은 엔티티 계층에 영향을 주지 않아야 할 정도로, 가장 변하지 않고, 외부로부터 영향을 받지 않는 영역유스케이스
유스케이스는 시스템이 사용자에게 어떻게 보이는지를 설명하지 않는다. 이보다는 애플리케이션에 특화된 규칙을 설명하며, 이를 통해 사용자와 엔티티 사이의 상호작용을 규정한다.
엔티티는 자신을 제어하는 유스케이스에 대해 아무것도 알지 못한다. 엔티티와 같은 고수준 개념은 유스케이스와 같은 저수준 개념에 대해 아무것도 알지 못한다. 왜냐하면 유스케이스는 단일 애플리케이션에 특화되어 있으며, 따라서 해당 시스템이 입력과 출력에 보다 가깝게 위치하기 때문이다. 엔티티는 수많은 다양한 애플리케이션에서 사용될 수 있도록 일반화된 것이므로, 각 시스템의 입력이나 출력에서 더 멀리 떨어져 있다.
-
UseCase
- 애플리케이션에 해당하는 비즈니스 규칙이 포함되어 있다.
- 사용 사례를 캡슐화하고 구현한다.
- 변경해도 엔티티에 영향을 주지 않고, 외부요소(데이터베이스, UI, 프레임워크 등)에 영향을 받지 않는다.요청 및 응답 모델
유스케이스는 단순한 요청 데이터 구조를 입력으로 받아들이고, 단순한 응답 데이터 구조를 출력으로 반환한다. 이들 데이터 구조는 어떤 것에도 의존하지 않는다.
시간이 지나면 엔티티와 요청/응답 모델은 완전히 다른 이유로 변경될 것이고, 따라서 어떤 식으로든 함께 묶는 행위는 공통 폐쇄 원칙과 단일 책임 원칙을 위배하게 된다.
-
- 21 소리치는 아키텍처
건물의 계획서만 보아도 주택인지 도서관인지 알 수 있다.
당신의 프로젝트를 볼때 아키텍처는 뭐라고 소리치는가?아키텍처의 목적
좋은 아키텍처는 유스케이스를 그 중심에 두기 때문에, 프레임워크나 도구, 환경에 전혀 구애받지 않고 유스케이스를 지원하는 구조를 아무런 문제 없이 기술할 수 있다. 다시 주택을 예로 들어보면 거주에 적합한 공간임이 중심이 되어야지 벽돌인지 대리석인지는 중요하지 않다. 좋은 아키텍쳐는 유스케이스에 중점을 두며, 지엽적인 관심사에 대한 결합은 분리시킨다.프레임워크는 도구일 뿐, 삶의 방식이 아니다
프레임워크를 면밀하고 비판적으로 보자.-
이들을 사용하지 않거나 다르게 사용하여 유스케이스에 중점을 둔 아키텍쳐를 그대로 보존할 수 있을지 고민하라.
-
프레임워크가 아키텍쳐의 중심을 차지하지 않도록 해라.
결론
-
아키텍쳐는 시스템을 이야기해야하며 시스템에 적용된 프레임워크에 대해 이야기해서는 안된다.
-
그래서 새로 합류한 프로그래머도 시스템의 세부 사항을 몰라도 모든 유스케이스를 이해할 수 있어야 한다.
-
- 22 클린 아키텍처
-
지난 수십 년간의 다양한 시스템 아키텍쳐 아이디어
- 육각형 아키텍쳐 (Hexagonal Architecture) : 앨리스터 코오번, Known as 포트와 어댑터 (Ports and Adapters)
- DCI (Data, Context and Interaction) : 제임스 코플리언과 트리그베 린스쿠주
- BCE (Boundary-Control-Entity) : 이바 야콥슨, Object Oriented Software Engineering
-
이들의 목표는 모두 관심사의 분리.
-
소프트웨어를 계층으로 분리하여 관심사의 분리라는 목표를 달성.
-
이들은 업무 규칙을 위한 계층 1개와 사용자 인터페이스를 위한 계층 1개를 반드시 포함.
특징
- 프레임워크 독립성 : 프레임 워크의 존재 여부에 의존하지 않고 그들의 제약사항에도 얽메이지 않아.
- 테스트 용이성 : 업무 규칙은 UI, 데이터베이스, 웹서버 등 외부 요소가 없이도 테스트 가능.
- UI 독립성 : 시스템의 나머지 부분을 변경치 않고 UI를 쉽게 변경할 수 있다. 웹을 앱으로 전환도 가능.
- 데이터베이스 독립성 : 데이터베이스와 결합되지 않아 언제든지 데이터베이스를 교체할 수 있다.
- 모든 외부 에이전시에 대한 독립성 : 업무 규칙은 외부 세계와의 인터페이스에 대해 전혀 알지 못한다
-
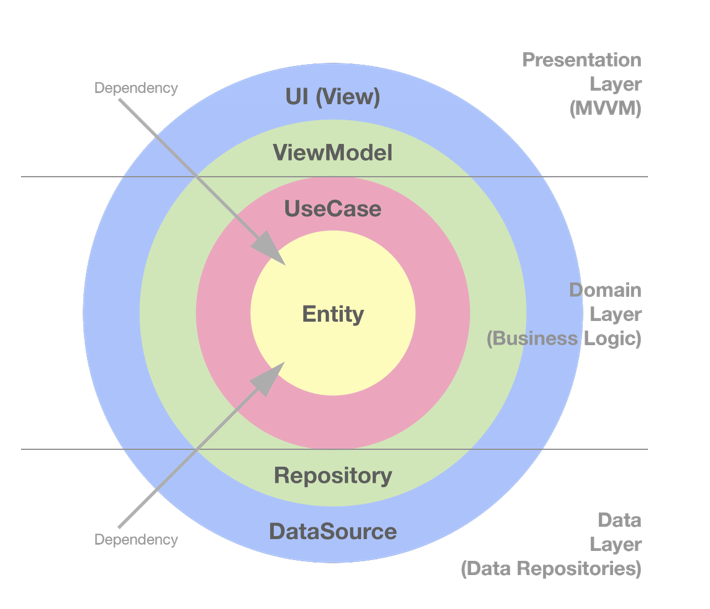
Clean Architecture and MVVM on iOS
### 엔티티
- 핵심 업무 규칙을 캡슐화한다.
- 메서드를 가지는 객체 거나 일련의 데이터 구조와 함수의 집합일 수 있다.
- 가장 변하지 않고, 외부로부터 영향받지 않는 영역이다.
### 유스 케이스
- 애플리케이션에 특화된 업무 규칙을 포함한다.
- 시스템의 모든 유스 케이스를 캡슐화하고 구현한다.
- 엔티티로 들어오고 나가는 데이터 흐름을 조정하고 조작한다.
### 인터페이스 어댑터
- 일련의 어댑터들로 구성된다.
- 어댑터는 데이터를 (유스 케이스와 엔티티에게 가장 편리한 형식) <-> (데이터베이스나 웹 같은 외부 에이전시에게 가장 편리한 형식)으로 변환한다.
- 컨트롤러, 프레젠터, 게이트웨이 등이 여기에 속한다.
### 프레임워크와 드라이버
- 시스템의 핵심 업무와는 관련 없는 세부 사항이다. 언제든 갈아 끼울 수 있다.
- 프레임워크나, 데이터베이스, 웹서버 등이 여기에 해당된다.
영역은 상황에 따라 4가지 이상일 수 있다.핵심은 안쪽 영역으로 갈수록 추상화와 정책의 수준이 높아진다는 것이다.반대로 바깥쪽 영역으로 갈수록 구체적인 세부사항으로 구성된다.(그래서 안쪽 영역을 갈수록 고수준이라 하며, 바깥쪽으로 갈수록 저수준이라고 한다.)
클린 아키텍처에서 아주 **핵심적인 원칙이 바로 이 의존성 방향에 있다.**
> 의존성 방향은 항상 바깥쪽 원에서 안쪽 원으로 향해야 한다.
>
아주 명확한 원칙이다. 컴포넌트를 위 영역 중 어디에 위치시키지? 컴포넌트 간 관계를 어떻게 맺지? 에 대한 생각이 들 때, 이 원칙만 잘 지키면 된다. 다시 한번 말하지만, 안쪽 영역에 있는 컴포넌트는 바깥쪽 영역의 컴포넌트를 알아서도 안되고, 변경에 따라 영향받지도 않아야 한다.
그런데 의존성의 방향과 제어 흐름이 명백히 반대인 경우가 있다. 예를 들어, 유스 케이스에서 프레젠터를 호출해야하는 경우다. 의존성의 방향 원칙대로라면 프레젠터 -> 유스케이스의 흐름인데, 제어흐름은 유스케이스 -> 프레젠터로 가기 때문이다.
- 클린아키텍처 코드
```swift
import UIKit
//MARK: - Presenter Layer
// DailyWeatherView.swift
public struct DailyWeatherView: View {
@ObservedObject public var viewModel: DailyWeatherViewModel
public init(viewModel: DailyWeatherViewModel) {
self.viewModel = viewModel
}
public var body: some View {
ScrollView() {
Text("Daily Weather")
.font(.title)
.fontWeight(.bold)
Spacer(minLength: 20)
VStack(spacing: 40) {
ForEach(self.viewModel.dailyWeather) { weather in
WeatherView(icon: weather.icon, location: weather.location, temperature: weather.temperature, date: weather.date)
}
}
}
.padding(EdgeInsets(top: 20, leading: 0, bottom: 0, trailing: 0))
.onAppear {
self.viewModel.executeFetch()
}
}
}
// DailyWeatherViewModel.swift
import DomainLayer
public protocol DailyWeatherViewModelInput {
func executeFetch()
}
public protocol DailyWeatherViewModelOutput {
var dailyWeather: [WeatherEntity] { get }
}
public final class DailyWeatherViewModel: ObservableObject, DailyWeatherViewModelInput, DailyWeatherViewModelOutput {
private let useCase: FetchDailyWeatherUseCaseInterface
private var bag: Set<AnyCancellable> = Set<AnyCancellable>()
@Published public var dailyWeather: [WeatherEntity] = []
public init(useCase: FetchDailyWeatherUseCaseInterface) {
self.useCase = useCase
}
public func executeFetch() {
useCase.execute()
.sink { completion in
switch completion {
case .finished:
break
case .failure(_):
self.dailyWeather = []
}
} receiveValue: { weatherList in
self.dailyWeather = weatherList
}
.store(in: &bag)
}
}
//MARK: - Domain Layer
// WeatherEntity.swift
public struct WeatherEntity: Identifiable {
public let id: String
public let icon: String
public let location: String
public let temperature: Float
public let description: String
public let date: Date
public init(id: String, icon: String, location: String, temperature: Float, description: String, date: Date)
{
self.id = id
self.icon = icon
self.location = location
self.temperature = temperature
self.description = description
self.date = date
}
}
// FetchDailyWeatherUseCase.swift
public protocol FetchDailyWeatherUseCaseInterface {
func execute() -> AnyPublisher<[WeatherEntity], Error>
}
public final class FetchDailyWeatherUseCase: FetchDailyWeatherUseCaseInterface {
private let repository: WeatherRepositoryInterface
public init(repository: WeatherRepositoryInterface) {
self.repository = repository
}
public func execute() -> AnyPublisher<[WeatherEntity], Error> {
return repository.fetchDailyWeather()
}
}
public protocol WeatherRepositoryInterface {
func fetchDailyWeather() -> AnyPublisher<[WeatherEntity], Error>
}
//MARK: - Data Layer
// WeatherRepository.swift
import DomainLayer
public final class WeatherRepository: WeatherRepositoryInterface {
private let dataSource: WeatherDataSourceInterface
public init(dataSource: WeatherDataSourceInterface) {
self.dataSource = dataSource
}
public func fetchDailyWeather() -> AnyPublisher<[WeatherEntity], Error> {
return dataSource.fetchDailyWeather()
.map({ weatherDTOList in
var weatherEntities = [WeatherEntity]()
for weather in weatherDTOList {
weatherEntities.append(weather.dto())
}
return weatherEntities
})
.eraseToAnyPublisher()
}
}
// WeatherDTO.swift (DataModel & DTO(Data Transfer Object))
import DomainLayer
public struct WeatherDTO: Codable {
let weather: WeatherDataDTO
let main: WeatherMainDTO
let name: String
let dt: TimeInterval
// DTO: Data Transfer Object
public func dto() -> WeatherEntity {
return WeatherEntity(id: UUID().uuidString, icon: weather.icon, location: name, temperature: Float(main.temp), description: weather.description, date: Date(timeIntervalSince1970: dt))
}
}
public struct WeatherDataDTO: Codable {
let main: String
let description: String
let icon: String
}
public struct WeatherMainDTO: Codable {
let temp: Double
let temp_min: Double
let temp_max: Double
}
```
https://tech.olx.com/clean-architecture-and-mvvm-on-ios-c9d167d9f5b3
- 23 프레젠터와 험블 객체 험블객체(Humble Object) 패턴 bliki: HumbleObject
-
행위를 두개의 모듈 또는 클래스로 나눔, 그중하나가 험블
-
테스트하기 어려운 행위를 험블 객체로 옮기고, 나머지 모듈에는 테스트하기 쉬운 행위를 옮김
프레젠터와 뷰
뷰는 험블객체이고 테스트하기 어렵다.
-
뷰는 데이터를 GUI로 이동시키지만, 데이터를 직접 처리하지 않는다.
프레젠터는 테스트하기 쉬운 객체다.
-
프레젠터의 역할은 애플리케이션(server)으로부터 데이터를 받아 화면에 표현할 수 있는 포맷으로 만드는 것이다.
-
따라서 뷰는 데이터를 건들지 않고 화면으로 전달하기만 하면 된다.
예를 들어 특정 부분에 날짜를 표시하고자 한다면, 애플리케이션(server)은 프레젠터에 Date 객체를 전달한다. 그 다음 프레젠터는 해당 데이터를 적절한 포맷의 문자열로 만들고, 이 문자열을 뷰 모델(view model)이라고 부르는 간단한 데이터 구조에 담는다. 그러면 뷰는 뷰 모델에서 이 데이터를 찾는다.
-
폰트 색깔을 상황에 따라 바꾼다는 등 상황에선 불(boolean) 타입 플래그를 뷰 모델에 두고 적절한 값으로 설정한다(문자열, 열거형(enum) 형태).
-
뷰는 뮤 모델의 데이터를 화면으로 로드할 뿐, 아무 역할이 없다.
- 보잘것 없다(humble).테스트와 아키텍처
테스트가하기 쉬운 구조는 아키텍처가 필수로 지녀야 한다.
-
험블 객체 패턴이 좋은 예인데, 행위를 테스트하기 쉬운 부분과 어려운 부분으로 분리하면 아키텍처 경계가 정의되기 때문이다.
-
프레젠터와 뷰 사이의 경계는 이러한 경계중 하나이며, 수많은 경계가 존재한다.
데이터베이스 게이트웨이
유스케이스 인터랙터와 데이터베이스 사이에는 데이터베이스 게이트웨이가 존재한다.
-
이 게이트웨이는 다형적 인터페이스로, 애플리케이션이 데이터베이스에 수행하는 CRUD 작업과 관련된 모든 메서드를 포함한다(Spring JPA 등).
유스케이스 계층은 SQL을 허용하지 않는다.
-
그러므로 유스케이스 계층은 필요한 메서드를 제공하는 게이트웨이 인터페이스를 호출한다.
-
인터페이스의 구현체(험블 객체)는 데이터베이스 계층에 위치한다.
-
구현체에서 직접 SQL을 사용하거나 데이터베이스에 대한 임의의 인터페이스를 통해 게이트웨이의 메서드에 필요한 데이터에 접근한다.
이와 달리 인터랙터는 애플리케이션에 특화된 업무 규칙을 캡슐화 하기 때문에 험블 객체가 아니다.
-
따라서 테스트하기 쉽다.
-
게이트웨이는 스텁(stub), 모의(mock)나 테스트 더블(test-double)로 적당히 교체할 수 있기 때문이다.
데이터 매퍼
하이버네이트 같은 ORM은 어느 계층에 속한다고 봐야할까?
저자는 객체 관계 매퍼(Object Relational Mapper, ORM) 같은 건 존재하지 않는다고 한다.
-
객체는 데이터 구조가 아니기 때문이다.
-
데이터는 모두 private으로 감춰져 있기 때문에 사용자는 데이터를 볼 수 없닫.
-
사용자는 객체에서 public 메서드만 볼 수 있다.
-
사용자 입장에서 볼 때 단순히 오퍼레이션의 집합이다.
객체와 달리 데이터 구조는 함축된 행위를 가지지 않는 public 데이터 변수의 집합이다.
-
ORM보다 차라리 '데이터 매퍼(Data Mapper)'라고 부르는 편이 나아 보인다.
- 관계형 데이터베이스 테이블로부터 가져온 데이터를 데이터 구조에 맞게 담아주기 때문이다.이러한 ORM 시스템은 어디에 위치해야 하는가?
-
물론 데이터베이스 계층이다.
-
실제로 ORM은 게이트웨이 인터페이스와 데이터베이스 사이에서 일종의 또 다른 험블 객체 경계를 형성한다.
서비스 리스너
애플리케이션이 다른 서비스(server)와 통신해야 하거나 일련의 서비스를 제공해야 한다면 어떨까?
-
이 경우에도 서비스 경계를 생성하는 험블 객체 패턴을 발견할 수 있다.
서비스 리스너(service listener)가 서비스 인터페이스로부터 데이터를 수신하고, 데이터를 애플리케이션에서 사용할 수 있게 간단한 데이터 구조로 포맷을 변경한다.
-
그 후 이 데이터 구조는 서비스 경계를 가로질러서 내부로 전달된다.
결론
-
각 아키텍처 경계마다 경계 가까이 숨어 있는 험블 객체 패턴을 발견할 수 있다.
-
경계를 넘나드는 통신은 거의 다 간단한 데이터 구조를 수반할 때가 많고 그 경계는 테스트하기 어려운 무언가와 쉬운 무언가로 분리된다.
-
이렇게 아키텍처 경계에서 험블 객체 패턴을 사용하면 전체 시스템의 테스트 용이성을 크게 향상시킬 수 있다.
-
- 24 부분적 경계 아키텍처 경계를 완벽하게 만드는 데에는 많은 비용이 든다. 너무 많은 노력이 필요하니 일부는 탐탁지 않아한다(YAGNI, You Aren't Going to Need It) 하지만 아키텍트라면 "그래, 하지만 어쩌면 필요할지도"라고 생각하며, 부분적 경계부터 시작할 것이다.
마지막 단계를 건너뛰기
부분적 경계를 생성하는 방법 하나는 독립적으로 컴파일하고 배포할 수 있는 컴포넌트를 만들기 위한 작업은 모두 수행한 후, 단일 컴포넌트에 그대로 모아만 두는 것이다.-
쌍방향 인터페이스, 입력ㆍ출력 데이터 구조, 모든 것이 완전히 준비되어 있다.
- 하지만 이 모두를 단일 컴포넌트로 컴파일 및 배포한다.이렇게 보면 부분적 경계를 만들때 완벽한 경계를 만들 때 만큼의 코드량과 사전 설계가 필요한것 같다.
-
하지만 다수의 컴포넌트를 관리하는 작업은 하지 않아도 된다.
-
추적을 위한 버전 번호도 없으며, 배포 관리 부담도 없다.
-
이 차이는 절대 가볍지 않다.
-
일차원 경계
완벽한 형태의 아키텍처 경계는 양방향으로 격리된 상태를 유지해야 한다.
- 쌍방향 Boundary 인터페이스 사용
- 비용 많이 듦
아래 그림은 추후 완벽한 형태의 경계로 확장할 수 있는 공간을 확보하고자 할 때 활용할 수 있는 더 간단한 구조를 나타낸다.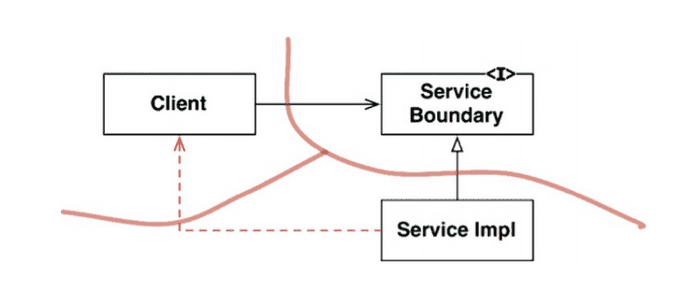
퍼사드
이보다 훨씬 더 단순한 경계는 다음 그림의 퍼사드(Facade) 패턴이다.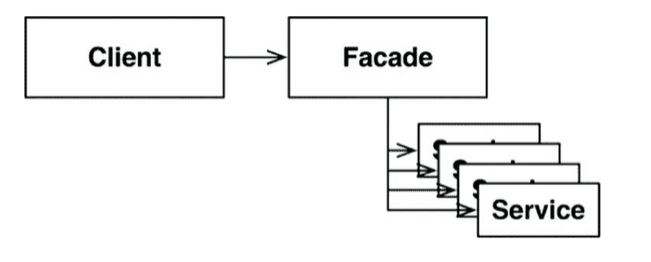
- 이 패턴은 의존성 역전도 희생한다.
- 경계는 Facade 클래스로만 간단히 정의된다.
- Facade 클래스에는 모든 서비스 클래스를 메서드 형태로 정의하고, 서비스 호출이 발생하면 해당 서비스 클래스로 호출을 전달한다.
- 클라이언트는 서비스 클래스에 직접 접근할 수 없다.
하지만 이 경우 Client가 모든 서비스 클래스에 대해 추이 종속성을 가지게 된다.결론
아키텍처 경계를 부분적으로 구현하는 간단한 방법 세 가지를 살펴 봤다(물론 더 많은 방법 존재).
- 각기 다른 나름의 비용과 장점을 지닌다.
- 각 접근법은 완벽한 형태의 경계를 담기 위한 공간으로써, 적절하게 사용할 수 있는 상황이 다르다.@PARKER
20장 업무 규칙
- 업무 규칙(또는 핵심 업무 규칙, Critical Business Rule): 사업적으로 수익을 얻거나 비용을 줄일 수 있는 규칙 또는 절차
- 컴퓨터로 구현했는지와 관련은 없음
- 핵심 업무 데이터(Critical Business Data): 핵심 업무 규칙이 필요로하는 데이터
- 핵심 규칙과 핵심 데이터는 본질적으로 결합되어 있으며, 개발 시 이를 엔티티 형태로 객체화한다.
엔티티
- 엔티티는 핵심 업무 데이터를 기반으로 동작하는 일련의 조그만 핵심 업무 규칙을 구체화한다.
- 엔티티는 데이터베이스, 사용자 인터페이스, 서드파티 프레임워크와는 철저히 분리되어야 한다.
- 엔티티는 어떤 시스템에서도 업무 수행이 가능해야 한다. (시스템과 독립적으로 개발가능해야 한다.)
Domain-Driven Design의 적용-1.VALUE OBJECT와 REFERENCE OBJECT 1부
유스케이스
- 유스케이스는 엔티티를 활용하여 자동화된 시스템이 동작하는 방법을 정의하고 제약함으로써 수익을 얻거나 비용을 줄이는 업무 규칙에 해당된다.
- 유스케이스 구성
- 사용자가 제공해야 할 입력
- 사용자에게 보여줄 출력
- 해당 출력을 생성하기 위한 처리 단계

- 엔티티를 제어하는 것이 유스케이스 (위 예제에서도 엔티티 Customer를 언급하고 있음)
- 유스케이스 특징
- 유스케이스는 시스템이 사용자에게 어떻게 보여지는지(웹인지, 콘솔인지, ...) 설명하지 않는다. (= 의존하지 않는다.)
- 엔티티는 객체로 표현되며, 입력 데이터/출력 데이터/유스케이스가 상호작용하는 엔티티에 대한 참조 데이터 세 가지를 포함한다.
- 엔티티는 자신이 제어하는 유스케이스에 대해 전혀 알지 못해야 한다.
- 유스케이스가 엔티티에 의존하고 있다.
- 엔티티는 고수준 / 유스케이스는 저수준 (저수준 → 고수준)
Entity-control-boundary - Wikipedia
21장 소리치는 아키텍처
- 여러분의 애플리케이션 아키텍처는 뭐라고 소리치는가? (최사위 디렉토리 구조, 패키지에 담긴 소스를 봤을 때)
- "헬스 케어 시스템이야", "재고 관리 시스템이야"
- "레일스야", "스프링/하이버네이트야", "ASP야"
- 아키텍처는 유스케이스에 대해 소리쳐야 한다.
- 좋은 아키텍처는 유스케이스를 자유롭게 기술할 수 있어야 한다.
- 프레임워크, 데이터베이스, 웹 서버 그리고 여타 개발 환경 및 도구는 최대한 미룰 수 있어야 한다. (유스케이스에 침범하면 안된다.)
- 테스트 역시 여타 개발 환경 및 도구와 의존없이 실행가능해야 한다.
22장 클린 아키텍처
- Hexagonal Architecture, DCI(Data, Context and Interaction), BCE(Boundary-Control-Entity)
- 중요한 핵심은 "관심사의 분리(separation of concerns)"이다.
- 특징
- 프레임워크 독립성
- 테스트 용이성
- UI 독립성
- 데이터베이스 독립성
- 모든 외부 에이전시에 대한 독립성
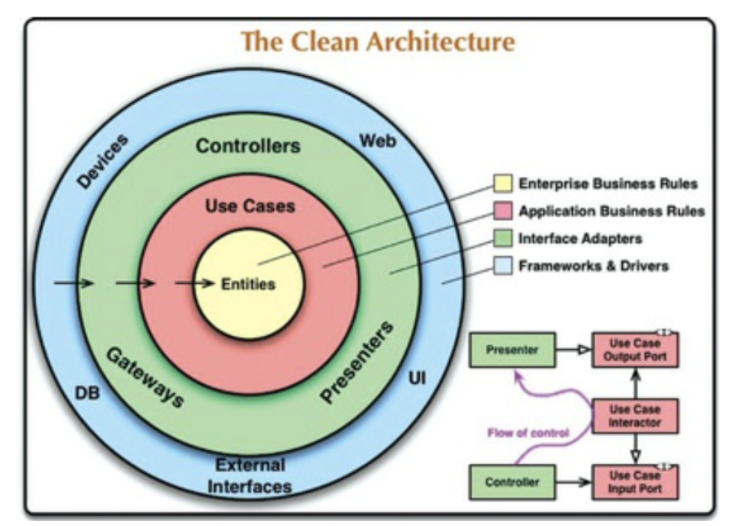
-
안으로 들어갈수록 고수준, 바깥쪽 원은 메커니즘/안쪽 원은 정책
-
"소스 코드 의존성은 반드시 안쪽으로, 고수준의 정책을 향해야 한다."
- 외부 원에 위치한 어떤 것도 내부의 원에 영향을 주어선 안된다.
-
원은 4개여야한다는 규칙은 없지만, 의존성 규칙은 어디서나 적용되어야 한다.
-
엔티티
-
유즈케이스
-
인터페이스 어댑터(프레젠터, 뷰, 컨트롤러, ...)
-
프레임워크와 드라이버 (모든 세부사항)
-
제어흐름과 의존성이 반대인 경우는 의존성 역전 원칙을 사용하여 해결해야 한다. (유스케이스가 프레젠터를 호출하는 경우)
-
각 경계를 횡단하는 데이터는 엔티티 객체나 데이터베이스 행을 사용하지 말고, DTO로 따로 분리해서 사용해야 한다.
23장 프레젠터와 험블 객체
- 프레젠터는 험블 객체(Humble Object, 대강 만든 객체) 패턴을 따른 형태로, 아키텍처 경계를 식별하고 보호하는 데 도움이 된다.
험블 객체 패턴
- 험블 객체 패턴은 디자인 패턴으로, 테스트하기 어려운 행위와 테스트하기 쉬운 행위를 나눈다. 그리고 테스트하기 어려운 행위를 험블 객체에 클래스 또는 모듈 형태로 담는다.
- GUI → 프레젠터/뷰(험블객체)
프레젠터와 뷰
- 뷰는 데이터를 GUI로 이동시키지만, 데이터를 직접 처리하지는 않는다.
- 프레젠터는 애플리케이션으로부터 데이터를 받아 화면에 표현할 수 있는 포맷으로 만드는 역할을 한다. (테스트하기 쉬운 객체)
- 유스케이스 인터랙터와 데이터베이스 사이에는 데이터베이스 게이트웨이가 위치한다.
- 유스케이스는 SQL에 의존해서는 안되고, 데이터베이스 게이트웨이의 메서드를 호출해야 한다.
- ORM은 실제로는 없다.
- 객체는 데이터 구조와 다르기 때문에, ORM으로 부르기보다 데이터 매퍼로 불러야 한다.
- 데이터 구조는 행위를 가지지 않는 public한 데이터의 모음.
- 게이트웨이 인터페이스와 데이터베이스 사이에 또 다른 험블 객체로 ORM이 존재해야 한다.
결론
경계를 넘나드는 통신은 거의 모두 간단한 데이터 구조를 수반할 때가 많고, 대개 그 경계는 테스트하기 어려운 무언가와 테스트하기 쉬운 무언가로 분리될 것이다. 그리고 이러한 아키텍처 경계에서 험블 객체 패턴을 사용하면 전체 시스템의 테스트 용이성을 크게 높일 수 있다.
24장 부분적 경계
- 아키텍처 경계를 완벽하게 만드는 데는 비용이 많이 든다.
- 완전한 경계
- 쌍방향(input/output)의 다형적 인터페이스 및 이를 위한 데이터 구조
- 경계를 기준으로 나뉜 영역은 각각 독립적으로 컴파일하고 배포 가능해야 함.(컴포넌트 분리)
- 완전한 경계
- 완전한 경계에 대한 비용이 부담된다면, 부분적 경계(partial boundary)를 구현해볼 수 있다.
- 부분적 경계: 완전한 경계 특징 중 일부만 만족하는 경계
- 부분적 경계 구현 방법
- 단일 컴포넌트에 쌍방향 인터페이스 만들기
- 완전한 경계만큼의 코드량과 설계가 필요
- 단일 컴포넌트로 편리하게 관리 가능
- 일차원 경계 → 전략 패턴 사용
- 퍼사드 패턴 사용
- 단일 컴포넌트에 쌍방향 인터페이스 만들기
@ODIN
- 20장. 업무 규칙
- 사업적으로 수익을 얻거나 비용을 줄일 수 있는 규칙 또는 절차이다.
- 업무 규칙은 시스템에서 가장 독립적이며 가장 많이 재사용할 수 있는 코드여야한다.
- 엔티티
- 핵심 업무 데이터를 기반으로 동작하는 일련의 조그만 핵심 업무 규칙을 구체화한다.
- 엔티티 객체는 핵심 업무 데이터를 직접 포함하거나 핵심 업무 데이터에 매우 쉽게 접근할 수 있다.
- 엔티티의 인터페이스는 핵심 업무 데이터를 기반으로 동작하는 핵심 규칙을 구현한 함수들로 구성.

- Loan 엔티티는 3가지 핵심 업무 데이터를 포함하며, 데이터와 관련된 3가지 핵심 업무 규칙을 인터페이스로 제공.
- 각 독립적으로 존재하며, 다른 고려사항들로 오염되서는 안되며 **엔티티는 순전히 업무에 대한 것이며 이외의 것은 없다. 엔티티 생성의 유일한 요구조건은 핵심 업무데이터와 핵심 업무 규칙을 하나로 묶어서 별도의 소프트웨어 모듈로 만들어야 한다는 것.**
- **유스케이스**
- 엔티티 내의 핵심 업무 규칙과는 반대로 유스 케이스는 **애플리케이션에 특화된 업무 규칙을 설명한다. →** 엔티티 내부의 핵심 업무 규칙을 어떻게, 그리고 언제 호출할지를 명시하는 규칙을 담는다.
- 애플리케이션에 특화된 업무 규칙을 구현하나 하나 이상의 함수를 제공. 입력, 출력데이터 유스케이스가 상호작용하는 엔티티에 대한 참조 데이터 등의 데이터 요소를 포함.
- **엔티티는 고수준, 유스케이스는 저수준이다.** → 유스 케이스는 단일 애플리케이션에 특화되어 있으며, 해당 시스템의 입력과 출력에 보다 가깝게 위치한다. **유스케이스는 엔티티에 의존하지만 엔티티는 유스 케이스에 의존하지 않는다.**
- **요청 및 응답 모델**
- 독립적이여야한다. → 독립적이지 않다면 그 모델에 의존하는 유스케이스도 결국 해당 모델이 수반하는 의존성에 간접적으로 결합 되어버린다.- 21장. 소리치는 아키텍처
- 필요한 유스케이스 전부에 대해 단위 테스트 할 수 있어야 한다.
- 아키텍처는 시스템을 이야기해야하며, 시스템에 적용한 프레임워크에 대해 이야기 해서는 안된다. 새로 합류한 프로그래머는 시스템이 어떻게 전달될지 알지 못한 상태에서도 시스템의 모든 유스케이스를 이해할 수 있어야한다. "모델처럼 보이는 것들을 확인했습니다. 그런데 뷰와 컨트롤러는 어디에 있죠?" 라는 물음에 "아, 그것은 세부사항이므로 당장은 고려할 필요가 없습니다. 나중에 결정 할 겁니다"
- 22장. 클린 아키텍처
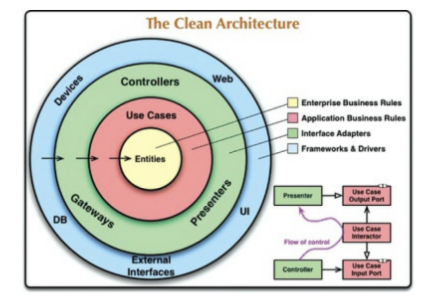
- 아키텍처는 최소한 업무규칙을 위한 계층 하나와, 사용자와 시스템 인터페이스를 위한 또 다른 계층 하나를 반드시 포함한다.
- 육각형 아키텍처, DCI(data context and interaction), BCE(boundary-control-entity) 이들 아키텍처는 세부적인 차이는 있더라도 내용은 비슷하다.
- 프레임워크 독립성, 테스트 용이성, UI독립성, 데이터 베이스 독립성, 모든 외부 에이전시에 대한 독립성과 같은 특징을 지니도록 만든다.
- 의존성 규칙 : 소스 코드의 의존성은 반드시 안쪽으로, 고수준 정책을 향해야 한다.
- 엔티티 : 전사적인 핵심 규칙을 캡슐화 한다. 외부의 무언가가 변경되더라도 엔티티가 변경될 가능성은 지극히 낮다.
- 유스케이스 : 애플리케이션에 특화된 업무 규칙을 포함한다. 이 계층에서 발생한 변경이 엔티티에 영향을 줘서는 안된다.
- 경계 횡단하기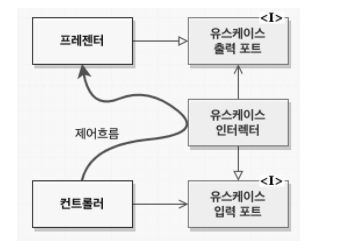
- 제어 흐름은 컨트롤러에서 시작해서, 유스케이스를 지난 후, 프레젠터에서 실행되면서 끝난다. 모든 의존성은 유스케이스를 향한다.
- 제어흐름이 경계를 가로지르는 바로 그 지점에서 소스 코드 의존성을 제어흐름과는 반대가 되도록 할 수 있다.
- 동적 다형성을 이용하여 소스 코드 의존성을 제어흐름과 반대로 만들 수 있고, 이를 통해 제어흐름이 어느 방향으로 흐르든 상관 없이 의존성 규칙을 준수할 수 있다.- 23장. 프레젠터와 험블 객체
- 프레젠터는 험블 객체 패턴을 따른 형태로 아키텍처 경계를 식별하고 보호하는데 도움이 됨.
- 험블 객체 패턴
- 테스트 하기 어려운 행위를 험블 객체로 옮기고 나머지 모듈에는 테스트 하기 쉬운 행위를 옮김.
- 24장. 부분적 경계
- 아키텍처 경계를 완벽하게 만드는 데는 비용이 많이 든다.
- 아키텍처 경계가 언제, 어디에 존재해야 할지, 그리고 그 경계를 완벽하게 구현할지 아니면 부분적으로 구현할지를 결정하는 일 또한 아키텍트의 역활이다.
@BRANDON
20. 업무 규칙
🗒️ 정리 - 소프트웨어 시스템의 존재 이유 - 핵심기능 - 회사 비즈니스와 밀접한 관련 - 시스템에서 가장 독립적이며 재사용이 가능한 코드형태가 이상적21. 소리치는 아키텍처
🗒️ 정리 - 아키텍쳐는 프레임워크 종속적이지 않아야함 - 프레임워크는 사용도구로서 존재 - 유스케이스 위주의 설계 ⇒ 실무와 동떨어져 보이지만 일단 책 내용이니 다른 멤버의 설명을 들어보기 +_+22. 클린 아키텍처
- 헥사고날 / 포트&어댑터 의견 중 하나 박성철님 페북 발췌
-
개인적인 공감대가 있긴한데 사실 헥사고날에 대해서 잘알아본적이 없어서 이 부분 설명해 줄 수 있는 멤버 있으면 좋을거 같아요 😂 원래 시간적 여유가 생기면 베니에게 내부 전파 요청드리려고 했는데 시간이 늘 문제네요 🤢
-
읽어보면 머리로는 이해가 되는데 행동으로 옮겨본적이 없어 상당히 귀찮을거 같다는 생각만해본거 같네요. 역시 해오던 관성이 있다보니 익숙한 형태대로 해놓자로 정리가 되는느낌인데 이 틀을 깨는 과정이 늘 어렵네요 새롭게 생기는 패러다임의 변화가 크게 올때도 마찬가지고.

-
- 잘 알고 사용하고 맞는 아키텍처 도입을 하는게 이상적이라는 생각이 들었던거 같아요. 업계에 있다보면 정말 버즈워드도 많고 트렌드도 돌고도는 경향이 있다라는 생각이 드는데 저희가 몸담고 있는 곳의 특성이 어쩔 수 없는거 같고 늘 공부하는게 중요하겠구나를 매번 느끼게 되네요 다들 화이팅이요라고 뜬금 없는 소회로 마무리
- 관심사의 분리 (Seperation of concerns)를 통해 소프트웨어 계층을 잘 나누고 의존성규칙을 잘 따른다면 테스트하기 쉬운 시스템 생성이 가능
같이 일하는 멤버들 내에서의 격차가 중요하다라고 생각하는데 개인적으로는 가장 느리게 따라오는 멤버를 기준으로 정책이 정해져야 한다고 생각하며 함께가기 위해서는 당연히 그만큼의 노력과 시간이 뒤따르는데 어떤 형태로 아키텍쳐의 적용 및 변화를 추구하는게 이상적인걸까??
23. 프렌젠터와 험블 객체
뷰는 험블 객체이고 테스트하기 어렵다
- 최근 프론트엔드 파트에서 센트리를 도입하고 테스팅해나가는 과정을 지켜보면서 책에 써있는 해당 내용은 현재와는 맞지 않는 내용이 아닐까 싶었어요.
- 데이터 매퍼
- jOOQ ⇒ 크리스의 ORM 비교 링크를 보고 의무감에 하나 링크해 봤어요.
24. 부분적 경계
@LIAM
❓ 20. 업무 규칙- 유스케이스가 책을 계속 들여다보니 기획서와 비슷할 수 있겠다는 생각이 드는데 어떤가요?
- 크리스가 보내준 링크로 엔티티와 vo의 차이점이 불변성이라 명시되어있는데, 그 불변성은 데이터의 후처리를 뜻할까요 ? (DB데이터를 가져온다고 가정하였을 경우, SELECT된 List를 Loop하며 값을 변환시키면 그것이 불변성이 깨지는건가?)
- 아키텍처의 목적을 읽으면서 크게 와닿지 않네요, 지금까지의 개발은 프레임워크, 데이터 베이스, 웹서버, 모든 도구들이 정해진 상태에서 업무를 시작했고, 지금도 팀단위, 기업단위로 움직이는 프로젝트라면 공통으로 가야한다고 생각합니다. 해서 코드 스타일 조차도 공통으로 가고자 하는데.. 흠..
- 약간 MVC(Model View Controller) 이 생각나네요, View에는 비지니스 로직이나 특정 행위를 하지 않는다 → 험블하기 때문일까요
@LEO
22. 클린 아키텍처
-
관심사의 분리
-
모두 소프트웨어를 계층으로 분리함으로써 관심사의 분리라는 목표를 달성할수 있음
-
특징
- 프레임워크 독립성 : 프레임워크의 존재 여부에 의존하지 않는다. 이를 통해 프레임워크를 도구로 사용할수 있으며 프레임워크가 지난 제약사항 안으로 시스템을 욱여 넣도록 강제하지 않는다.
- 테스트 용이성 : 업무 규칙은 UI, 데이터베이스, 웹서버, 또는 여타 외부 요소가 없이도 테스트할 수 있다.
- UI 독립성 : 시스템의 나머지 부분을 변경하지 않고도 UI를 쉡게 변경할 수 있다. 예를 들어 업무 규칙을 변경하지 않은 채 웹 UI를 콘솔 UI로 대체할 수 있다.
- 데이터베이스독립성 : 오라클이나 MS SQL 서버를 몽고 DB 등으로 교체할 수 있다.
- 모든 외부 에이전시에 대한 독립성 : 실제로 업무 규칙은 외부 세계와의 인터페이스에 대해 전혀 알지 못한다.
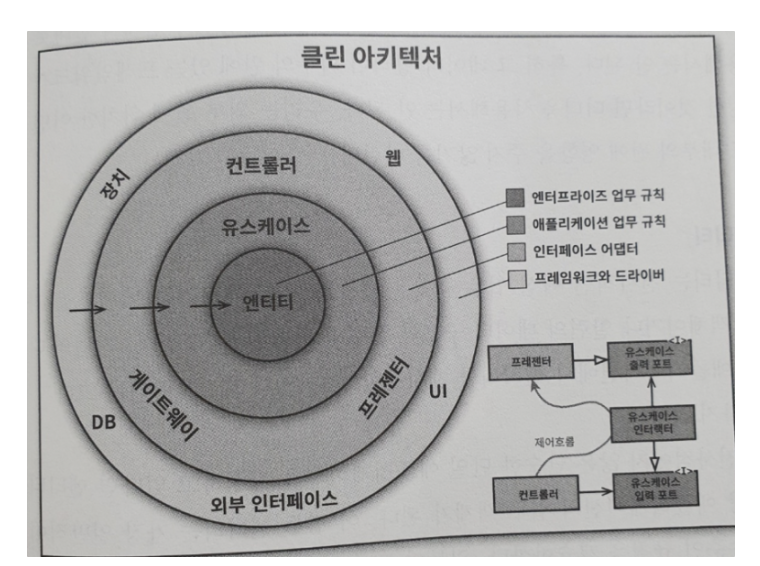
“소스 코드 의존성은 반드시 안쪽으로 고수준의 정책을 향해야 한다.”
-
엔티티
- 고수준인 업무규칙을 캡슐화한다.
- 특정 애플리케이션에 무언가 변경이 필요하더라도 엔티티 계층에는 절대로 영향을 주어서는 안된다.
-
유스케이스
- 유스케이스 계층의 소프트웨어는 애플리케이션에 특화된 업무 규칙을 포함한다.
- 시스템의 모든 유스케이스를 캡슐화하고 구현한다.
- 해당 계층에서 발생한 변경이 엔티티에 영향을 줘서는 안된다. 뿐만 아니라 외부 요소에 발생한 변경이 계층에 영향을 줘서도 안된다.
- 그러나 운영 관점에서 애플리케이션이 변경된다면 유스케이스가 영향을 받으며, 해당 계층에도 영향을 줄것이다.
- 인터페이스 어댑터
- 어댑터는 데이터를 유스케이스와 엔티티에게 가장 편리한 형식에서 데이터베이스나 웹같은 외부 에이전시에게 가장 편리한 형식으로 변환한다.
- 프레임워크와 드라이버
- 모두 세부사항이 위치하는곳(웹, 데이터베이스)
- 원은 네개여야만 하나? 항상 네 개만 사용해야 한다는 규칙은 없다. 하지만 어떤 경우에도 의존성 규칙은 적용된다
- 소스 코드 의존성은 항상 안쪽을 향한다.
- 안쪽으로 이동할수록 추상화와 정첵의 수준은 높아진다.
- 가장 바깥쪽 원은 저수준의 구체적인 세부사항으로 구성된다.
- 안쪽으로 이동할수록 소프트웨어는 점점 추상화되고 더 높은 수준의 정책들을 캡슐화한다.
- 경계 횡단하기 제어흐름이 컨트롤러 -> 유스케이스 -> 프레젠터로 마무리된다.
- 유스케이스 -> 프레젠터를 직접호출하면은 의존성 규칙을 위배하기 때문에 의존성 역전 원칙을 사용하여 해결한다.
- 이를 통해 제어흐름이 어느 방향으로 흐르더라도 의존성 규칙을 준수 할 수 있다.
- 경계를 횡단하는 데이터는 어떤 모습인가
- 예를 들어 dto 격리되어 있는 간단한 데이터 구조가 경계를 가로질러 전달된다는 사실
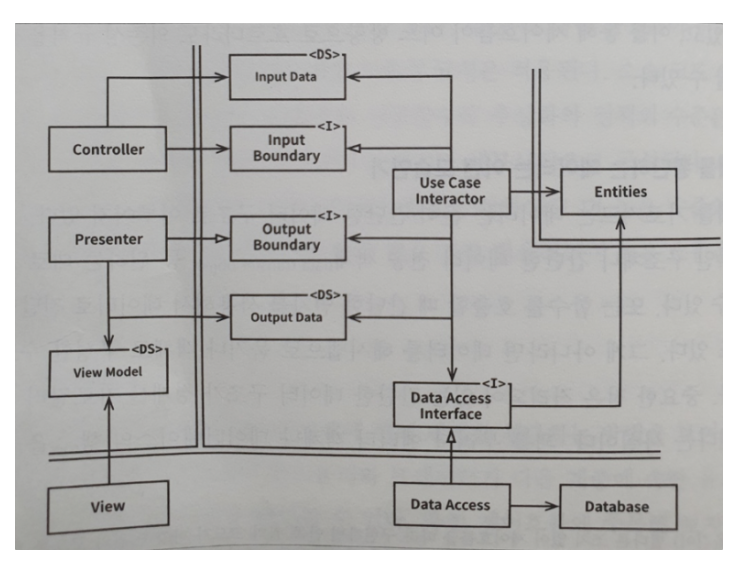
- 소프트웨어를 계층으로 분리하고 의존성 규칙을 준수한다면 본질적으로 테스트하기 쉬운 시스템을 만들게 될 것이며, 그에 따른 이점을 누릴 수 있다.
