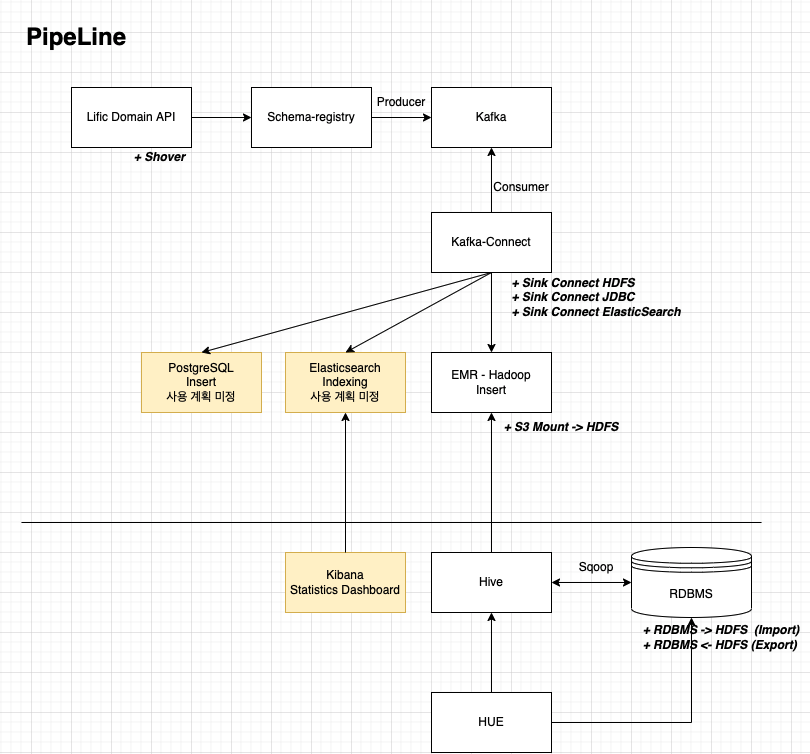
Work 1. 프로세스 파이프라인 설계
데이터를 각각의 도메인에서 시작하여 하둡의 HDFS까지 적재한다.
최종 목표는 Hive를 통해서 원하는 형태의 데이터를 추출하는 것이다.
1-1. 데이터 적재 설계
Work 2. 구성 - 스키마 레지스트리 & 스키마 레지스트리 UI
2-1. 스키마 레지스트리 구성
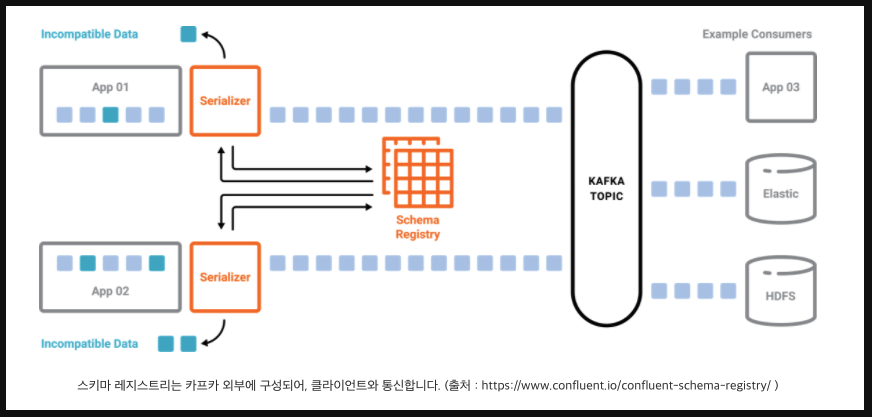
스키마 레지스트리를 통해 토픽별 Key:Value형태의 스키마를 작성하고 해당 형태에 맞는 데이터만 프로듀스와 컨슘이 가능하도록 강제한다.
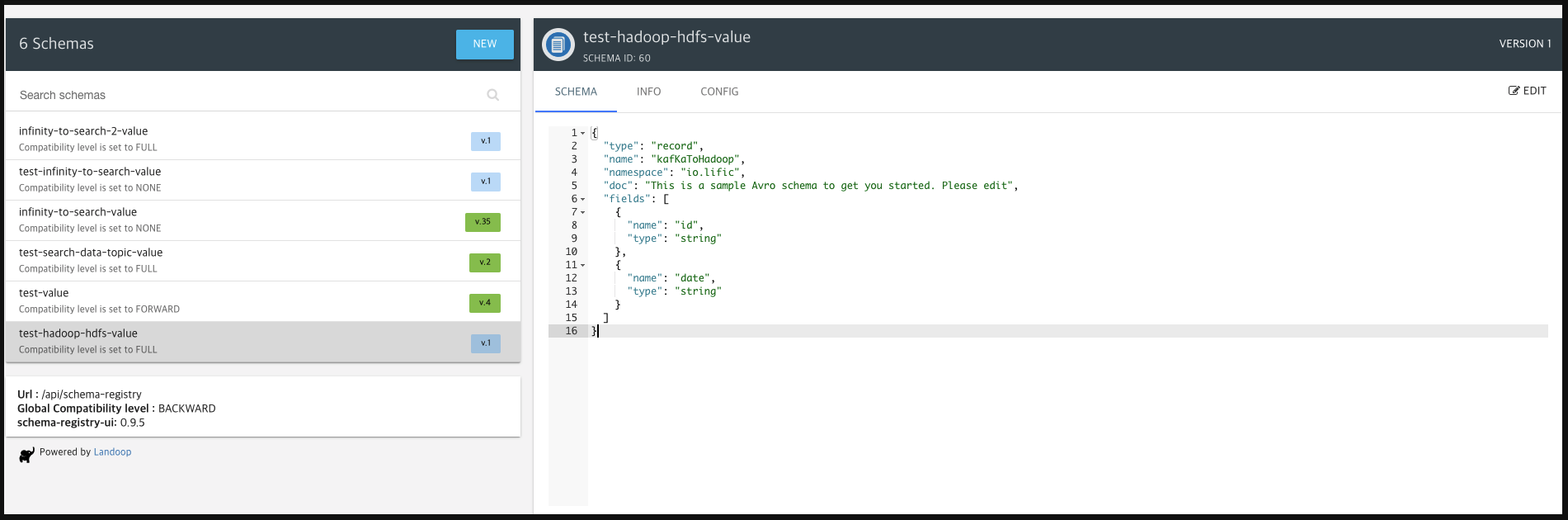
테스트 케이스에서는 id와 date 두개의 필드만 정의하였으며 추후 저장되어야 하는 데이터를 Row단위로 나열하여 저장해야한다.
💡 등록시 tree구조로 저장이 가능한 것처럼 보이나, 구성시 1Depth row로 정의한다.
내부 코드의 복잡성과 여러 Depth의 깊이를 탐색하는 로직이 구성되어야 하며 topic별로 카테고리를 구분할 것이므로
{
"type": "record",
"name": "kafKaToHadoop",
"namespace": "io.lific",
"doc": "This is a sample Avro schema to get you started. Please edit",
"fields": [
{
"name": "id",
"type": "string"
},
{
"name": "date",
"type": "string"
}
]
}스키마 정의 예제
2-2. 스키마 레지스트리 UI
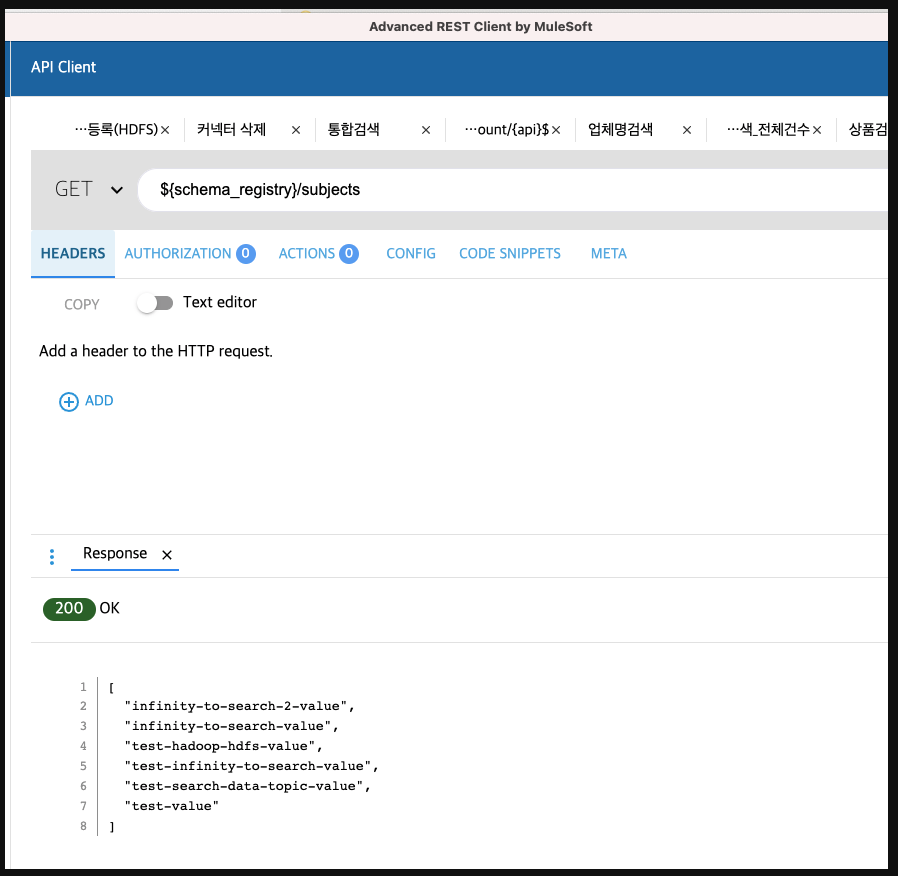
스미카 레지스트리 UI는 스키마레지스트리를 좀더 편리하게 작성할 수 있도록 도와준다.
Rest API를 지원하므로 PostMan같은 툴로도 가능하다. ( 즉, 해당 서비스는 옵션이지 필수가 아니다 )
Work 3. Shover 라이브러리 개발
3-1 Shover?
Andrew가 지어준 프로젝트명, 지정 데이터를 Avro형식(2진 데이터)으로 Serialize하여 스키마 레지스트리를 통해 데이터 형식을 검증하고 완료 후 카프카에 프로듀스 하는 라이브러리
shover[ʃʌ́vər] (명사)
(통근 열차에 손님을) 밀어 넣는 사람
3-2 목적
해당 라이브러리는 각 도메인별 플러그인 형태로 사용할 수 있도록 설계하였다. 전달받은 객체는
Shover내에서 처리하며, Json형태의 Serialize ↔ Deserialize 로 데이터를 주고 받도록 한다.
- 각 도메인 별로 Shover에 의해 코드가 변경되어서는 안된다.
- Shover는 POJO(Plain Old Java Object)를 지향하는 방식으로 개발한다.
- 프레임워크(Spring)을 사용하지 않는다.
- Shover는 각 도메인의 Request ↔ Response 속도에 영향을 주면 안되므로 비동기를 원칙으로 한다 ( 단, Producer send의 정상 전송 유무를 알 수 없다)
- 라이브러리 형태이므로 Java 주석을 포함한 형태로 사용자가 어떠한 메소드인지 알 수 있도록 한다
3-3 주요 코드
- 사용 예제 (Sample)
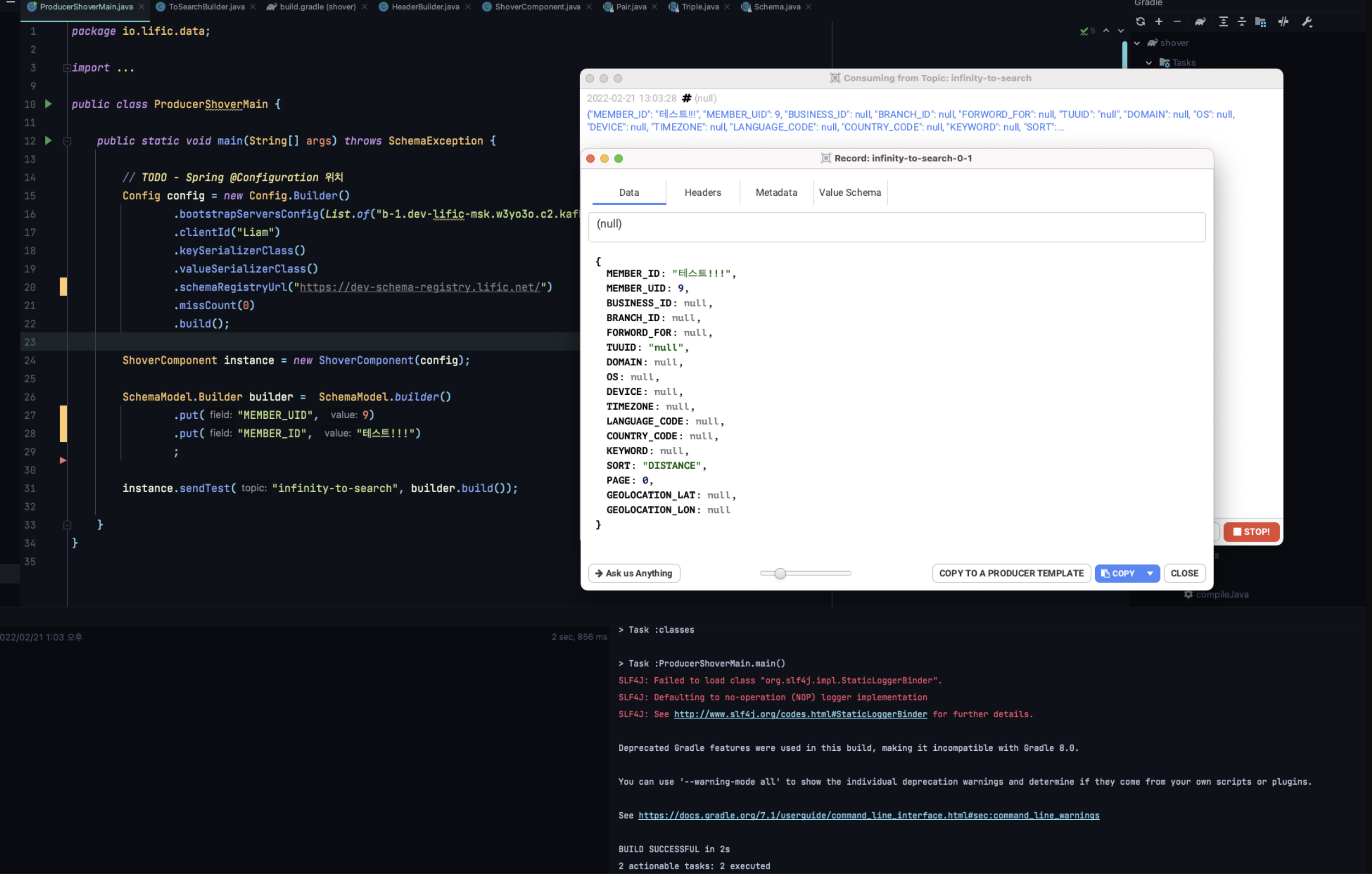
public static void main(String[] args) throws SchemaException { // TODO - Spring @Configuration 위치 Config config = new Config.Builder() .bootstrapServersConfig(List.of("서버1:9092", "서버2:9092")) .clientId("Liam") .keySerializerClass() .valueSerializerClass() .schemaRegistryUrl("http://kubernetes.docker.internal:8082") .missCount(0) .build(); ShoverComponent instance = new ShoverComponent(config); SchemaModel.Builder builder = SchemaModel.builder() .put("MEMBER_UID", 9); ; instance.sendTest("infinity-to-search", builder.build()); } - 사용 예제
private final ShoverComponent shover; @GetMapping public Controller Method { //추가되는 부분 shover.send("topic", ToSearchBuilder.builder(request, HeaderBuilder.builder(header)).build()); return new response }@Configuration public class ShoverConfig { @Value("${spring.kafka.producer.bootstrap-servers}") private List<String> bootstrapServers; @Value("${spring.kafka.producer.schema-registry-url}") private String schemaRegistryUrl; @Value("${spring.kafka.producer.miss-count}") private Integer missCount; @Bean public ShoverComponent shoverComponent() { return new ShoverComponent( new Config.Builder() .bootstrapServersConfig(bootstrapServers) .clientId("infinity-api") .missCount(missCount) .keySerializerClass() .valueSerializerClass() .schemaRegistryUrl(schemaRegistryUrl) .build() ); }
Work 4. 연동 - 카프카 ↔ Shover
정상적으로 연동이 되는것을 테스트 할때, Conduktor 프로그램의 자체 Consumer로 체크.
💡 스키마 레지스트리를 구성하는 강제 규칙이 존재한다.**아래 표를 참고하면 다음과 같이 3가지의 전략이 존재하는데 기본값 사용시 우리가 카프카에서 생성한 topic명으로 한다는 전략이다. 그런데 단순한 topic명과 Exact 매칭이 아닌 강제적으로 -value라는 명칭이 붙는다**. ( 스키마레지스트리UI에서도 placeholder 에 -value가 붙어있다. ) 해서 정상적인 테스트및 구성을 위해서는 스키마레지스트리UI에서 Topic과 맵핑되는 Subject를 구성할 때, Topic명 + -value의 형태를 맞추어서 작업해주어야 한다.
4-1. 주체 이름 전략 (Subject Name Strategy)
| TopicNameStrategy | 주제 이름에서 주제 이름을 파생합니다. (기본값입니다.) |
|---|---|
| RecordNameStrategy | 레코드 이름에서 주제 이름을 파생하고 주제 아래에 다른 데이터 구조를 가질 수 있는 논리적으로 관련된 이벤트를 그룹화하는 방법을 제공합니다. |
| TopicRecordNameStrategy | 주제 아래에 다른 데이터 구조를 가질 수 있는 논리적으로 관련된 이벤트를 그룹화하는 방법으로 주제 및 레코드 이름에서 주제 이름을 파생합니다. |
4-2. 예제
- 샘플 예제 스키마레지스트리
{
"type": "record",
"name": "BenefitPointModel",
"namespace": "io.lific.data.request.consumer.benefit",
"doc": "QA - Consumer benefit point schema",
"fields": [
{
"name": "member_uid",
"type": "long",
"doc": "로그인 ID"
},
{
"name": "point_id",
"type": "long",
"doc": "포인트 ID"
},
{
"name": "point_provide",
"type": "long",
"doc": "포인트 지급금"
},
{
"name": "point_type",
"type": "string",
"doc": "포인트 유형"
},
{
"name": "point_status",
"type": "int",
"doc": "포인트 상태 (0:적립, 1:차감, 2:회수, 3:소멸)"
},
{
"name": "branch_id",
"type": [
"null",
"long"
],
"doc": "업체 ID",
"default": null
},
{
"name": "product_id",
"type": [
"null",
"long"
],
"doc": "상품 ID",
"default": null
},
{
"name": "datetime",
"type": "string",
"doc": "입력 시간"
}
]
}
Work 5. 구성 - 카프카 커넥트
반복적인 데이터 파이프라인을 효과적으로 배포하고 관리하는 방법.
현재 EKS에서 구동중인 카프카 커넥트는 BASE Docker이미지에서 다음과 같이 컨플루언트 허브를 통해 설치한 커넥터들을 추가하여 구성되었다.
| PostgreSQL Sink Connector | confluent-hub install debezium/debezium-connector-postgresql:1.7.1 |
|---|---|
| Elasticsearch Sink Connector | confluent-hub install confluentinc/kafka-connect-elasticsearch:11.1.8 |
| Hadoop HDFS 2 Sink Connector | confluent-hub install confluentinc/kafka-connect-hdfs:10.1.4 |
| Hadoop HDFS 3 Sink Connector | confluent-hub install confluentinc/kafka-connect-hdfs3:1.1.9 |
소스 커넥터 : 특정 위치 데이터 → 카프카 토픽
싱크 커넥터 : 카프카 토픽 → 특정 위치 데이터
💡 소스 커넥터는 Shover에서 프로듀싱을 할 예정이므로 해당 Work flow에서는 사용하지 않는다. 카프카로 전송된 토픽데이터를 하둡으로 전송하기 위한
싱크 커넥터만을 사용한다
{
"name": "simple-elasticsearch-connector",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"connection.url": "http://[ES-URL]/",
"tasks.max": "1",
"topics": "infinity-to-search",
"schema.ignore": "true",
"key.ignore": "true",
"type.name": "_doc"
}
}{
"name": "q-connector",
"config": {
"connector.class": "io.confluent.connect.hdfs.HdfsSinkConnector",
"partitioner.class": "io.confluent.connect.storage.partitioner.HourlyPartitioner",
"timezone": "Asia/Seoul",
"locale": "ko_KR",
"tasks.max": "2", # Kafka-connect instance 개수
"flush.size": "100", # 시간이 되지 않아도 일정 개수가 쌓이면 flush
"rotate.schedule.interval.ms": "300000", # 5분
"topics": "[TOPIC명]",
"store.url": "hdfs://[MASTER_NODE_URL]:8020",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "[SCHEMA_REGISTRY_URL]",
"hive.integration": true, # Hive 테이블 연결
"hive.database": "consumer", # 적재 database
"hive.metastore.uris": "thrift://[MASTER_NODE_URL]:9083",
"schema.compatibility": "FULL"
}
}💡 최신의 EMR 버전은 6.5.0이며, 그때의 Hadoop은 3.1.2 Version이다. hdfs에 대해서 2와 3버전을 둘다 connector로 설치했는데 사실상 둘의 차이를 명확하게 설명하는 부분이 없었다. 해서 Hadoop 3버전을 사용하므로 hdfs도 3버전으로 맞추었는데 이부분은 명확하지 않다... (현재 hdfs3 커넥터로 전송은 잘되는 중) - hdfs3 버그 발생으로 hdfs2로 변경
또한 EMR에서 제공하는 emrfs라는 hdfs 구현을 아마존에서 따로 커스텀한 기능이 존재하는것 같다. 설명으로는 “Amazon EMR에서 Amazon S3로 직접 일반 파일을 읽고 쓸 수 있도록 하는 HDFS 구현" 이라고 되어있는데 기존 hdfs와 별 차이를 못느끼겠고 무엇보다 카프카 커넥트에서 emrfs 커넥터는 제공하지 않으므로 사용하지 않는다.
Work 6. 구성 - EMR - Hadoop
하둡의 인스턴스를 AWS에서 구성하여 실행해준다. 외부의 설정보다는 내부의 설정을 맞춰주는듯 하다.
실제 하둡을 그냥 EC2인스턴스에서 사용하려면 설치와 각 설정파일을 건드려줘야 하는데(서버의 스펙에 맞도록) EMR에서는 내가 선택한 인스턴스의 스펙에 맞추어 메모리 사용이나 CPU사용률을 맞추어서 설정하는것 같다. 해서 기본값으로 구성을 해도 무리가 없이 동작한다.
6-1. 스토리지
스토리지에 관련한 부분은 EMR에서 지정한 스토리지를 사용하지 않고 S3를 이용해서 사용하고자 한다. 원하는 형태는 다음과 같다. ( 아마 이방식이 AWS에서 제공하려는 emrfs와 비슷한 상황이지 않을까 한다 )
s3fs-fuse를 EC2인스턴스에서 직접 설치하여 S3를 mount해서 사용 ( S3버킷을 연결 )
- 각 데이터노드(Slave)의 마운트 폴더를 생성한다.
- 해당 마운트 폴더를 S3 bucket과 심볼릭링크로 연결한다. ( 생성된 폴더의 위치와 S3의 위치가 같아진다 )
- 해당 마운트 폴더를 HDFS의 영역으로 설정한다. ( 256TB의 영역이 각 데이터 노드에 표기 )
- 즉, HDFS에 적재되는 데이터는 S3에 저장되고 있는 중이다.
6-2. 보안관련
💡 현재 검색&데이터에서 구축하는 모든 서비스는 보안이 걸려 있지 않다. (아마 다른 도메인들도 같을것으로 알고 있다)
하네와 이야기를 나눈적이 있는데 VPN으로 관리가 되고 있으므로 특정한 설정은 하지 않기로 하였다.
하지만 추후 보안 설정이 필요하다면, 하둡 내에서Kerberos(케르베로스) 라고 하는 인증 절차를 따로 구성해야 한다. (복잡함)
Work 7. 카프카 커넥트 ↔ Hive
카프카 커넥트를 통해서 HDFS에 데이터를 적재하며 해당 저장 방식은 Avro이다. (파일 확장자가 .avro)
카프카커넥트의 flush.size가 3이므로 하나의 .avro파일에는 3개의 row가 존재한다.
Hive 연산엔진 변경
Hive 2버전부터 연산 엔진이 mr → tez 변경되었다고 한다. 두개의 차이는 파일기반과 메모리기반의 차이이다. tez가 메모리 기반이라 IOException의 발생이 없고 더 빠르다고 하는데 실제 첫 클러스터 구성에서 tez를 사용했을 때 mr보다 수행이 빨랐다.
동일한 order by 쿼리를 수행했을 경우, tez는 40초대가 나왔고 mr은 1분대가 나왔었다.
하지만 기본설정의 tez로 쿼리를 수행하다보면 2~3회 수행에 한번씩 예외가 발생한다. (해당 예외는 여러 사유가 존재했고 ( ex 메모리, 버퍼 등등 ) 거진 모든 관련 구글링을 하고 시도해도 변함이 없었다. ( 외국인들의 질문에도 tez를 사용하지 않고 mr로 사용해서 해결했다는 글이 더 많음)
tez의 버전을 0.9.2 → 0.10.0으로 올려서 테스트를 진행하다 오히려 클러스터가 망가져서 현재는 mr연산으로 수행중
💡 단순한 SELECT 연산은 시간이 소요되지 않고 바로 나오는데, 연산관련 (COUNT(*), ORDER BY 등 Aggregation이 들어가면 그냥 속도가 아무리 적은 데이터로도 1분대가 나온다.
무수히 많은 데이터에서도 같은 시간이 나오는지 확인이 필요하다.
