Kafka Connect?
반복적인 데이터 파이프라인을 효과적으로 배포하고 관리하는 방법, 카프카에서 공식적으로 제공하는 컴포넌트 중 하나 ( 카프카 생태계에서 빠질 수 없는 아주 중요한 플랫폼 )
카프카에서 데이터 파이프라인을 반복적으로 만들어내고 개발하고 운영할때 효과적이며, 카프카 클러스터를 상용에서 운영하고 있다면, 반드시 도입을 검토해볼만한 중요한 데이터 파이프라인 플랫폼
카프카는 커넥트와 커텍터로 분리되어 있다
Kafka Connect
커넥터를 동작하도록 실행해주는 프로세스, 파이프라인으로 동작하는 커텍터를 동작하기 위해서는 반드시 커넥트를 실행해야한다.
단일 실행모드 커넥트
간단한 데이터 파이프라인을 구성하거나 개발용으로 주로 사용
분산 모드 커넥트
여러개의 프로세스를 한개의 클러스터로 묶어서 운영, 즉, 2개 이상의 커텍트가 하나의 클러스터로 묶인다
해당 커텍트는 일부 커넥트에 장애가 발생하더라도 파이프라인을 자연스럽게 failover(장애조치) 해서 나머지 실행중인 커텍트에서 데이터를 지속적으로 처리
커넥트를 실행할 때 커넥트가 어디에 있는지 config파일에 위치를 지정해야한다 ( 커넥터 jar 패지키의 디렉토리 )
그리고 나서 커넥트를 실행하면, jar파일의 커텍터들을 함께 모아서 커텍터를 실행할 수 있도록 준비상태에 돌입
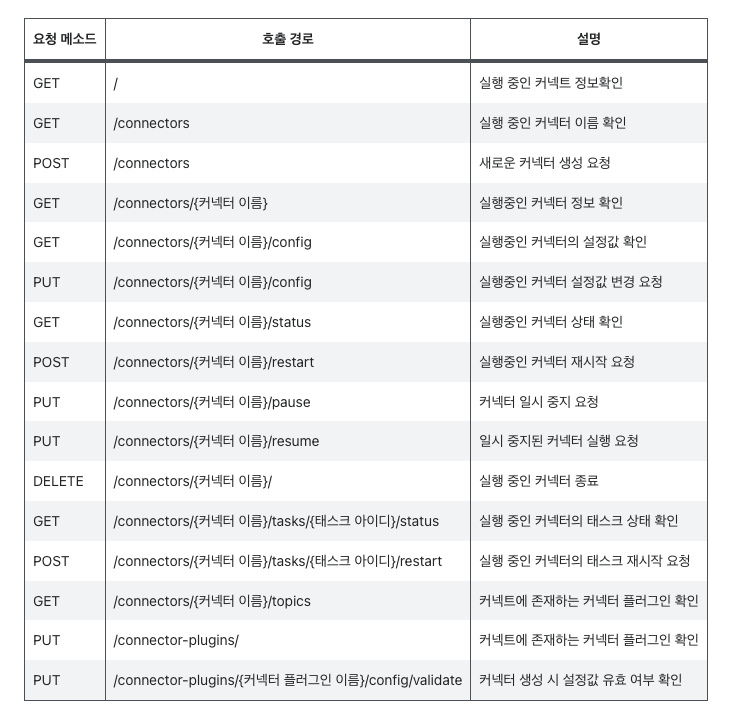
plugin.path=/var/connectors실행중인 커텍트에서 커텍터를 실행하려면 Rest API를 통해서 커텍터를 실행할 수 있다.
💡 커텍트를 활용하면 파이프라인을 만들 때 추가로 개발을 하고 배포를 하는 과정 없이 ***Rest api***를 통해서 커텍터를 통한 파이프라인들이 분산해서 생긴다OracleSinkConnector 예제
특정 토픽에 있는 데이터를 특정 테이블로 보낼때의 파이프라인 생성 요청
echo '
{
"name" : "my-first-pipeline",
"config" : {
"connector.class" : "com.test.OracleSinkConnector",
"connection.url" : "jdbc:oracle://localhost:3306/mydb",
"topics" : "my-test-topic",
"table" : "my-first-stream-table"
}
}
' | curl -X POST -d @- http://localhost:8083/connectors --header "content-Type:application/json"동일한 토픽에 있는 데이터를 다른 테이블에 보낼때의 파이프라인 생성 요청
echo '
{
"name" : "my-second-pipeline",
"config" : {
"connector.class" : "com.test.OracleSinkConnector",
"connection.url" : "jdbc:oracle://localhost:3306/mydb",
"topics" : "my-test-topic",
"table" : "my-second-stream-table"
}
}
' | curl -X POST -d @- http://localhost:8083/connectors --header "content-Type:application/json"Kafka Connector
커텍터는 실질적으로 데이터를 처리하는 코드가 담긴 jar 패키지, 일련의 템플릿과 같은 특정 코드 뭉치
커넥터 안에는 파이프라인에 필요한 여러가지 동작들과 설정, 그리고 실행하는 메서드들이 포함되어 있다.
싱크 커텍터(Sink Connector)
특정 토픽에 있는 데이터를 오라클, mySQL, ES와 같이 특정 저장소에 저장을 하는 역할
즉 컨슈머와 같은 역할을 한다
토픽의 데이터를 특정 디비 테이블에 넣고 싶다면 싱크 커넥터를 만들어야 한다. 그때 싱크 커넥터 글자 앞에 어떤 데이터베이스를 넣을것인지 선언한다
PostgresSQL Sink Connector
소스 커넥터(Source Connector)
데이터베이스로부터 데이터를 가져와서 토픽에 넣는 역할
즉 프로듀서 역할을 한다
