기존에 로그데이터 색인을 배치를 통해 진행하고 있었다. 하지만 해당 방식은 실시간이 될 수 없었고(배치 시간을 아무리 쪼개도 결국 배치가 수행되어야만 색인이 되므로),
Pipeline 구성 필요
배치로 ES에 색인을 하니, 추천 데이터를 바로바로 Refresh가 되지 않았다. 앱을 방문하는 사용자가 여러 검색을 한 경우, 그에 따라 방문시간에 여러 추천 데이터를 보여줘야 하는데, 처음 데이터만 보여주게 되었다. (배치가 다시 수행되어서 변경되기 까지)
이에 따라 실시간으로 로그값이 반영이 되어야 여러 추천상품을 보여주어야 한다.
Pipeline 구성
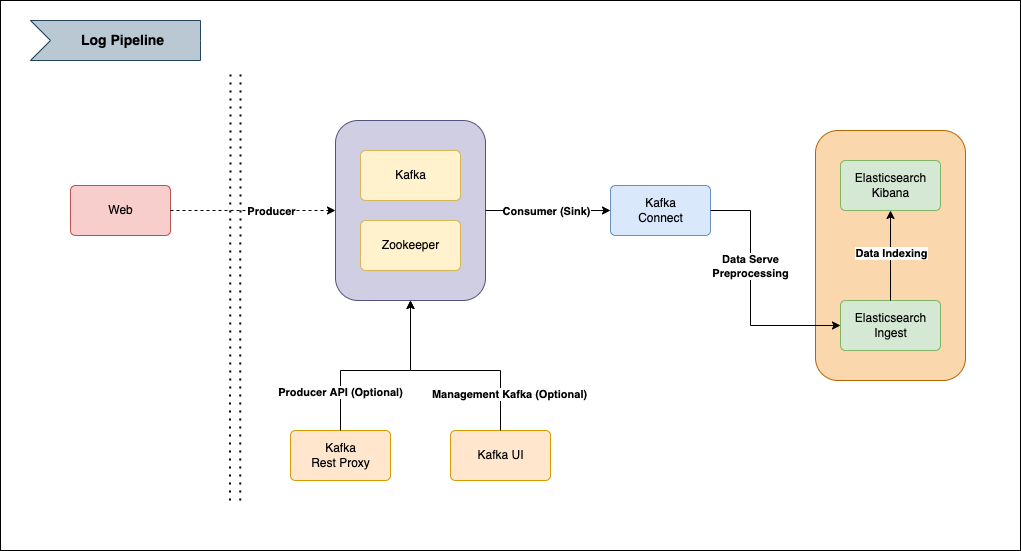
배치를 통한 방식(RDB, HIVE -> ES)은 결국 실시간이 될 수 없다. 실시간이 되려면 최소 초단위로 반영이 되어야 한다.
새롭게 구성되는 로그클러스터 색인 방식은, 데몬형태의 서비스가 지속적으로 체크가 되어야 하며, 그때 체크 대상은 카프카 토픽이 되어야 한다. (이미 카프카로 서비스가 유지되고 있으므로)
이러한 서비스를 하기위해 이미 컨플루언트(Confluent)에서 제공하는 여러 오픈소스 프로젝트들이 존재하여 해당 서비스를 이용한다.
Kafka-connect
반복적인 데이터 파이프라인을 효과적으로 배포하고 관리하는 방법, 카프카에서 공식적으로 제공하는 컴포넌트 중 하나. 카프카에서 데이터 파이프라인을 반복적으로 만들어내고 개발하고 운영할때 효과적이다.
Kafka-rest-proxy
카프카 클러스터를 위한 RESTful interface application을 오픈소스로 제공한다. 직접 코드를 짜지 않고 범용적으로 사용되는 REST api를 사용해서 카프카 Topic에 관련된 일을 처리할 수 있다. ( 해당 예제에서는 로그 데이터 Producer의 역할 )
Kafka-UI
카프카의 상태, 토픽 생성, 관리, 프로듀싱등 간단한 작업 및 확인을 할 수 있는 관리 툴이다. 해당 기능은 옵션
Elasticsearch Ingest pipeline
ES에 데이터를 인덱싱하기 전에 다양한 전처리를 할 수 있는 메커니즘을 pipeline형태로 가공할 수 있는 기능
Example
이제 서버를 띄우고 실제 데이터 까지 넣는 예제를 알아보자.
- 작업 환경 : MacBook Air M1 16G / Docker
Server docker-compose
Kafka / Zookeeper / Kafka-UI
version: '2'
services:
zookeeper:
image: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
tmpfs: "/datalog"
kafka:
#build: .
image: wurstmeister/kafka
container_name: kafka
ports:
- "9092:9092"
- "29092:29092"
environment:
DOCKER_API_VERSION: 1.22
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL
KAFKA_LISTENERS: INTERNAL://kafka:29092,EXTERNAL://localhost:9092
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka:29092,EXTERNAL://localhost:9092
KAFKA_DEFAULT_REPLICATION_FACTOR: 3
KAFKA_NUM_PARTITIONS: 3
volumes:
- /var/run/docker.sock:/var/run/docker.sock
kafka-ui:
image: provectuslabs/kafka-ui
container_name: kafka-ui
ports:
- "8989:8080"
restart: always
environment:
KAFKA_CLUSTERS_0_NAME: kafka_test
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: INTERNAL://kafka:29092,EXTERNAL://localhost:9092
KAFKA_CLUSTERS_0_ZOOKEEPER: zookeeper:2181
networks:
default:
external:
name: pipeline
Kafka-connect
version: '2'
services:
kafka-connect:
image: nentangso/kafka-connect
container_name: "kafka-connect"
ports:
- "8083:8083"
environment:
CONNECT_BOOTSTRAP_SERVERS: "kafka:29092"
CONNECT_REST_ADVERTISED_HOST_NAME: kafka-connect
CONNECT_REST_PORT: 8083
CONNECT_GROUP_ID: "kafka-connect"
CONNECT_CONFIG_STORAGE_TOPIC: kafka-connect-configs
CONNECT_OFFSET_STORAGE_TOPIC: kafka-connect-offsets
CONNECT_STATUS_STORAGE_TOPIC: kafka-connect-status
CONNECT_KEY_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_INTERNAL_KEY_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_INTERNAL_VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_REST_ADVERTISED_HOST_NAME: "kafka-connect-01"
CONNECT_LOG4J_ROOT_LOGLEVEL: "INFO"
CONNECT_LOG4J_LOGGERS: "org.apache.kafka.connect.runtime.rest=WARN,org.reflections=ERROR"
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: "1"
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: "1"
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: "1"
CONNECT_PLUGIN_PATH: /usr/share/java,/usr/share/confluent-hub-components
command:
- bash
- -c
- |
confluent-hub install --no-prompt confluentinc/kafka-connect-elasticsearch:11.2.0
/etc/confluent/docker/run
networks:
default:
external:
name: pipeline
Elasticsearch / Kibana
ingest sample에 관련해서는 다음을 참조한다.
Elasticsearch Ingest pipeline custom sample git
FROM docker.elastic.co/elasticsearch/elasticsearch:7.13.2
COPY ./ingest/7.13.2/sample-ingest-1.0-SNAPSHOT-plugin.zip /usr/share/elasticsearch/sample-ingest-1.0-SNAPSHOT-plugin.zipversion: '2'
services:
elasticsearch:
build:
context: .
dockerfile: Dockerfile
container_name: elasticsearch
environment:
- node.name=elasticsearch
- cluster.name=es-docker-cluster
- discovery.seed_hosts=elasticsearch
- cluster.initial_master_nodes=elasticsearch
- bootstrap.memory_lock=true
- xpack.security.enabled=false
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- data01:/tmp/lima/elasticsearch/data
ports:
- 9200:9200
command:
- bash
- -c
- |
/usr/share/elasticsearch/bin/elasticsearch-plugin install file:///usr/share/elasticsearch/sample-ingest-1.0-SNAPSHOT-plugin.zip
/usr/local/bin/docker-entrypoint.sh eswrapper
kibana:
image: docker.elastic.co/kibana/kibana:7.13.2
container_name: kibana
ports:
- 5601:5601
environment:
- ELASTICSEARCH_HOSTS=["http://elasticsearch:9200"]
depends_on:
- elasticsearch
volumes:
data01:
driver: local
networks:
default:
external:
name: pipeline
kafka-rest-proxy
M1에서 제공하는 rest-proxy docker hub의 이미지는 구동이 되질 않는다. 해서 예전에 커스텀했던 버전의 소스를 가져와서 jar로 빌드하여 테스트를 진행 한다.
java -jar ./kafka-rest-proxy/kafka-rest-7.1.0-standalone.jar ./kafka-rest-proxy/kafka-rest.properties서버 Docker container
Put example data
[Kafka] Create topic
Kafka 서버가 기동 된 이후, Topic을 생성해야 하는데 이때 생성하는 방법은 다음과 같다.
- Kafka-UI를 통한 토픽 생성
- Kafka 서버에서 직접 토픽 생성
해당 예제는 서버에서 직접 토픽을 생성한다.
docker exec kafka sh -c "\
/opt/kafka/bin/kafka-topics.sh --zookeeper zookeeper:2181 --topic elasticsearch-topic --create --partitions 3 --replication-factor 1 ; \
/opt/kafka/bin/kafka-topics.sh --zookeeper zookeeper:2181 --list ;"[Elasticsearch] Create Ingest
데이터 전처리를 수행할 수 있는 Ingest pipeline을 생성한다.
PUT _ingest/pipeline/ingest-sink
{
"description": "파이프라인 인제스트 싱크 테스트",
"processors": [
{
"set": {
"description": "Ingest된 시간을 기록",
"field": "_source.ingest_time",
"value": "{{_ingest.timestamp}}"
}
},
{
"example": {
"field" : "test1",
"event" : "A"
}
},
{
"example": {
"field" : "test2",
"event" : "B"
}
},
{
"example": {
"field" : "test3",
"event" : "C"
}
}
]
}[Elasticsearch] Create Index
토픽의 데이터가 색인되는 인덱스를 생성하되, 기존에 생성한 Ingest pipeline과 연결한다.
PUT elasticsearch-topic
{
"settings": {
"index.default_pipeline": "ingest-sink"
},
"mappings": {
"properties": {
"test1": {
"type": "text"
},
"test2": {
"type": "keyword"
},
"test3": {
"type": "keyword"
}
}
}
}[Kafka connect] Create sink connector
POST http://localhost:8083/connector
{
"name": "elasticsearch-sink",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"tasks.max": "1",
"topics": "elasticsearch-topic",
"key.ignore": "true",
"schema.ignore": "true",
"connection.url": "elasticsearch:9200",
"connection.username": "null",
"connection.password": "null",
"type.name": "_doc",
"name": "elasticsearch-sink",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "false",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false"
}
}[Kafka rest proxy] Sample data Producing
테스트의 포트 18094는 기본포트가 아니다
Url : "http://localhost:18094/topics/elasticsearch-topic"
Header : "Content-Type: application/vnd.kafka.json.v2+json"
Data
{
"records": [
{
"value": {
"test1": "test1",
"test2": "test2",
"test3": "test3"
}
}
]
}Example test shell script
server
#!/bin/bash
echo "Kafka pipeline sample process..."
sleep 3
echo "Step 0. Container all remove"
docker rm -f $(docker ps -a -q)
sleep 1
echo "Step 1. Container Volume all remove"
docker volume rm $(docker volume ls -q)
sleep 1
echo "Step 2. Clean docker"
docker system prune --volumes --force
sleep 1
echo "Step 3. Create Network cluster"
docker network create -d bridge pipeline
sleep 1
echo "Step 4. Run Service Zookeeper / Kafka / Kafka-UI"
docker-compose -f ./kafka/docker-compose.yml up -d
sleep 5
echo "Step 5. Run Service Elasticsearch / Kibana..."
cd elasticsearch
docker-compose build --no-cache
docker-compose -f ./docker-compose.yml up -d
cd ..
sleep 5
echo "Step 6. Run Service Kafka connect"
docker-compose -f ./kafka-connect/docker-compose.yml up -d
sleep 5
echo "Step 7. Run Service Kafka rest proxy"
java -jar ./kafka-rest-proxy/kafka-rest-7.1.0-standalone.jar ./kafka-rest-proxy/kafka-rest.propertiesData
#!/bin/bash
create_connector()
{
cat <<EOF
{
"name": "elasticsearch-sink",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"tasks.max": "1",
"topics": "elasticsearch-topic",
"key.ignore": "true",
"schema.ignore": "true",
"connection.url": "elasticsearch:9200",
"connection.username": "null",
"connection.password": "null",
"type.name": "_doc",
"name": "elasticsearch-sink",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "false",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false"
}
}
EOF
}
create_ingest()
{
cat <<EOF
{
"description": "파이프라인 인제스트 싱크 테스트",
"processors": [
{
"set": {
"description": "Ingest된 시간을 기록",
"field": "_source.ingest_time",
"value": "{{_ingest.timestamp}}"
}
},
{
"example": {
"field" : "test1",
"event" : "A"
}
},
{
"example": {
"field" : "test2",
"event" : "B"
}
},
{
"example": {
"field" : "test3",
"event" : "C"
}
}
]
}
EOF
}
create_index()
{
cat <<EOF
{
"settings": {
"index.default_pipeline": "ingest-sink"
},
"mappings": {
"properties": {
"test1": {
"type": "text"
},
"test2": {
"type": "keyword"
},
"test3": {
"type": "keyword"
}
}
}
}
EOF
}
producer_data()
{
cat <<EOF
{
"records": [
{
"value": {
"test1": "test1",
"test2": "test2",
"test3": "test3"
}
}
]
}
EOF
}
echo "Kafka pipeline example..."
sleep 3
echo "Step 1. Create Topic (Check Kafka-UI [http://localhost:8989])"
docker exec kafka sh -c "\
/opt/kafka/bin/kafka-topics.sh --zookeeper zookeeper:2181 --topic elasticsearch-topic --create --partitions 3 --replication-factor 1 ; \
/opt/kafka/bin/kafka-topics.sh --zookeeper zookeeper:2181 --list ;"
sleep 3
echo
echo "Step 2. Create Ingest"
jq <<< `curl -d "$(create_ingest)" \
-H "Content-Type: application/json" \
-X PUT "http://localhost:9200/_ingest/pipeline/ingest-sink"`
sleep 3
echo
echo "Step 3. Create Index"
jq <<< `curl -d "$(create_index)" \
-H "Content-Type: application/json" \
-X PUT "http://localhost:9200/elasticsearch-topic"`
sleep 3
jq <<< `curl -X GET "http://localhost:9200/elasticsearch-topic"`
sleep 1
echo
echo "Step 4. Kafka connect Create sink connector"
jq <<< `curl -d "$(create_connector)" \
-H "Content-Type: application/json" \
-X POST "http://localhost:8083/connectors"`
# Connector list
echo
jq <<< `curl -s -X GET http://localhost:8083/connector-plugins|jq '.[].class'`
echo
echo "Step 5. Producing example data"
jq <<< `curl -d "$(producer_data)" \
-H "Content-Type: application/vnd.kafka.json.v2+json" \
-X POST "http://localhost:18094/topics/elasticsearch-topic"`
