문자함수
함수를 이용하면 문자의 내용을 쉽게 변경할 수 있다.
( 괄호 ) 안에 컬럼을 넣어서 해당 데이터 전체를 변경 할 수도 있다.
| 함수 | 내용 | 출력 |
|---|---|---|
LOWER('APPLE') | 데이터를 소문자로 바꾼다 | apple |
UPPER(컬럼) | 데이터를 대문자로 바꾼다 | 대문자로 출력 |
LENGTH('ALIVE') | 데이터의 길이를 출력(BYTE) | 5 |
CONCAT('I','LOVE','U') | 입력된 데이터를 하나로 이어서 출력 | ILOVEU |
SUBSTR('ABCDEFG',3,3) | 데이터를 3번째 부터 3개를 출력 | CDE |
SUBSTR('ABCDEFG',3) | 데이터를 3번째 끝까지 출력 | CDEFG |
SUBSTR('ABCDEFG',-6,2) | 데이터를 오른쪽에서 6번째 부터 2개 출력 | BC |
INSTR('A*B#','#') | 입력해준 문자가 몇번째에 있는지 출력 | 4 |
LPAD('LOVE' ,6, '$') | '$'을 데이터 왼쪽에 붙여서 6자리로 출력 | $$LOVE |
RPAD('LOVE', 6, '*') | '*'을 데이터 오른쪽에 붙여서 6자리로 출력 | LOVE** |
REPLACE ('AB' , 'A' ,'E' ) | 데이터의 문자를 변경 | EB |
위 예시는 문자를 넣었지만 앞서 말했든 함수에는 컬럼이 들어갈 수 있다.
실제 데이터를 구해보자
SELECT LENGTH('홍길') "NAME" FROM DUAL;- '홍길'이라는 단어의 길이를 바이트로 출력한다.
일반적으로 영어나 숫자는 1바이트 한글은 2바이트지만UTF-8인코딩에서 한글은 2~3바이트가 된다.
받침이 있는 한글일 경우 3바이트가 되고 자음+모음일 경우는 2바이트가 된다.
MySQL에서 일반적인 인코딩 방식은 UTF-8 이므로 위 예시에서 '홍길'은 6바이트가 된다.
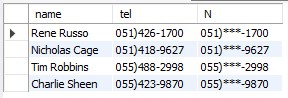
- 전화번호에서 중간번호를 ***로 가리는 방법
SELECT name, tel,
replace(tel,
substr(tel, instr(tel, ')') +1, 3),
'***') as N
FROM student
WHERE deptno1 = 102;
- 전화번호에서 지역번호만 따로 출력할 수 있게 해준다.
SELECT name, tel,
substr(tel, 1, (
instr(tel, ')')
) -1
) as "AREA CODES"
FROM student
WHERE deptno1 = 201;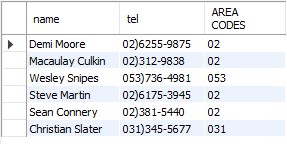
- 전화번호에서 중간번호를 출력할 수 있다.
SELECT NAME, TEL,
SUBSTR(TEL,
INSTR(TEL, ')') +1,
INSTR(TEL, '-') - INSTR(TEL, ')') -1
) AS GUK_NO
FROM STUDENT
WHERE DEPTNO1 = 101;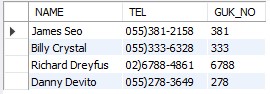
- 이름을 포함하여 1~9까지 출력한다
SELECT
rpad(ename, 9, substr('123456789',
length(ENAME)+1)
) name
FROM emp
WHERE deptno = 10;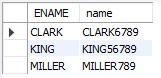
- 이메일에서 특정단어를 빼낼 수 있다
SELECT name, email,
substr(email,
instr(email, '@') +1,
instr(email, '.') - instr(email, '@') -1
) AS domain
FROM professor
WHERE email is not null; 
숫자함수
함수를 이용하면 다음과 같은 출력을 할 수 있다.
| 함수 | 내용 | 출력 |
|---|---|---|
ABS(-24) | 절댓값을 출력한다 | 24 |
ROUND(12345.6789, 2) | 데이터를 소수점 아래 2번째까지 출력(반올림) | 12345.68 |
MOD(A,B) | A를 B로 나눈 나머지, B가 크면 A출력 | A%B |
CEIL(12.3456) | 입력한 수를 소수점 첫번째에서 올려서 정수단위로 출력 | 13 |
FLOOR(4.936) | 입력한 수를 소수점 첫번째에서 내려서 정수단위로 출력 | 4 |
POWER (4,3) | A를 B번 제곱 | 64 |
그룹 함수
| 함수 | 내용 |
|---|---|
| COUNT | 데이터의 수를 출력 |
| SUM | 합계를 출력 |
| AVG | 평균을 출력 |
| MAX | 최대를 출력 |
| MIN | 최소를 출력 |
| STDDEV | 표준편차 출력 |
| VARIANCE | 분산 출력 |
COUNT()함수와WHERE이나GROUP BY를 이용하면 조건의 데이터 수나 고객 수를 출력할 수 있다.
SELECT
COUNT(CustomerID), Country
FROM Customers
GROUP BY CountrySELECT
user_id, count(*)
FROM rental
GROUP BY user_id;AVG는 실존하는 데이터들의 평균을 구한다.
평균을 구할때 NULL은 계산하지 않지만
IFNULL같은 함수로 NULL 에 값을 준다면 모든 데이터로 평균을 구한다
- 아래 테이블에서 부서당 최신 공지만 뽑아낸다면
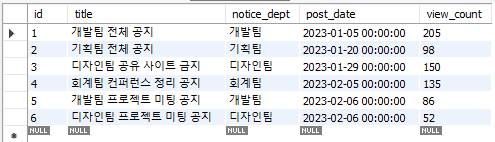
SELECT
id, notice_dept, title, view_count,
DATE_FORMAT(post_date, '%Y-%m-%d') AS 'current_date'
FROM notice
WHERE (notice_dept, post_date) IN (
SELECT
notice_dept, MAX(post_date) AS 'max_post_date'
FROM notice
GROUP BY notice_dept
);MAX를 사용해서 GROUP BY 와 함께 결과를 뽑아낸 후
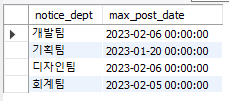
IN을 이용해서 해당하는 공지만 추출한다.

LIMIT, UNION
LIMIT(2,5) 은 2번 인덱스에서 5개를 출력, 인덱스는 0번부터 시작하니 3번째부터 5개의 데이터가 출력된다.
UNION 은 컬럼 타입과 갯수가 동일하면 두 테이블을 붙여서 중복된 로우를 제거한다
UNION ALL은 모두 붙여서 출력한다
위의 내용들을 이용해보면
select deptno
, job
, round(avg(sal), 1) "AVG_SAL"
, count(*) "CNT_EMP"
from emp
group by deptno, job -- 9
union all -- 퓨전
select deptno
, null
, round(avg(sal), 1) "AVG_SAL"
, count(*) "CNT_EMP"
from emp
group by deptno -- 3
union all -- 퓨전
select null
, null
, round(avg(sal), 1) "AVG_SAL"
, count(*) "CNT_EMP"
from emp
order by deptno desc;
집계함수 ROLLUP
ROLLUP 사용하면 GROUP BY로 묶은 각각의 소그룹 합계와 전체 합계를 모두 구할 수 있다.
null 값은 계산에서 제외된다.
위 내용을 간단하게 만들어줄 집계함수를 이용하면
select deptno
, job
, round(avg(sal), 1) "AVG_SAL"
, count(*) "CNT_EMP"
from emp
group by deptno, job
with rollup; 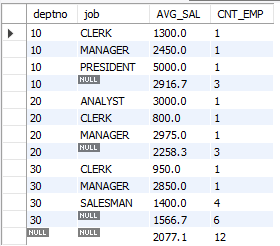

작은것부터