쿼리의 조건을 늘려가다 보면 가독성이 나빠지고 코드 작성에도 시간이 걸린다
이러한 문제를 해결하기 위해 OVER 함수를 사용한다.
OVER 함수의 다양한 활용
OVER 함수는 여러 함수와 함께 이용할 수가 있는데
코드로 예로 들어보면
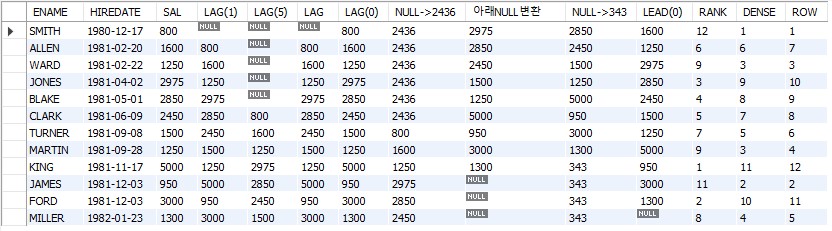
LAG은 마치 랙걸린것처럼 아래로 밀리게 되고 LEAD는 반대로 밀린다.
SELECT ENAME
,HIREDATE
,SAL
,LAG(SAL,1) OVER(ORDER BY HIREDATE) "LAG(1)"
# 한칸씩 아래로 밀리는데 SMITH 위의 데이터가 없기 때문에 NULL이 온다
,LAG(SAL,5) OVER(ORDER BY HIREDATE) "LAG(5)"
# 5칸이 밀리게 된다.
,LAG(SAL) OVER(ORDER BY HIREDATE) "LAG"
# 컬럼만 입력하면 (컬럼,1)과 같다
,LAG(SAL,0) OVER(ORDER BY HIREDATE) "LAG(0)"
# 0일때는 밀리지 않는다
,LAG(SAL,6,2436) OVER(ORDER BY HIREDATE) "NULL->2436"
# 6다음 데이터를 입력하면 NULL 이 입력한 데이터로 변환
,LEAD(SAL,3) OVER(ORDER BY HIREDATE) "아래NULL변환"
# LEAD는 LAG의 반대로 위로 밀린다
,LEAD(SAL,4,343) OVER(ORDER BY HIREDATE) "NULL->343"
# 위로 밀려서 생긴 아래의 NULL 을 343 으로 변환
,LEAD(SAL) OVER(ORDER BY HIREDATE) "LEAD(0)"
# 마찬가지로 (컬럼,1)과 같다
,RANK()OVER(ORDER BY SAL DESC) 'RANK'
# 순위를 매겨준다
,dense_rank()OVER(order by SAL) 'DENSE'
# 중복이 되더라도 순서를 건너 뛰지 않음 1,2,2,4,5 X -> 1,2,2,3,4,
,ROW_NUMBER()OVER(order by SAL) 'ROW'
# 순위가 같더라도 임의적으로 순위를 나눈다 1,2,2,4,5 X -> 1,2,3,4,5
FROM EMP ORDER BY HIREDATE;
SELECT * FROM EMP;아래의 결과를 얻을 수가 있다
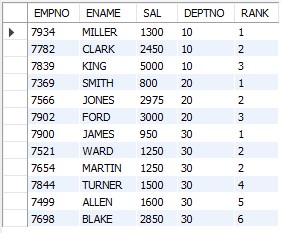
OVER 함수는 PARTITION BY 와 ORDER BY 를 동시에 사용하여 원하는 조건의 정렬로 데이터를 볼 수 있다.
SELECT
EMPNO, ENAME, SAL , DEPTNO,
RANK() OVER(PARTITION BY DEPTNO ORDER BY SAL) AS 'RANK'
FROM EMP; DEPTNO 가 같은 조건의 SAL 정렬순으로 순위를 볼 수 있다.
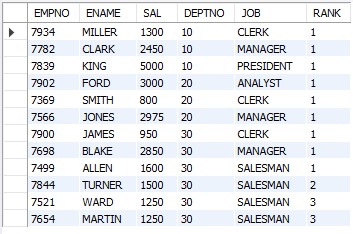
PARTITION BY 과 ORDER BY 는 여러개의 조건을 줄 수 있다.
SELECT
EMPNO, ENAME, SAL, DEPTNO,JOB,
RANK() OVER(partition by DEPTNO, JOB ORDER BY SAL DESC ) AS 'RANK'
FROM EMP;DEPTNO JOB 이 같을 때의 SAL 의 순위를 매긴다.
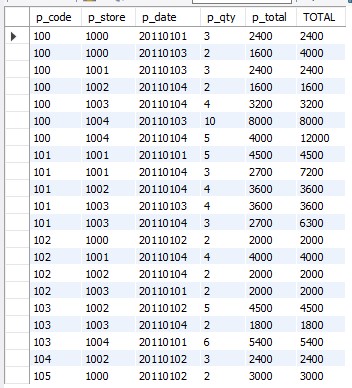
다른 코드도 보자
- 예제1
select
p_code, p_store, p_date,
p_qty, p_total,
sum(p_total) over(partition by p_code, p_store order by p_date) as "TOTAL"
from panmae; P_CODE , P_STORE가 같을 때의 p_date 순서로 합을 TOTAL 에 출력
- 예제2
select
name, tel, position, pay,
rank() over (partition by
substr(tel, 1, instr(tel,')') - 1)
order by pay desc) AS 'rank'
from emp2;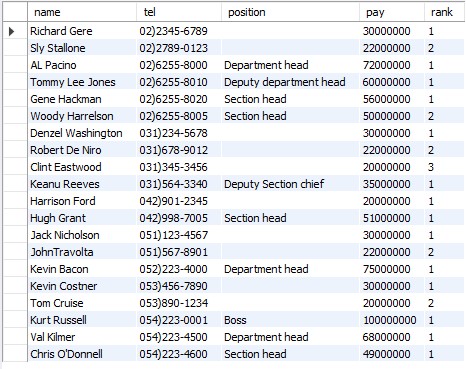
- 예제3
select
substr(email, instr(email,'@') + 1) as domain,
count(*) AS ea,
sum(count(*)) over() AS sum_domain,
count(email) / sum(count(*)) over() * 100 as '%'
from professor
group by 1 order by 1;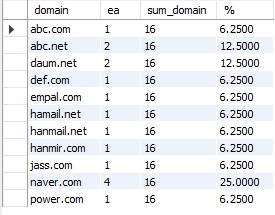

작은것부터