이번주 범위

여러 개의 Flow를 합치기
zip
시퀀스의 zip 확장함수처럼, 플로우도 zip연산자를 통해서 두 개 플로우의 value들을 합칠 수 있다.
val nums = (1..3).asFlow() // numbers 1..3
val strs = flowOf("one", "two", "three") // strings
nums.zip(strs) { a, b -> "$a -> $b" } // compose a single string
.collect { println(it) } // collect and print1 -> one
2 -> two
3 -> three
nums라는 플로우와 strs라는 플로우를 zip으로 합쳐서 스트림 구조 상 인덱스(?적절한 표현인지는 모르겠음)가 매칭되는 value들을 하나씩 인자로 받을 수 있다.
만약 nums의 범위를 1..4로 수정하더라도 출력 결과는 변하지 않는다. 즉, 두 플로우 중 더 작은 갯수의 value를 가진 플로우를 기준으로만 zip연산이 진행되고 멈춘다.
이런 특성 때문에, nums는 300ms마다 업데이트되고 strs는 400ms마다 업데이트 되는 경우 zip연산을 사용하면 400ms마다 업데이트된다. 즉, 둘 다 바뀌어야만 적용된다.
val nums = (1..3).asFlow().onEach { delay(300) } // numbers 1..3 every 300 ms
val strs = flowOf("one", "two", "three").onEach { delay(400) } // strings every 400 ms
val startTime = System.currentTimeMillis() // remember the start time
nums.zip(strs) { a, b -> "$a -> $b" } // compose a single string with "zip"
.collect { value -> // collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
} 1 -> one at 438 ms from start
2 -> two at 838 ms from start
3 -> three at 1241 ms from start
3번 출력된 것을 보아 위에서 우리가 학습한대로 zip연산은 둘이 모두 바뀌어야만 연산이 적용된다.
combine
만약 여러 개의 플로우들을 결합할 때, 한 개의 플로우라도 새로운 값이 방출될 때마다 특정한 연산을 수행하게 하고 싶을 수 있다. 이런 요구사항을 들어줄 수 있는 연산자가 바로 combine이라고 한다.
val nums = (1..3).asFlow().onEach { delay(300) } // numbers 1..3 every 300 ms
val strs = flowOf("one", "two", "three").onEach { delay(400) } // strings every 400 ms
val startTime = System.currentTimeMillis() // remember the start time
nums.combine(strs) { a, b -> "$a -> $b" } // compose a single string with "combine"
.collect { value -> // collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
} 1 -> one at 442 ms from start
2 -> one at 645 ms from start
2 -> two at 845 ms from start
3 -> two at 946 ms from start
3 -> three at 1245 ms from start
둘 중 하나만 바뀌더라도 연산이 실행되는 것을 알 수 있다.
플로우를 평탄화하기
평탄화? 보통 컬렉션이나 시퀀스를 사용할 때 많이 만나봤을 수 있을 것 같다.
예를 들어 2차원 배열을 1차원 배열로 바꾸는 것을 우리는 평탄화라고 부른다.
다음과 같은 코드가 있다고 생각해보자.
fun requestFlow(i: Int): Flow<String> = flow {
emit("$i: First")
delay(500) // wait 500 ms
emit("$i: Second")
}
(1..3).asFlow().map { requestFlow(it) }이때 마지막 줄의 객체는 Flow<Flow<Int>> 타입이다.
실제로 IDE환경에서 확인을 해봤다. 위의 예시 코드와 완전 똑같은 코드는 아니지만 구조상 같다는 것을 확인할 수 있다.
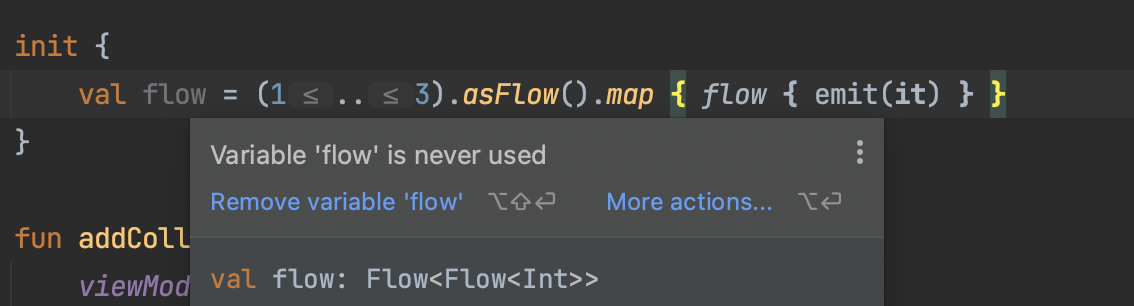
이런 중첩 구조의 플로우를 수집하고 싶은 경우, 평탄화를 해야 정상적으로 모든 값을 받을 수 있다.
만약 평탄화 없이 수집한다면 어떨까?
val startTime = System.currentTimeMillis() // remember the start time
(1..3).asFlow().onEach { delay(100) } // emit a number every 100 ms
.map { requestFlow(it) }
.collect { value -> // collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
} kotlinx.coroutines.flow.SafeFlow@e580929 at 122 ms from start
kotlinx.coroutines.flow.SafeFlow@27f674d at 223 ms from start
kotlinx.coroutines.flow.SafeFlow@1d251891 at 323 ms from start
출력결과를 보면 알 수 있듯이 map에서 반환한 플로우 객체 그 자체를 반환하고 있는 것을 알 수 있다. 아마 우리가 원한 결과와는 다를 수 있다.
flatMapConcat
그렇다면, 이번에는 flatMapConcat을 사용해보자.
val startTime = System.currentTimeMillis() // remember the start time
(1..3).asFlow().onEach { delay(100) } // emit a number every 100 ms
.flatMapConcat { requestFlow(it) }
.collect { value -> // collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
} 1: First at 132 ms from start
1: Second at 633 ms from start
2: First at 734 ms from start
2: Second at 1234 ms from start
3: First at 1334 ms from start
3: Second at 1835 ms from start
위와 같은 결과가 나온다. 즉, flatMapConcat의 블록 안에서 변조되어 나온 플로우가 모두 완료될 때까지 기다리고 다음 흐름을 수집하기 시작한다. 위에서 사용한 일반적인 map을 사용할때와는 확연히 다르다.
그렇다면, 내부가 어떻게 되어있는걸까?
flatMapConcat이 받은 인자는 T타입을 활용해서 Flow<R>타입 객체를 반환하는 람다임.
그리고 이 람다를 그냥 map함수에 넘겨준다. map함수는 Flow로 한 번 감싸서 뱉어내는 함수이기 때문에 여기까지는 2차원 플로우를 반환하는 것과 동일하다.
그리고 대망의 flattenConcat을 찾아봐야 하는데 다음과 같다. 애초에 2차원 플로우만 사용할 수 있는 함수였다!!
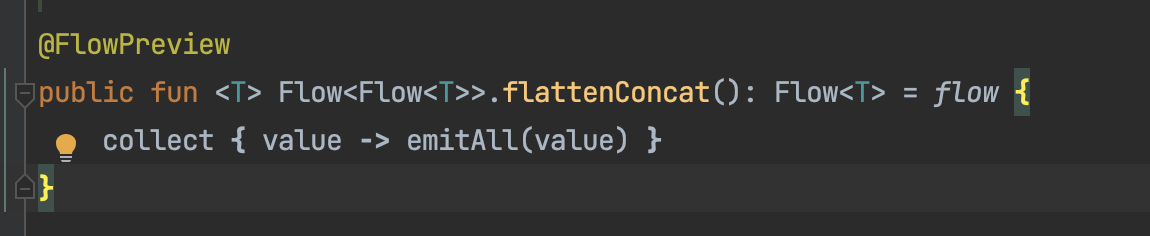 그리고 안에서 collect를 하면서 2차원 플로우 안에 있는 플로우들을 하나씩 받으면서 해당 플로우에 대해 emitAll을 하고 모든 값을 방출시킨다.
그리고 안에서 collect를 하면서 2차원 플로우 안에 있는 플로우들을 하나씩 받으면서 해당 플로우에 대해 emitAll을 하고 모든 값을 방출시킨다.
그림으로 그려보면 아래와 같은 구조다. 각 파이프라인들이 하나로 이어진다고 생각하면 된다.정확히는 한 파이프라인이 끝나야 다음 파이프라인에 대해 실행이 가능한 구조이다.
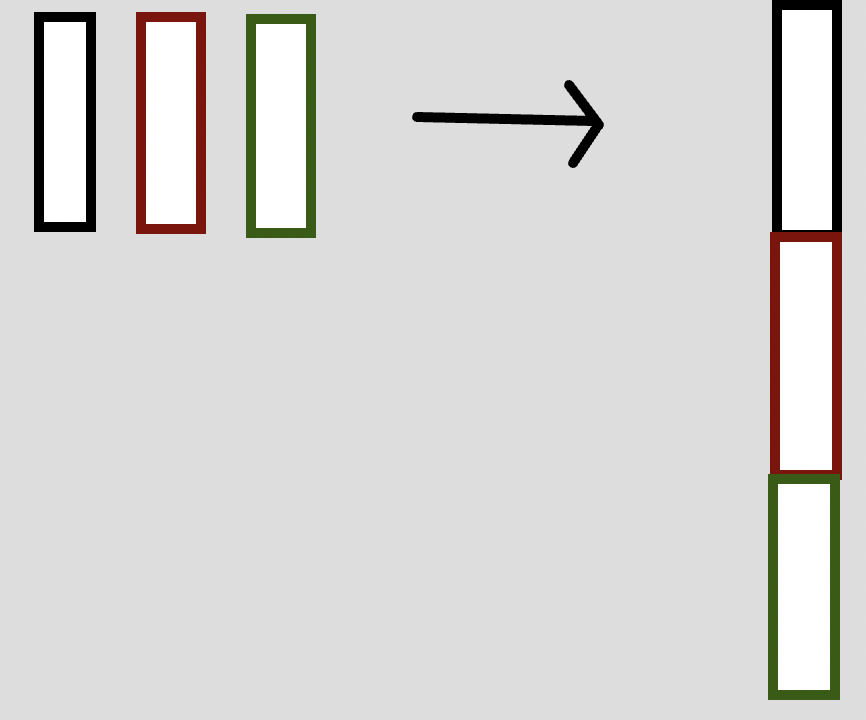
flatMapMerge
flatMapConcat은 2차원 플로우에 대해서 다음과 같이 동작했다. 플로우가 방출한 플로우가 방출하는 모든 값을 수집하고, 다음 플로우에 대해 반복한다. 즉, 2차원 플로우가 뱉은 플로우를 순차적으로 처리한다.
flatMapMerge는 이와 다르다. 2차원 플로우가 뱉은 모든 플로우를 동시에 수집하고, 이 녀석들 중 가능한 빨리 뱉는 녀석을 먼저 수집하도록 한다.
val startTime = System.currentTimeMillis() // remember the start time
(1..3).asFlow().onEach { delay(100) } // a number every 100 ms
.flatMapMerge { requestFlow(it) }
.collect { value -> // collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
} 1: First at 136 ms from start
2: First at 231 ms from start
3: First at 333 ms from start
1: Second at 639 ms from start
2: Second at 732 ms from start
3: Second at 833 ms from start
그렇다면, 원형인 선언부는 어떻게 생겼을까? 아래와 같다.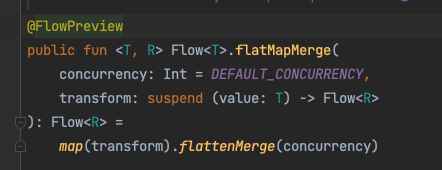 flatMapMerge는 아래와 같은 그림이라고 볼 수 있다. 병렬적인 파이프라인에 공을 떨어뜨릴떄 먼저 내려오는 공이 방출되는 구조다.
flatMapMerge는 아래와 같은 그림이라고 볼 수 있다. 병렬적인 파이프라인에 공을 떨어뜨릴떄 먼저 내려오는 공이 방출되는 구조다.
잠깐, 여기서 함수 원형을 봤을 때 concurrency 라는 매개변수를 봤다. 이것의 역할은 병렬적으로 처리할 최대 파이프라인(=플로우)의 갯수를 의미한다.
상수 설정을 따로 해주지 않았다면 16이 기본값이다.
flatMapLatest
예전에 배웠던 collectLatest와 원리가 유사하다. 만약 flatMapLatest에게 최신 값이 들어온다면, 그 안에서 실행하고 있던 블록 내 플로우를 취소한다. 아래의 결과를 보면 알 수 있다. 정확히 "{ requestFlow(it) }" 이 부분이 취소된다는 것을 볼 수 있다.
val startTime = System.currentTimeMillis() // remember the start time
(1..3).asFlow().onEach { delay(100) } // a number every 100 ms
.flatMapLatest { requestFlow(it) }
.collect { value -> // collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
} 1: First at 167 ms from start
2: First at 296 ms from start
3: First at 398 ms from start
3: Second at 898 ms from start
참고
https://kotlinlang.org/docs/flow.html#composing-multiple-flows
