1. Intro - 고생길의 시작...
인티그레이션은 보건의료직군 대상으로 커뮤니티 서비스를 제공하고 있습니다. 메디스트림은 한의사(한의대생)을 대상으로한 종합 전문직 커뮤니티 플랫폼 서비스이고 모어덴, 치즈톡은 각각 치과의사(치대생)과 치과위생사(치위생대생)을 대상으로 한 서비스입니다.
인티그레이션의 모든 스쿼드(사업부)는 각각의 사업 지표를 실시간으로 확인 할 수 있는 대시보드 및 이를 디스플레이하는 공용 모니터를 가지고 있습니다. 이를 통해 데이터를 기반으로 논의하는 문화를 사업 초기부터 지금까지 중요한 가치로 여기고 실행하고 있습니다.
또한 각 사업부를 대상으로 정확한 데이터를 적시에 제공하는 일을 미션으로 하는 기능 조직인 데이터 전문팀이 있습니다.
데이터 팀은 DE, DS, DA, BA 등 데이터 관련 각각의 역할을 수행하는 팀원으로 구성되어 있고 인프라 구축부터 인공지능 분석업무까지 수행합니다.

메디스트림 프로덕트의 경우, 데이터 분석 인프라 환경을 비교적 잘 갖추어 놓았습니다. 하지만, 모어덴/치즈톡 서비스의 데이터 인프라는 그에비해 조금... 클래시컬? 한 상황이었습니다.
그렇지만 셋 모두 커뮤니티를 기반으로하는 서비스라는 공통점으로 인해, 비슷한 유형 및 패턴의 데이터 흐름이 많았습니다. 그리하여 메디스트림의 데이터 분석 인프라를 그대로 횡전개하여 이식하기로 결정했습니다. 이번 프로젝트를 통해 몇 가지 중요한 변화가 있었는데요, 하나씩 자세히 살펴보며 배웠던 점들을 정리하겠습니다.
고도화 포인트 요약
-
사용자 행동 데이터 수집 툴 변경:
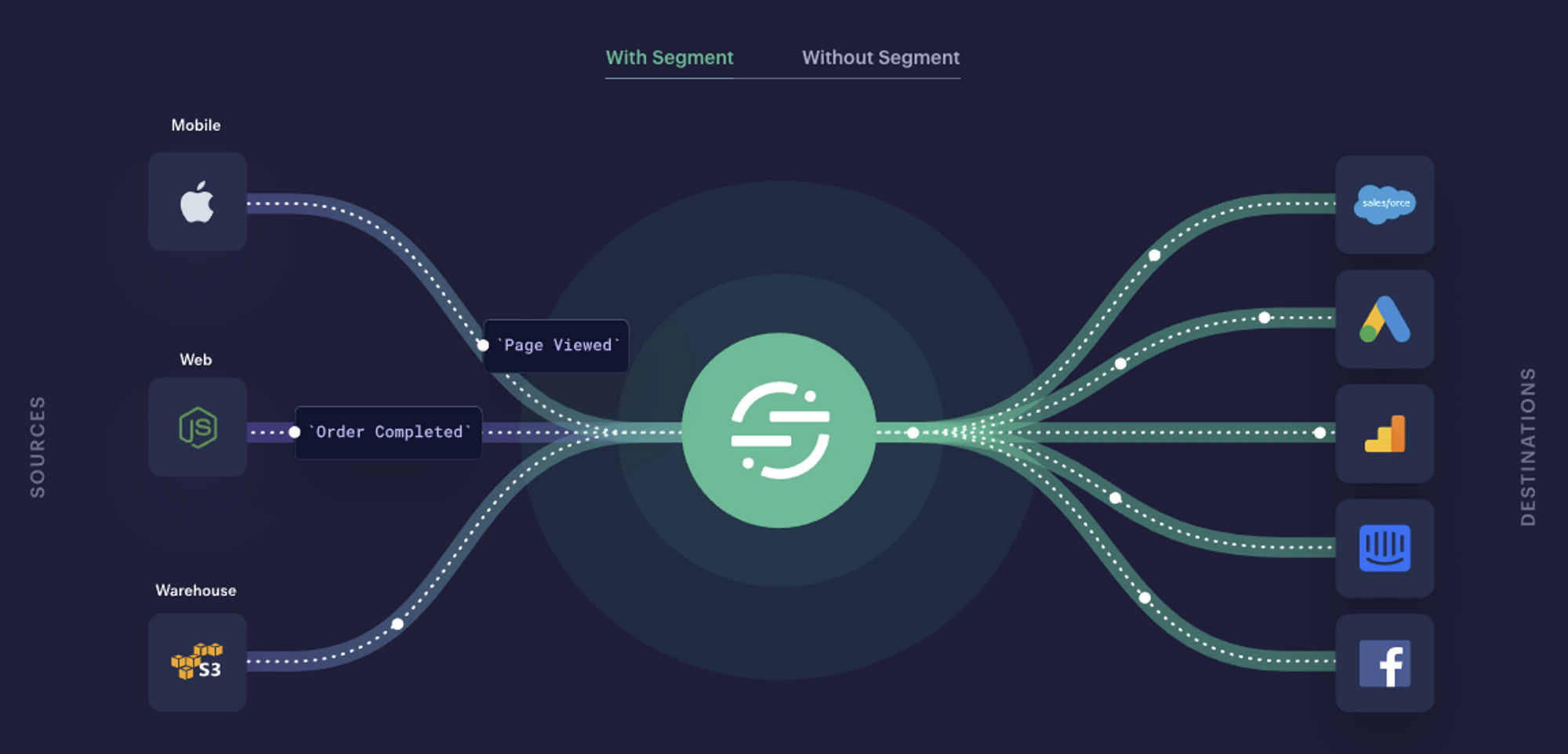
기존에는Google Analytics 4(GA4)를 사용하여 사용자 행동 데이터를 수집하고 있었습니다. 그러나 이번 프로젝트에서는Segment를 도입하여 더욱 유연하고 확장 가능한 수집 시스템을 구축했습니다.
Segment는 사용자 이벤트 수집/전송에 특화된 서비스를 제공합니다. 다양한 소스(웹, 모바일, 앱 등) 에서 이벤트 수집이 가능하고, 수집된 이벤트를 또 다양한 분석 플랫폼으로 전송 기능을 제공합니다. 이로써앰플리튜드,GA4등과 같은 분석 플랫폼마다 각각의 이벤트를 심고 유지관리하는 일이 없어집니다!
-
데이터 인프라 구축:
새로운 데이터 인프라를 구축하기 위해 datalake, data warehouse, 데이터 파이프라인을 구축하였습니다. 이렇게 하여 데이터를 좀 더 효율적으로 저장하고 처리할 수 있습니다. -
workflow 오케스트레이션 도구 도입:
데이터 워크플로 관리를 쉽게 하기 위해Apache Airflow를 도입했습니다. 이를 통해 데이터 이동 및 처리 작업을 자동화하고 모니터링할 수 있습니다.Workflow Orchestrator 는 데이터팀이 복잡한 파이프 라인을 구축하고, 제 시간에 실행되는지 확인하고, 문제가 발생하면 경고하는데 도움을 줍니다. 가장 인기있는 오픈 소스 도구는
Airflow이며,Luigi가 바싹 쫒아가고있고,Prefect와Dagster등도 있습니다. -
BI (Business Intelligence) 대시보드 도구 추가:
비즈니스 인텔리전스 대시보드(BI 툴)을 더욱 강화하기 위해Redash에 추가로Superset을 도입했습니다. 이로써 더 다양한 그래프와 시각화를 생성하고 비개발자도 사용할 수 있게 되었습니다.
2. 데이터레이크, 데이터웨어하우스, 데이터 파이프라인 구축 작업
데이터레이크 vs 데이터웨어하우스
데이터레이크, 데이터웨어하우스 두개의 비슷한 개념이 어떠한 차이가 있는지는 이 블로그에서 자세히 보시면 좋을 것 같습니다.
간단히 데이터레이크는 정형, 비정형, 반정형 상관없이 모든 데이터를 하나의 저장소에서 관리하기 위한 개념이고
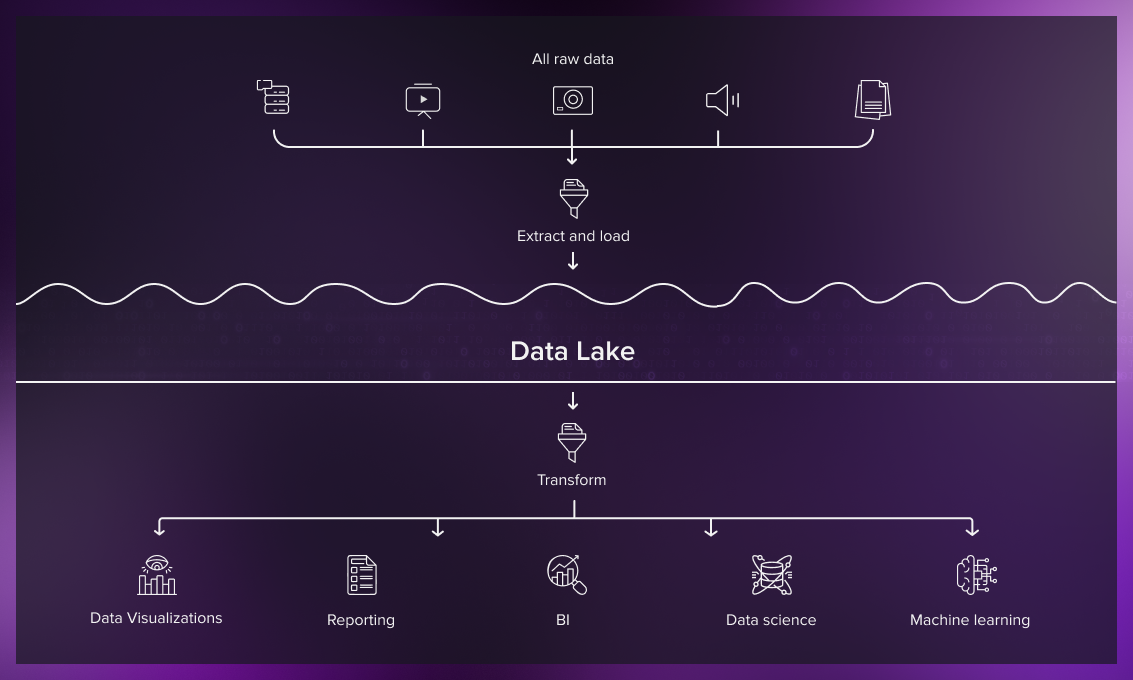
데이터웨어하우스는 잘 정돈된 데이터를 한 곳에서 사용자들이 쉽고 빠르게 사용할 수 있도록 한 저장소를 나타냅니다.
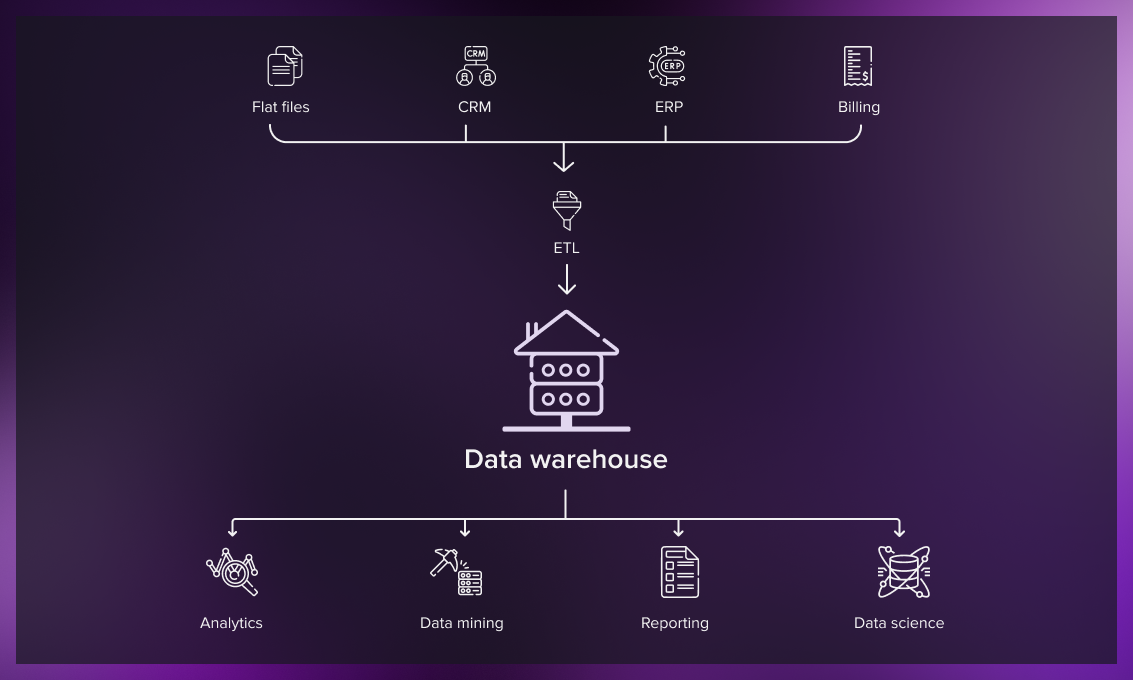
(출처: https://serokell.io/blog/data-warehouse-vs-lake-vs-lakehouse )

ETLT
데이터레이크(DL), 데이터웨어하우스(DW) 모두 공통적으로 소스에서 데이터를 퍼오는 과정이 필요합니다. 이를 ETL, ELT 등으로 표현을 하는데요, 저희는 아래 그림처럼 간단한 ETLT 파이프라인을 구축하였습니다.
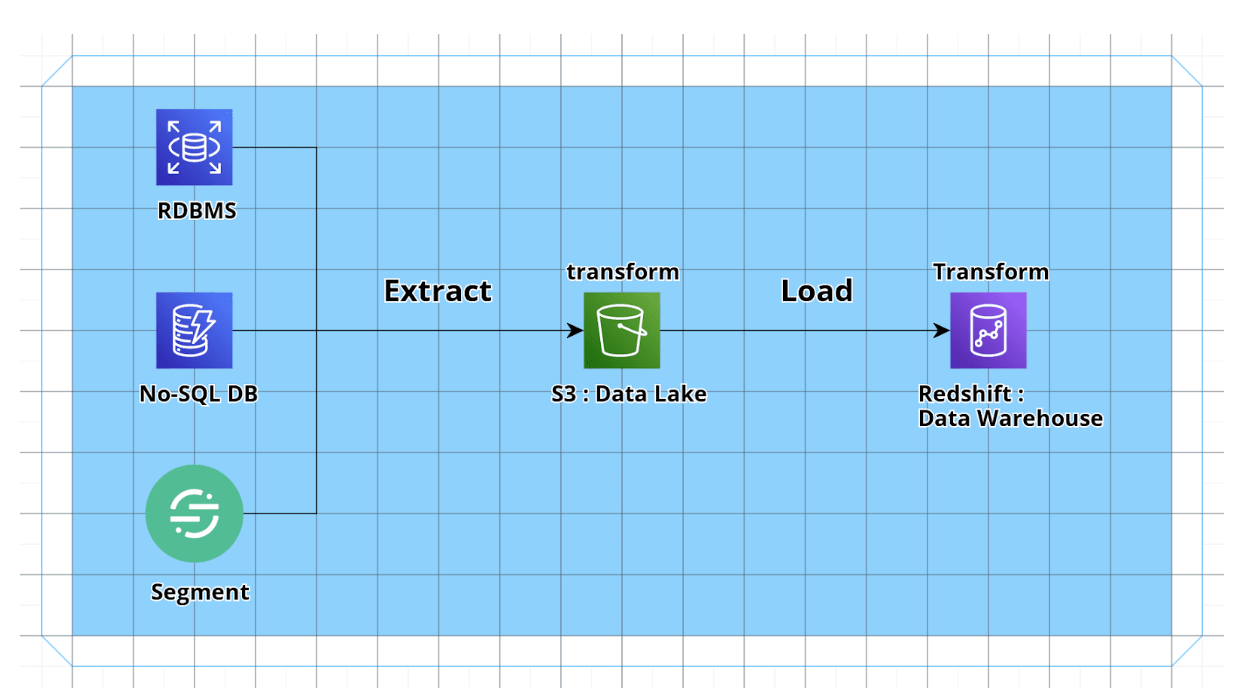
ETL과 ELT 방식의 차이점 및 ETLT 방식이 더 궁금하시다면 아래 블로그를 확인해보세요!
참고 블로그
데이터레이크 = (진리의) S3
기존에는 모든 데이터를 한 곳에 모아 관리할 data lake가 없었습니다.
메디스트림을 따라 S3를 데이터레이크로 결정하고 세그먼트 데이터, rds 데이터, no-sql db 데이터(추후 진행 예정) 등 모든 데이터를 s3에 적재하였습니다.
이후 매일 데이터를 업데이트하는 작업은 다음에 설명할 에어플로우에서 자세히 설명드리겠습니다.
데이터웨어하우스 = redshift serverless
데이터 레이크에는 데이터가 원본 형태로 저장되어 있기에 이를 바로 사용할 수는 없습니다.
이 저장된 데이터를 분석하기 편한 형태로 전처리하고 실제 쿼리문을 사용하여 분석할 수 있도록 데이터 웨어하우스가 필요합니다. 저희는 aws에서 제공하는 DW서비스인 redshift를 선택하였습니다.
redshift는 타 유사 솔루션에 비해 아래와 같은 비교우위가 있고 또한 프로덕트 대부분이 aws 제품을 사용하고 있어 호환성 측면에서도 redshift가 저희 회사 상황에 적합하였습니다.
다만 메디스트림에서는 기본적인 온프레미스 redshift를 사용(메디스트림에서 구축할 당시에는 serverless 서비스가 GA되지 않았습니다)하였지만 이번 횡전개 프로젝트에서는 redshift serverless가 비용측면에서 더 효율적이라는 계산 하에 severless 옵션을 더해서 운용하기로 하였습니다.

출처 : https://cloudbilimited.com/blog/2023/4/25/redshift-serverless
3. 워크플로 오케스트레이션 도구 =Airflow(with Glue)
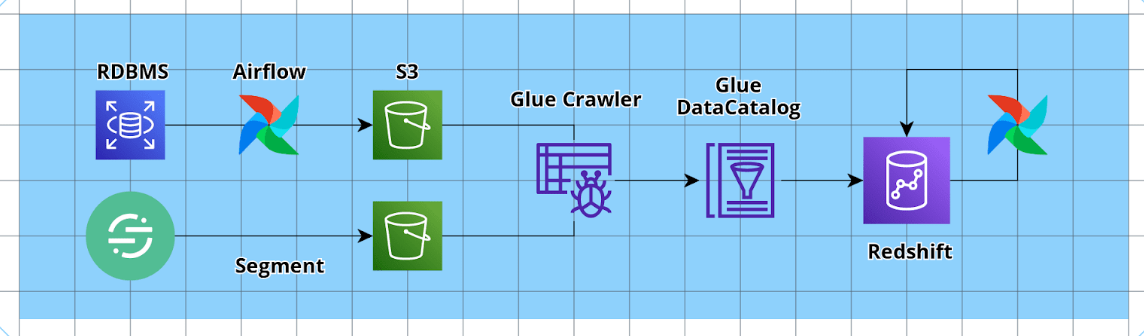
데이터 파이프라인을 관리하기 위해 Apache Airflow와 AWS Glue를 함께 도입했습니다.
에어플로우 서버 구축
우선, EC2 인스턴스에 에어플로우 서버를 설치 및 구성했습니다. ECS에 올릴까 고민하였지만 되도록 환경을 메디스트림과 비슷하게 구성하고 추후 ECS로 이전할 시 한꺼번에 하는 것이 관리측면에서 효율적이라는 devOPs 팀의 의견을 받아 간단하게 aws ec2 인스턴스에 airflow를 설치하였습니다.
파이프라인 구성
1. 첫번째 프로세스 Extract and Transform : Raw Data to S3 (데이터레이크)
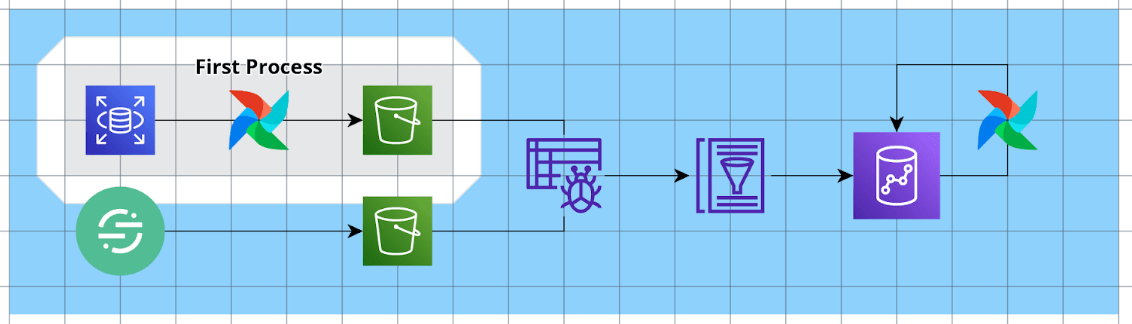
에어플로우를 사용하여 Raw 데이터를 S3 데이터레이크에 저장하는 작업입니다.
이전에는 rdb 등 데이터베이스에 bi가 직접적으로 붙어 필요할때마다 request를 날리는 방식으로 BI를 구성하였습니다. 하지만 위와 같은 방식은 데이터베이스에 부담을 줄 수 있는 리스크가 있습니다.
이를 해결하기 (1) aws rds의 읽기 전용 복제본을 생성하고 (2) airflow 내 dag 스크립트를 통해 복제본 rds에서 필요한 테이블만 parquet 형식으로 변환하여 s3에 매일 저장하고 있습니다.
위와 같은 방식으로의 전환으로 실시간의 데이터베이스 정보는 확인이 안되고 하루가 지나야 bi에 반영된다는 단점이 있지만 프로덕트 안정성 문제는 해결하였습니다.
새롭게 도입한 segment는 서비스 내에 destination에 s3를 추가하여 자동으로 유저 행동데이터가 s3에 적재되게끔 하였습니다.
2. 두번째 프로세스 Load : S3 to Redshift (AWS Glue)
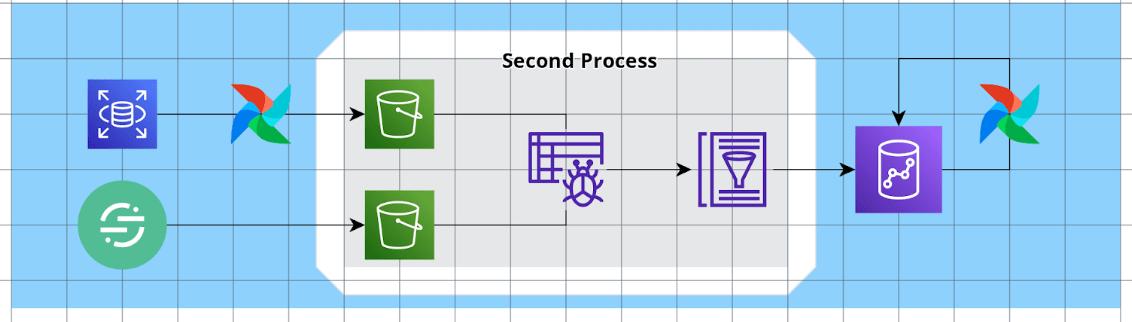
AWS에서는 Glue라는 서비스를 제공하고 있습니다. 이 서비스는 데이터 카탈로그를 관리하여 효율적으로 ETL 데이터 파이프라인을 관리할 수 있도록 하는 서비스입니다.
https://docs.aws.amazon.com/glue/latest/dg/what-is-glue.html
대부분의 프로덕트 서비스가 aws 서비스를 사용하는 환경에서 glue는 간단하고 빠르게 S3에서의 데이터를 Redshift로 “Load” 할 수 있도록 하는 도구이기에 이를 사용하지 않을 이유가 없었습니다. 이를 통해 간단히 데이터레이크에서 데이터웨어하우스로 분석 및 시각화에 필요한 데이터들을 Load 할 수 있었습니다. 방법은 아래와 같습니다.
1. aws glue 의 crawler 를 통해 data source에 있는 데이터 기반으로 glue 데이터 카탈로그 테이블을 만듭니다. 해당 크롤러가 얼마나 데이터를 자주 수집할 지는 사용자가 설정할 수 있습니다.
2. redshift에서 spectrum_schema를 생성하면 glue 데이터 카탈로그 테이블을 자유롭게 조회합니다!3. 세번째 프로세스 Transform : 통계량 생성 및 적재
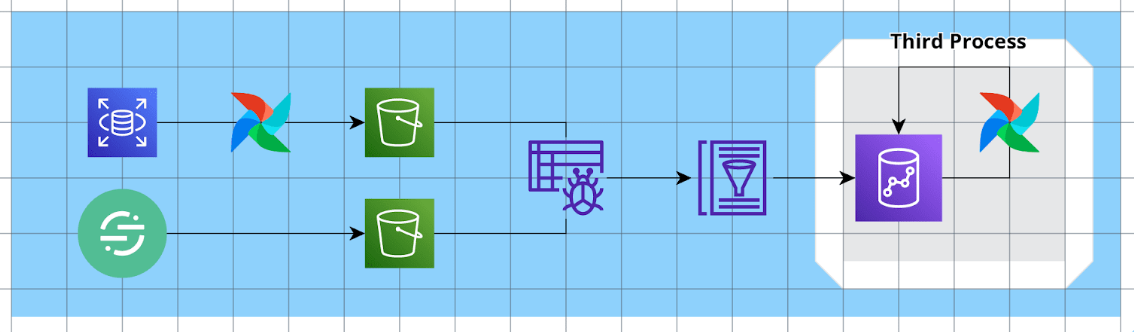
레드시프트에 저장된 로우데이터를 통해 비즈니스에 사용할 가치있는 지표들을 계산하고 적재합니다. 예를 들어 MAU 등의 Active User, Page View 등을 세그먼트 데이터로부터 계산한 후 그 통계량을 따로 저장하여 추후에는 다시 계산없이 빠르게 볼 수 있도록 합니다.
이 때 에어플로우는 이러한 워크플로 오케스트레이션에 매우 유용한 도구입니다. 예를 들어 retention 지표를 계산하기 위해서는 우선 각 일별 active user의 리스트가 우선 필요하고 해당 리스트가 적재된 테이블을 통해 retention을 계산하기 때문입니다. 때문에 각 프로세스의 순서 및 완료됨이 중요하기에 에어플로우의 dag를 통해 이러한 오케스트레이션을 관리하고 있습니다.
4. BI 대시보드 Superset 도입
마지막으로 BI(Business Inteligence) 대시보드를 강화하기 위해 Apache Superset을 도입하였습니다.
superset은 깔끔한 디자인과 쉬운 차트 생성 등의 장점이 많은 매우 도움이되는 툴이지만 아쉽게도 몇몇 단점 또한 존재하였습니다. 다행히 단점들은 저희 회사에 맞게 적절히 해소할 수 있었기에 현재 만족하는 툴로 사용하고 있습니다.
Superset 설정
ECS에 Superset 컨테이너를 띄우고 실행합니다. 이 부분에서 많은 시간이 소요되었습니다. 아직 캐싱이 제대로 붙지는 않아 추후 업그레이드할 예정입니다.
ECS에 올라간 Superset을 Redshift와 1:1로 연동하여 데이터를 시각적으로 탐색하고 분석할 수 있게 되었습니다. 또한 1:1로 연동시키다 보니 구조가 간결해진 장점이 있습니다. (모든 데이터는 레드시프트에!)
Superset 장단점
장점
- Redash에서 불가능했던 다양한 그래프와 시각화를 생성할 수 있습니다.
- 비개발자도 사용하기 쉬운 인터페이스로 그래프 및 시각화를 생성할 수 있습니다.
- SQL Lab을 통해 복잡한 쿼리도 지원합니다.
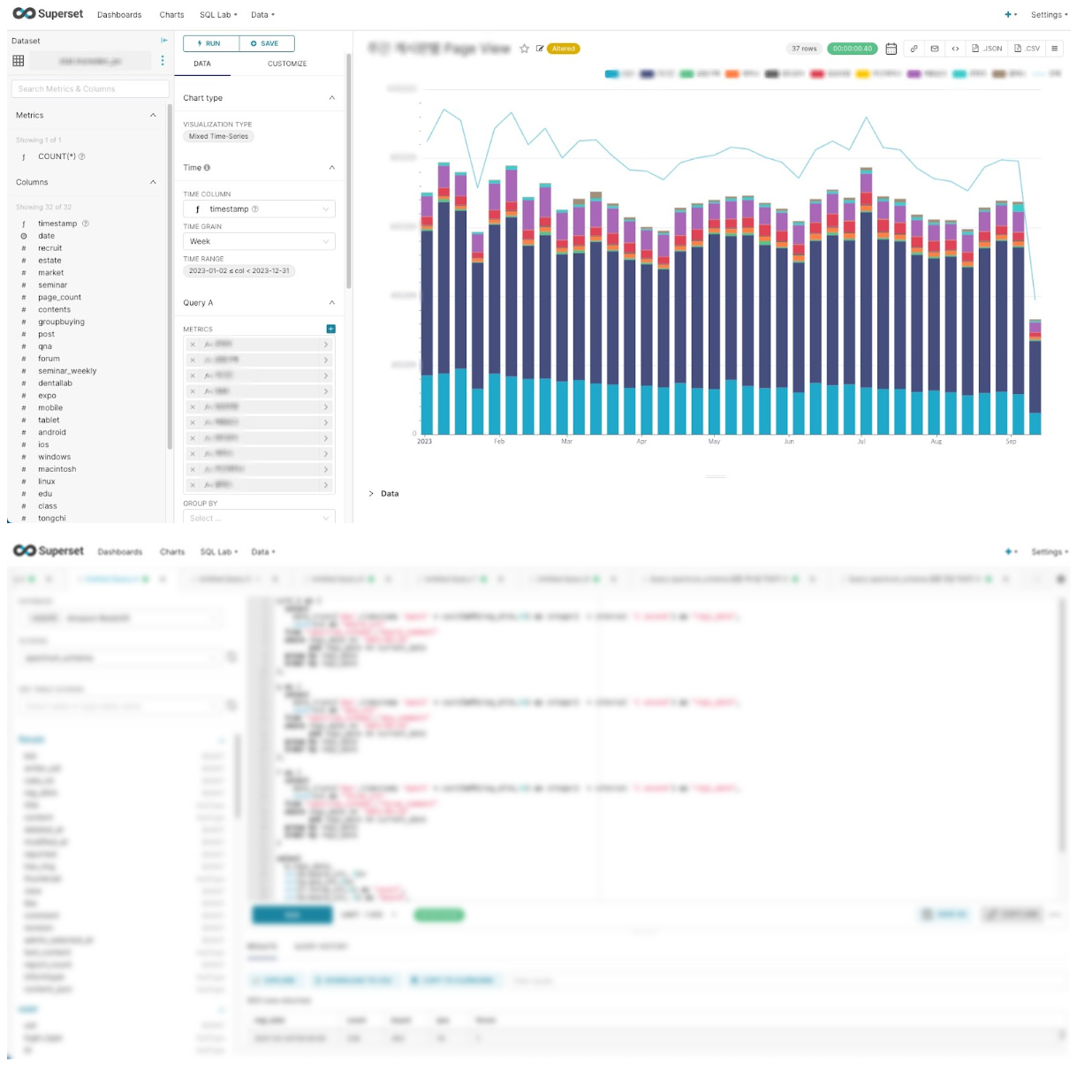
단점
-
여러 테이블을 조인하여 데이터셋을 구성해야 할 경우 개별적으로 쿼리문을 작성하여 가상 데이터셋을 설정해야 합니다.
이부분이 가장 큰 superset 사용의 가장 귀찮은 점이 아닐까 싶습니다. 아직까지는 일일히 만들고 데이터셋을 만들고 있습니다.
-
같은 데이터베이스 내에서만 조인이 가능합니다.
Redshift 단일 데이터베이스로 사용하여 해결하였습니다.
(redash 의 경우 쿼리의 결과를 다시 테이블(from query_XXXX) 처럼 사용할 수 있습니다. 이를 통해 다양한 데이터소스 간의 조인도 가능합니다. (물론그지같은sqlite 문법은 감당해야합니다) -
시계열 그래프의 경우 x 축이 무조건 date 타입의 컬럼만 지원하므로 수작업으로 컬럼을 수정해야 합니다. 직접 컬럼 추가가 가능하여, string으로 된 컬럼을 datetime or timestamp type으로 바꾸어서 해결하고 있습니다.
결론
꽤 큰 작업이었지만 다행히 먼저 대부분의 모든 것들을 이미 구축해놓은 경험이 있는 저희 데이터팀의 도움으로 빠르게 2달만에 데이터 분석환경을 구축할 수 있게 되었습니다. 저 또한 AWS 등 여러 배운 것들이 매우 많았고 앞으로 AWS 자격증에도 도전해봐야겠다고 생각했습니다. 이 포스팅을 통해 또다시 한번 저희 인티그레이션 데이터팀에 감사의 말씀을 전달합니다.
혹시나 궁금한 점이나, 관련 질문 있으시면 댓글에 남겨주세요! 환영합니다!
감사합니다!
홍찬희 데이터사이언티스트

대시보드 만드신 건 알았는데 이런 과정이 있었군요 ㅎ 재밌네요 ㅎ S3 적재시에 parquet 형식으로 저장하는 이유가 뭔가요?