장애 증상
- kubectl 명령어가 먹지 않았다
$kubectl logs <pod이름>
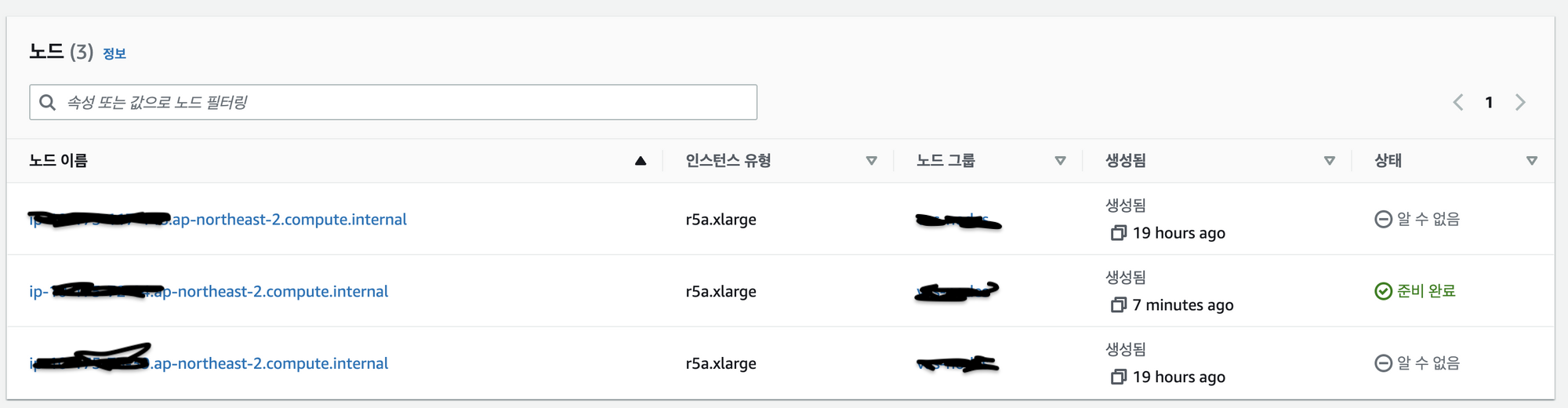
Error from server: Get "https://XX.XXX.XXX.XXX:XXXX/containerLogs/<name>/<pod이름>": net/http: TLS handshake timeout- AWS 콘솔에서 클러스터 노드를 확인해 봤는데
알 수 없음상태로 나와 노드가 죽었다는 것을 확인할 수 있었다. 자동으로 노드가 다시 생성되어도 다시 자꾸 죽었다.
원인 확인
- 특정 pod가 생성 초반에 cpu를 과다 사용하여 노드의 cpu 사용률이 100%를 찍으니 노드가 죽은 것이었다.
- 확인 방법
$ k top node
$ k top pod조치
- node 수 늘리기 : 임시조치.
- 바로 즉각적인 해결이 되었다. 하지만 비용 최적화를 위해서는 최소한의 node로 사용할 수 있는 방법을 찾아야 한다
- cpu 사용량 제한
- 한 pod가 사용할 수 있는 memeory와 cpu 제한
- 공식문서 바로가기
apiVersion: v1 kind: Pod metadata: name: frontend spec: containers: - name: app image: images.my-company.example/app:v4 resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m"apiVersion이랑 kind가 같은 레벨인데, apiVersion앞에 빈칸이 자동으로 생겨서 정렬이 안맞게 표시된다. 공식문서를 참고할 것
- Cloud Watch 모니터링 + 알람
- cluster 수준에서 cpu, memory, disk 사용율, cluster 결함을 보고있다가 특정 수준(threshold)을 넘게되면 Slack 으로 알람이 오도록
- Cloud Watch: 모니터링, 경보 발생
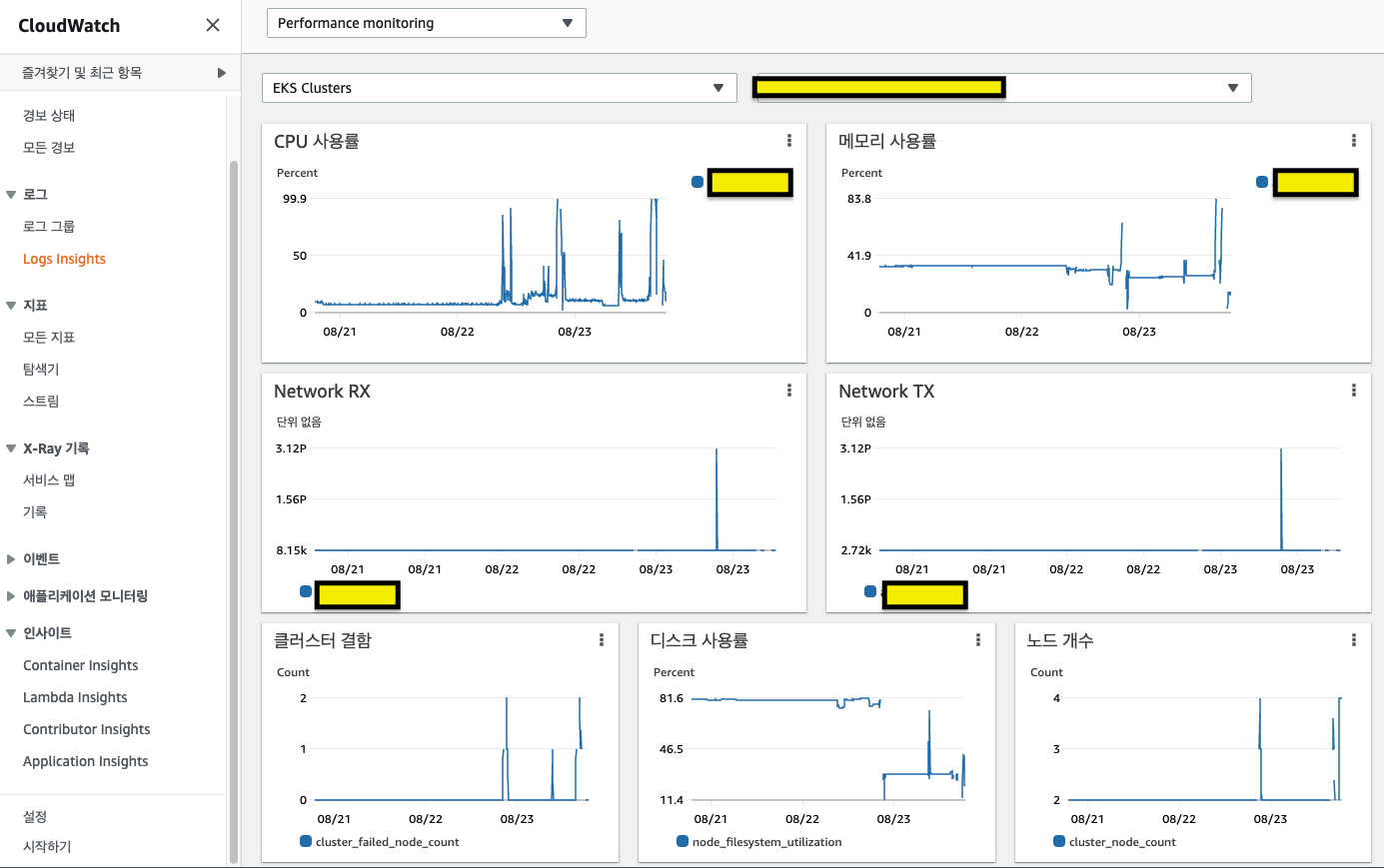
- SNS + Lambda: cloud watch에서 경보 발생시 Slack 으로 알람 보내기
- 참고자료
- 노드그룹 따로 만들기
- 비용 최적화를 위해 실시
- 특정 Pod만 특히 리소스를 많이 사용하면 스펙이 높은 노드 그룹을 만들어놓고 무거운 Pod를 올리고, 나머지 리소스가 많이 필요없는 Pod들은 스펙이 낮은 노드그룹에 띄워놓기 공식문서 바로가기
- ClusterAutoScale
- 비용이 많이 늘어날까봐 설정을 안해둔 상태지만, 장애가 일어나는 것보다 노드 늘어나고 비용 많이 나오는게 낫다고 판단하면 EKS의 ClusterAutoScale을 고려해볼 수 있다
- 공식문서 바로가기
느낀점
- 메모리/CPU 사용 과다로 노드가 다운되니 로그도 남지않고, 디버깅을 할 수도 없어 원인을 찾아내기 어려웠다.
- 결국 사수님과 클라우드 인프라 담당자님께 SOS를 요청해서 해결할 수 있었다.
- AWS로 이관한지 얼마 안되어서 모니터링/장애 감지 시스템이 미흡했는데, 모니터링 시스템과 리소스 관리의 중요성을 깨닫게 된 사건이었다.

LLM Application을 개발중인 BackEnd 개발자