👏 컴퓨터 산업에 큰 영향을 미치고 있는 알고리즘을 알아보자!
- 재귀 호출을 이용하는 N팩토리얼 구하기
- 그래프에서 최적 경로를 구하는 데이크스트라 알고리즘
- 정적분의 값을 궇나느 사다리꼴 알고리즘
- 연립 방정식의 해를 구하는 가우스 소거법
- 구글 같은 포털에서 사용하는 검색 알고리즘
웹 검색 / 페이지 링크로 나뉨!- 데이터베이스의 일관성을 위한 알고리즘
- 데이터 전송에 따른 오류 정정 알고리즘
- 암호의 혁명, 개인키/공개키 알고리즘
- 데이터 압축 알고리즘
📍 1. 웹 검색 알고리즘
1) 매칭 : 검색에 부합되는 페이지를 찾는 작업
매칭을 수행하는 기법
- 인덱스
- 구문 쿼리
- 적합성
- 메타워드
2) 랭킹 : 찾은 페이지를 대상으로 순서를 정하는 작업
랭킹을 수행하는 기법
- 하이퍼링크 알고리즘
- 권위 알고리즘
- 무작위 서퍼 알고리즘
** 구글이나 네이버 모두 매칭과 랭킹에 의해 사용자가 원하는 검색을 수행함!!
📍 1-1) 매칭 알고리즘
인덱스
웹 검색 엔진이 최초로 수행하는 작업은 매칭이다.
검색 엔진이 사용하는 인덱스 알고리즘
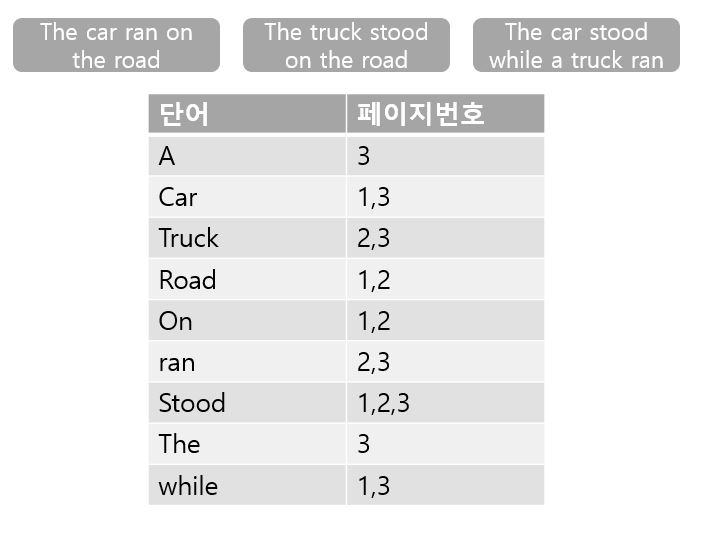
ex. 3개의 문서에 있는 단어들을 뽑아내어 알파벳순으로 배치.
각 단어가 어느 페이지에 있는지 정리함!
- 인덱스 기법의 한계!
특정 단어가 포함된 페이지 검색은 유리하나, 'car ran'과 같이 특정 문장을 포함하는 문서 검색에는 사용 할 수 없음 >> 구문 쿼리 기법 개발
구문 쿼리
여러 개의 단어가 나오는 경우를 찾는 것 ('truck ran')

각 단어를 알파벳 순으로 정리 > 각 단어가 있는 페이지의 번호와 위치를 정리
- 구문 쿼리 기법의 한계
특정 구문이 포함된 페이지 검색이 가능. 그러나, 검색된 페이지 중에서 어느 것이 사용자 요구에 더 적합한지는 판단할 수 없음!! > 적합성 개발
적합성
웹에서 제공하고자 하는 문서 중에 어느 것이 고객이 원하는 것에 가까운 것인지를 결정하는 것
ex. malaria cause 라고 검색
1,2 두개의 페이지가 검색됐는데, 각 페이지에서 malaria와 cause의 단어 간격이 얼마나 되는지 검사 > 두 단어 사이의 간격이 가까울수록 적합하다 판단!
- 적합성 기법의 한계
사용자가 원하는 페이지를 정확하게 선택하지는 못함 > 메타워드 기법 발명
메타워드
특정 메타워드로 마크하여 활용
ex.제목에 truck 이 있는 문서를 검색하고자 하는 경우
1번 문서 2번 문서
my car my truck
the car ran on the road the truck stood on the road
메타워드로 작성
1번 문서 2번 문서
<titlestart>my car<titleend> <titlestart>my truck<titleend>
<bodystart>the car ran on the road<bodystart> <bodystart>the truck stood on the road<bodyend>
titlestart | 1-1,2-1
titleend | 1-4,2-4
truck | 2-3, 2-7, 3-11(3번 문서..)
타이틀이 1-1 ~ 1-4 / 2-1 ~ 2-4 이니까 그 사이에 truck 페이지 번호가 있으면 됨! truck 은 2-3 (제목)에 있음 (2-7은 본문)

back-end 개발자