5/3 수
읽어보기
클라우드 서비스 기본 상식

참고
https://wnsgml972.github.io/network/2018/08/14/network_cloud-computing/
AOP : 공통관심과 보조관심
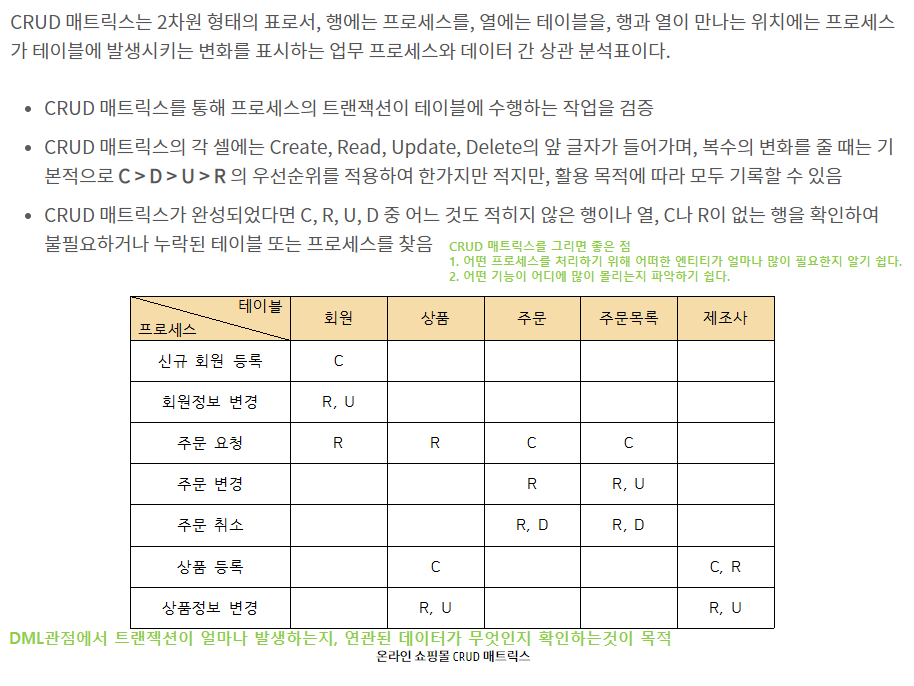
CRUD 매트릭스
기타
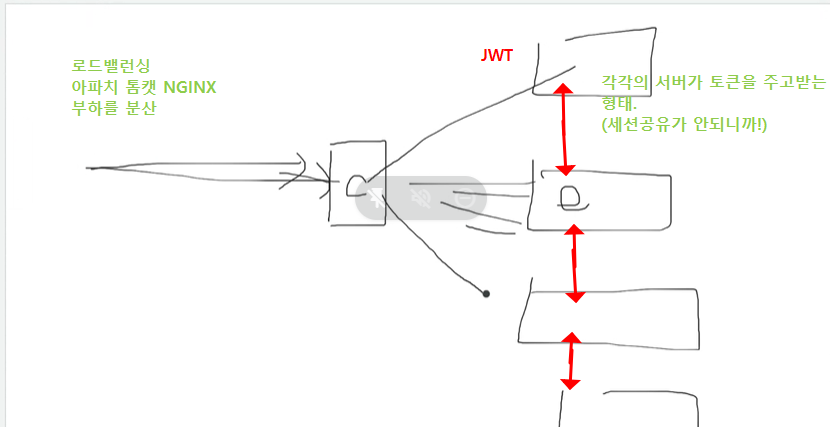
로드벨런싱
수업 캡쳐
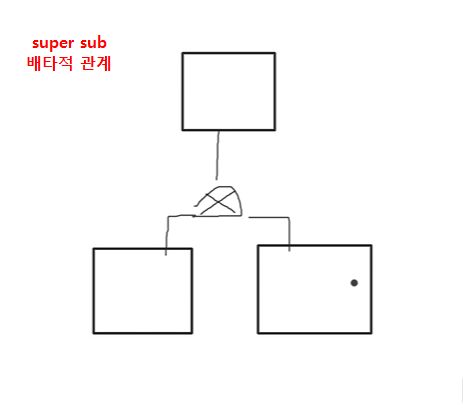
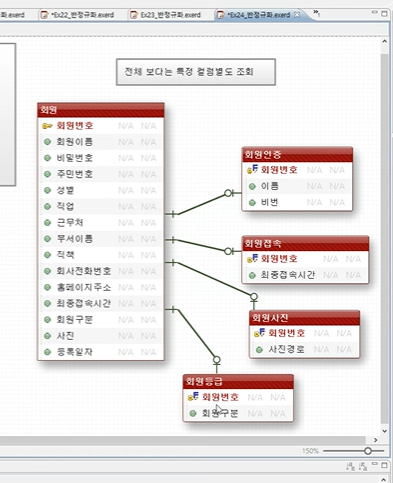
반정규화
반정규화 하는 CASE
반정규화 기법
[컬럼에 의한 반정규화]
1. 중복 컬럼 추가 ...
2. 파생 컬럼 추가 ...
3. 이력테이블 추가 ... 이슈
4. PK분리 컬럼 추가
5. 데이터 복구를 위한 컬럼 추가 이슈
테이블 반정규화
테이블 반정규화
1. 관계병합 , (슈퍼 타입, 서브타입) 병합
2. 테이블 분할 (수평분할 , 수직분할)
수평분할 : 고객묶음1, 2, 3으로 테이블 나눠서 관리
수직분할 :
3. 테이블 추가 >> 중복 테이블 추가 , 통계테이블추가 , 이력테이블추가 , 부분테이블 추가
코드성 테이블
EX) 남 01, 여 02
코드 테이블은 추가될 내용이나 변경사항이 있으면 만들면 됨.
코드테이블을 쓸데없이 만들면 JOIN이 많아지므로 필요시에만 만들기
5/4 목
수평분할
테이블 분할 관점
1. 데이터 모델링 수행 -> 데이터베이스 용량 산정 -> 대량 데이터 처리(트랜잭션) 패턴 분석
-> 트랜잭션이 컬럼 단위 집중 (수직 분할) ..... 로우 단위 집중 (수평분할)
테이블 수평 분할
데이블이 대량의 데이터를 가질 것 파악(예상) 경우 : partitioning
1. 범위로 분할 (고객 1~10000 , 10001~20000 , 20001~) >> Range
--범위 (range) : [숫자] , [날짜] , [문자]
live sql에서 실습 가능
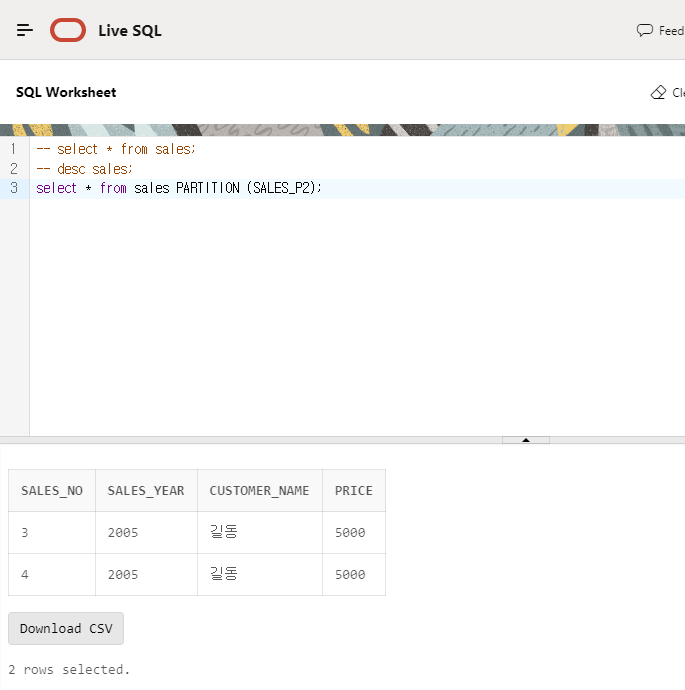
실습 쿼리
--파티션 나누는 키가 숫자 타입 create table sales( sales_no number, sales_year number, customer_name varchar2(20), price number ) PARTITION BY range (sales_no) ( PARTITION SALES_P1 VALUES LESS THAN (3), PARTITION SALES_P2 VALUES LESS THAN (5), PARTITION SALES_P3 VALUES LESS THAN (MAXVALUE) ); insert into sales values(1, 2005 , '길동', 5000); insert into sales values(2, 2005 , '길동', 5000); insert into sales values(3, 2005 , '길동', 5000); insert into sales values(4, 2005 , '길동', 5000); insert into sales values(5, 2005 , '길동', 5000); select * from sales; --전체 조회 select * from sales PARTITION (SALES_P1); 1, 2005 , '길동', 5000 2, 2005 , '길동', 5000

보초딩코라 틀린 내용 있을 수도 있습니다. 댓글 지적 환영