이 논문은 Knowledge Distillation을 처음으로 Self-supervised 기법을 적용시킨 논문으로 알고 있다. 이를 통해, 다른 다양한 regularization methods(restricting function space, injecting randomness during training, augmenting data, 등)를 앞서고 SOTA를 찍었다고 한다.
읽어보도록 하자.
ABSTRACT
딥러닝에서의 일반화 능력은 매우 다양한 범주의 정규화 방법들로부터 적용되어 향상되어 왔다. 이 논문에서는 아주 간단하고 효과적인 정규화 방법론인 progressive self-knowledge distillation (PS-KD)에 대해 소개한다.
이 방법은 점진적으로 모델을 학습하며 스스로(self)의 knowledge를 통해 hard targets(one-hot vectors)를 훈련하는 동안 soft하게 만들어준다.
뭔 말이냐면 보통 label 값은 원핫 벡터로 [1, 0, 0, 0, 0] 이런 식이다(hard targets). 그런데 이걸 좀 부드럽게 만들어 준다고 해서(soft), [0.8, 0.05, 0.05, 0.05, 0.05] 이런식으로 만들어 주는 것이 soft하게 만들었다고 한다. 근데 이걸 PS-KD는 knowledge distillation 방법을 사용하여 만들어주는데, 다른 KD들과는 다르게 student와 teacher 모두 자기 자신이다.
즉, student가 teacher자신이 되도록 knowledge distillation을 진행하는 framework로 이해할 수 있다.
INTRODUCTION
딥러닝 모델들이 많이 발전하고 있고, 성능또한 점점 좋아지고 있다. 그러나 네트워크가 깊어질수록 더 많은 모델 파라미터를 필요로 하고, 이것은 모델이 과적합되도록 할 수 있다. 즉, 심층신경망의 깊이가 깊을수록 일반적으로 overconfident한 예측들을 만들고, 심지어 틀린 예측에 대해서도 높은 confidence값을 가진다. 이것은 예측값들이 매우 miscalibrated 되었기 때문이다.
심층신경망의 효율적인 훈련과 성능 일반화를 향상시키기 위해서, 많은 정규화 방법들이 제시되어 왔다. 그것들 중에서 널리 이용 되는 것들이 있는데 : the function space를 제한 하기 위한 그리고 weight decay, 훈련하는 동안 randomness를 주입시키는 dropout, 매 layer마다 input들을 normalize하여 훈련 속도를 가속화 하는 batchnormalization 등이 있다.
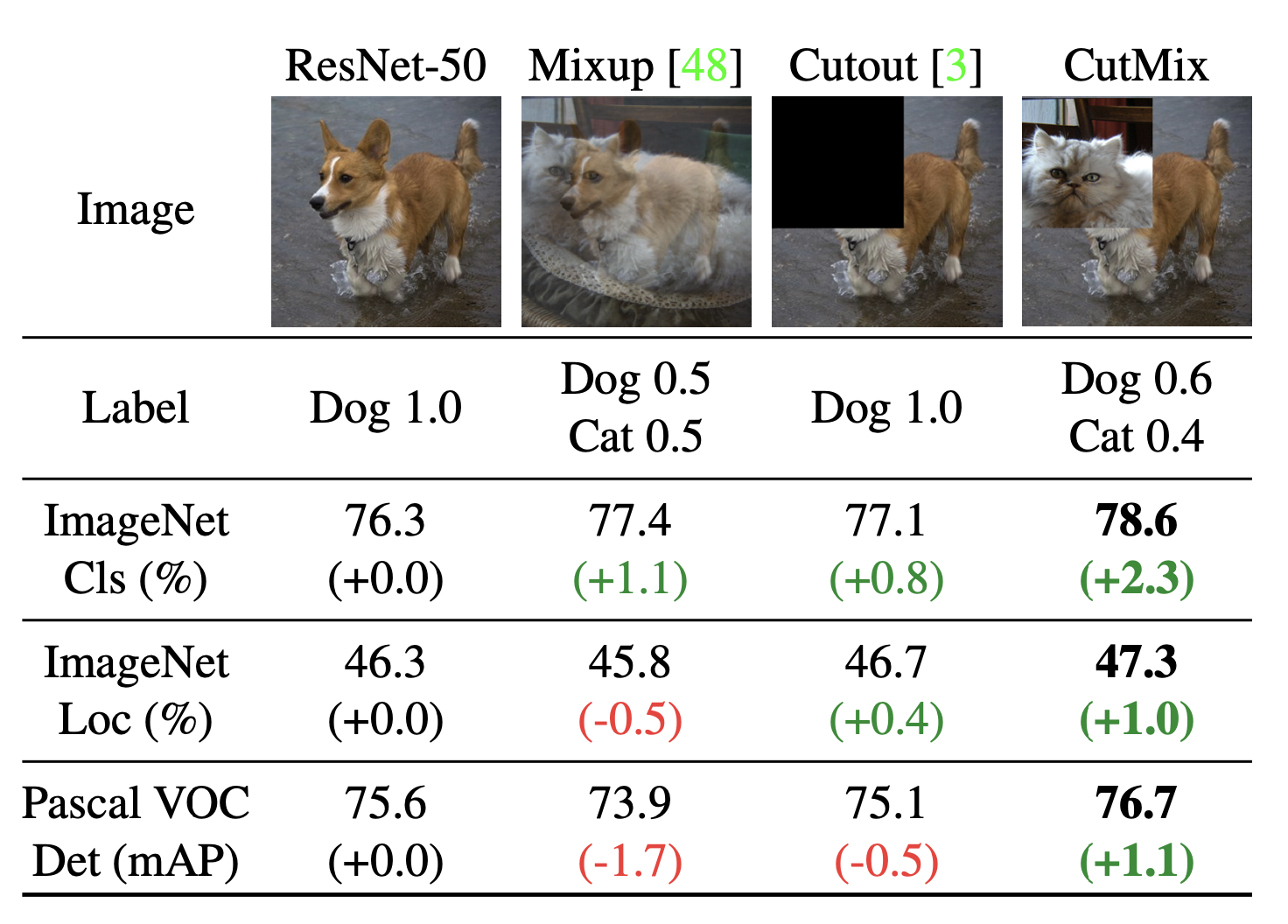
또한 특정 task를 위해 설계된 여러 방법들이 있는데, 예를들어 Cutout, Mixup, AugMix, CutMix와 같은 Computer Vision분야에서 데이터를 증강(Data augmentation)시키는 발전된 방법들이 있다. 이러한 데이터 증강 기법들은 분류 정확도를 올려주고 또한 모델의 불확실성(uncertainty)을 줄이고 강건함(robustness)을 향상시켜준다.
또 다른 효과적인 정규화 방법에는 Label Smoothing(LS)나 Label perturbation을 이용해 one-hot coded vectors(hard targets)의 형태인 target들을 조절하는 방법들이 있다.
Targets값들을 조절(adjusting targets)하는 방법들 사이에서, LS는 매우 많은 분야에서 사용됐고 이미지 분류와 기계 번역 분야에서 confidence estimates의 품질뿐만 아니라 일반화 성능 향상을 보여주었다.
LS는 hard target을 soften하는데, 작은 양의 확률 질량을 target이 아닌(non-target) classes에 할당해 주는 방식을 이용한다.(다시말해, [1, 0, 0, 0, 0] 같은 hard targets를 [0.8, 0.05, 0.05, 0.05] 같이 만들어 준다는 의미) 그러나 경험적으로 이것은 현재 발전된 정규화 방법들을 보충해줄 수 없는 방법이다(무슨 말이냐면, 함께 이용했을 때 오히려 성능이 하락한다. 즉 보충할 수 없는 정규화 방법이다).
예를들어, 만약 우리가 LS와 CutMix를 이미지 분류에서 같이 사용했을 때, 성능과 confidence estimation모두 상당히 감소한 것을 알 수 있다.
LS를 통해 한가지 의문을 파악할 수 있다:
hard targets를 soften하여 더 정보가 많은(informative) labels를 얻을 수 있는 더욱 효과적인 전략이 있을까? 하는 질문이다.
이 질문에 저자들은 간단한 정규화 방법인 progressive self-knowledge distillation (PS-KD)에 대해 소개한다. PS-KD는 자기자신의 knowledge를 자기자신이 학습하는 모델이다. 이것의 의미는 자기 자신이 선생이 되고, 학생이 되어 점진적으로 자기 자신의 knowledge(predicted values)를 이용해 hard targets를 softening하고, 이를 통해 훈련이 좀 더 informative하게 만든다.
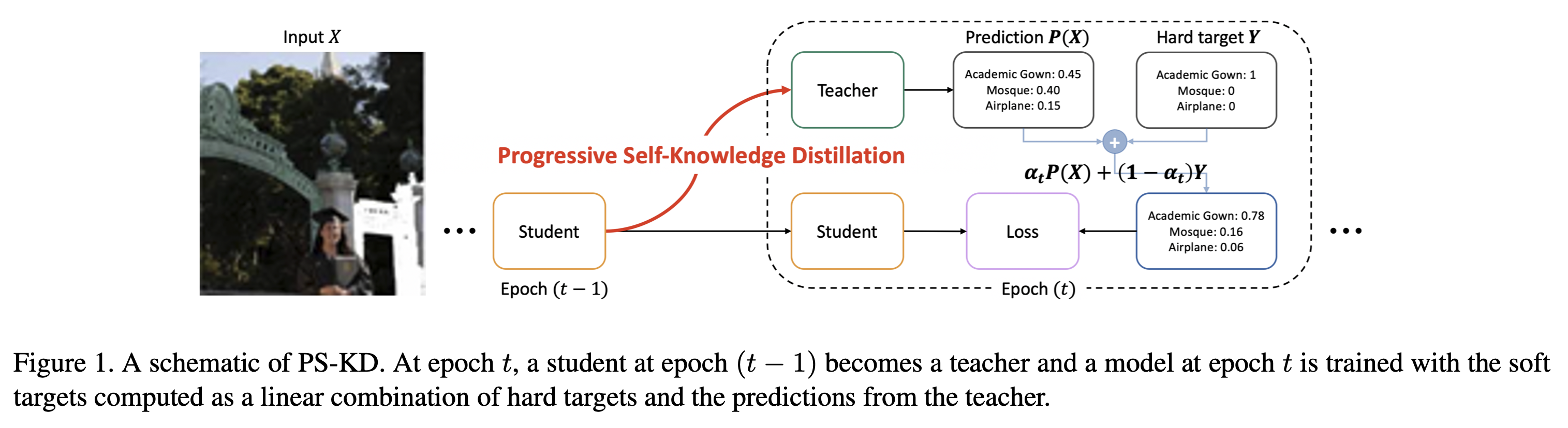
어떤 방법으로 이렇게 학습 하는지 알아보자.
Self-Knowledge Distillation
Knowledge Distillation as Softening Targets
KD는 하나의 모델(teacher)에서 다른 모델(student)로 knowledge를 전달하는 방법이다.
일반적으로 큰 모델에서 작은 모델로 전달한다. 이때 학생 모델은 one-hot label대신에 선생으로 부터 온 예측 확률 분포인 좀 더 informative한 sources로 학습한다. 따라서 학생모델은 훨씬 작은 모델임에도 불구하고, 선생 모델과 비교했을 때, 성능적으로 비슷한 값을 얻으며 심지어 same capacity의 경우에는 선생보다 좋은 성능이 나오는 경우도 있다.

위 식은 Hinton이 제시한 temperature scaling을 사용하여 좀 더 나은 distillation을 하기 위함입니다.

는 temperature 매개변수이다. 이렇게 스케일링 된 softmax output은
선생 :
학생 :
으로 학생은 를 통해 학습한다.
보면 알 수 있듯이, hard target과 Teacher로 부터 나오는 logits값들을 함께 사용하면서 라는 하이퍼파라미터를 이용해 학습이 원활하게 이뤄지도록 하고 있다.
여기서 보면 그냥 단순하게 학습하는 것이 아니라, 와 term을 가지고 학습에 도움을 주고 있다. 뒤에 자세히 설명이 나온다.

를 cross-entropy loss라고 하였을 때, 는 하이퍼 파라미터이다. 여기서 위 은 에 나오는 가 1인 경우이다. 식을 살짝 변형한 것 처럼 보이지만, 각 label에 대해서 Student의 로짓값의 Cross Entropy Loss를 구한 식이다.
Distilling Knowledge from the Past Predictions
본 논문은 새로운 형태의 KD를 제안한다. (PS-KD)
PS-KD는 일반화 capability를 향상시키기 자기 자신을 증류 한다. 다른말로, 학생모델이 선생모델 그 자체이며 과거의 예측값을 사용하여 더 많은 정보가 담긴 supervision들을 훈련하는 동안 얻는다.
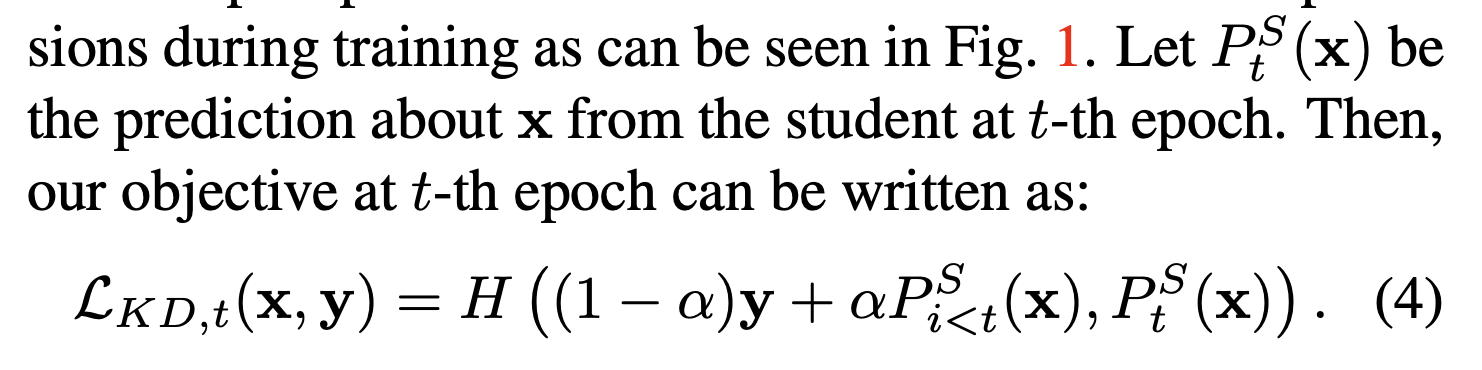
위 식에서 는 에 대한 번째 epoch의 예측이다. 그러므로 PS-KD의 목적함수의 식은 위와 같은데, 선생의 지식이 아무런 loss도 발생시키지 못한다면 이는 쓸모 없는 값일 것이다.
일반적인 KD와의 가장 큰 차이점은 선생이 정적인 모델이 아니라 역동적으로 훈련이 진행되는 동안 발전해 나간다는 점이다. 모든 과거 모델들은 선생모델이며, 저자들은 번째 epoch에 해당하는 선생을 가장 가치있는 정보를 줄 수 있다고 하여 이를 사용하였다. 더 정확히 말하자면, 훈련의 번째 epoch에서 입력 에 대한 target은 으로 softend된다.
이것은 경험적으로 과거 모델을 teacher로써 모델을 효과적으로 정규화 하는 접근법으로 볼 수 있다. 한가지 고려해야할 점은 값인데, 이는 얼만큼의 knowledge를 선생으로부터 받을 것인지에 대한 하이퍼파라미터이다. 전통적인 KD에서는 변하지 않는 값을 사용했다면, PS-KD에서는 학습 초기단계에서는 선생이 제 역할을 제대로 할 수 없을 것이라고 고려하고, 를 점진적으로 늘려가며 학습을 진행한다.
여기서 T는 전체 훈련 epoch을 의미하고 는 의 마지막 epoch의 값이다. 이러한 하이퍼파라미터들을 통해 놀랍게도 과거 예측들을 통해 일반화 성능을 많이 올렸다. 정리하자면 아래 식과 같다.
이론적인 보충설명을 들어가기 전에, Cross Entropy Loss의 logit값에 대한 Gradient값을 구하는 방법에 대해 수기로 정리해보았다.

Theoretical support

GT일때의 KD 값과, GT가 아닐때의 KD값을 나타내는 것이 위 공식들이다.
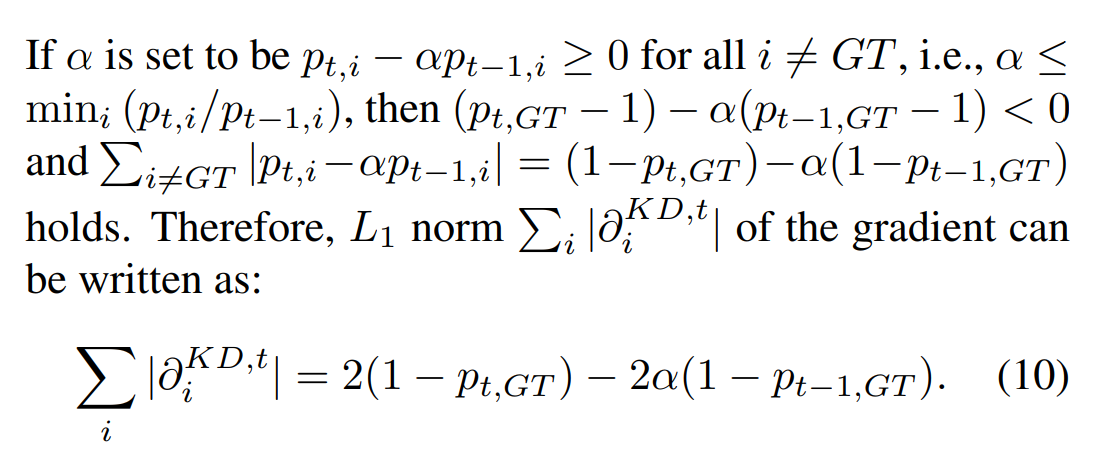
만약에 알파를 모든 에 대해 를 만족하게 설정해 주면 다음을 만족한다. -> GT아닐때, 이 때, 모든 그래디언트 값들이 양수라고 한다면, GT에 대해서는 음수일 것이다(내 생각, 찾아보기 필수 !).
근데 이게왜 가 됨 ?
아주 간단하다. 인데 만약에 GT를 뺀 나머지 값들을 다 더하면?
따라서 = (틀릴수도 있다. 혹시 틀렸으면 아시는 분은 댓글 부탁드립니다.)
그러고나서 Gradient의 는 10번 식과 같이 쓸 수 있다.

본 논문에서는 KD의 Gradient와 일반형태의 Gradient에 대해 비교를 진행한다. 이 식은 PS-KD의 Gradient rescaling factor를 유도하는 식이다.
여기서 나오는 와 10번 식을 이용해서 11번과 같은 식을 만들어 낼 수 있다. 여기서 는 틀릴 확률에 대해 나타낸다.(? 내 생각에는 기 때문에 결국 모든 GT가 아닌 값들에 대한 확률을 더한 값을 얘기한다. 즉 이것은 예측이 틀렸을 때를 의미한다.) 일반화 loss 없이 보통 모든 에 대해서 이고, 로 추정한다. 왜냐면 는 보다 나은 예측을 하기 때문이다. 따라서 는 항상 성립한다.
그러면 이게 어떤 의미를 가지고 있는지 알아보자.
큰 가 의미하는 것은 샘플들에 대한 예측들이 학습을 진행하는 동안 매우 향상된다는 것이다(easy-to-learn). 반대로, hard-to-learn 샘플들의 경우 이 값이 작다. 결과적으로 hard-to-learn 샘플들에 대한 Gradient rescaling factors은 easy-to-learn 샘플들 보다 크고 이것은 PS-KD가 hard-to-learn 샘플들에 훈련동안 더 큰 가중치를 준다는 의미이다. 이는 경험적으로 다음 Fig에서 확인할 수 있다.
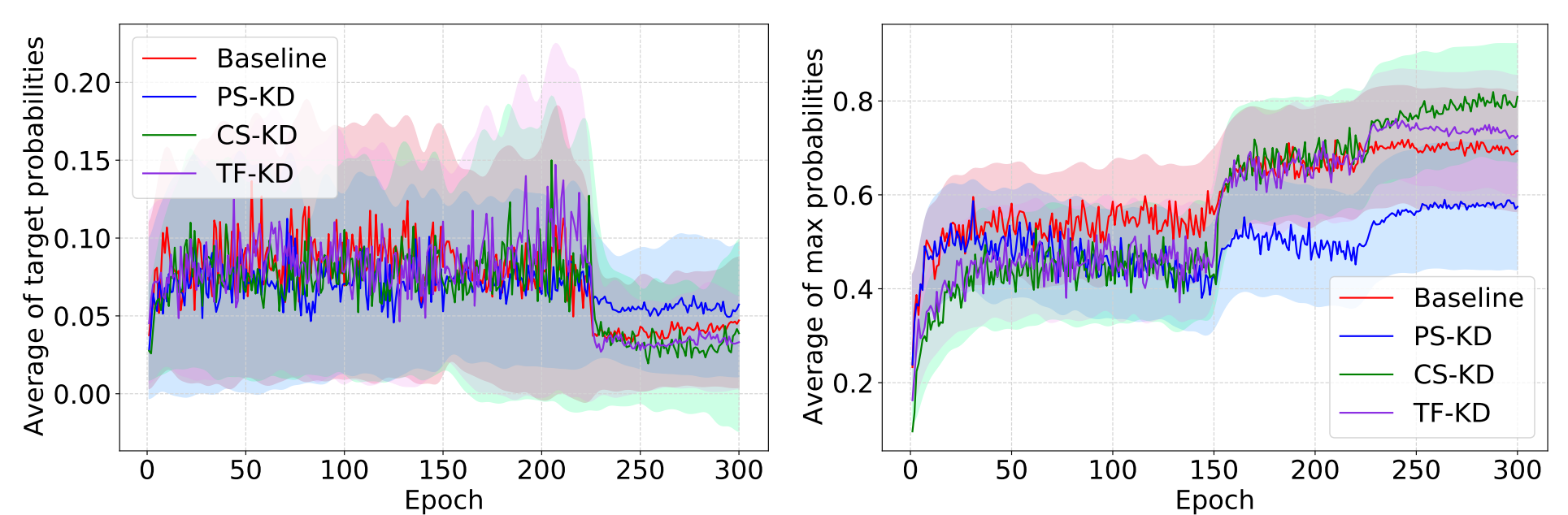
위 그림을 보면, PS-KD 이외의 다른 방법들은 올바르지 못한 예측을 했을 때 PS-KD보다 더 overconfidnet한 값을 가지고 이는 PS-KD가 gradient rescaling 관점에서 볼 때 hard 샘플들에 집중하고 있다는 것이다.
(a)의 경우 GT에서의 평균 target probabilities를 epochs에 따라 나타낸 것이며, (b)의 경우 100개의 hard-to-learn 샘플들의 maximum probabilities를 나타낸다. (CIFAR-100에서 300 epoch을 도는 동안 맞춘 횟수가 50번 미만인 샘플들). 이 결과를 봤을 때, PS-KD는 어려운 샘플들로부터 더 많은 가중치를 주는 것을 알 수 있다.
이러한 hard example mining efeects를 기대하기 위해서, 는 모든 샘플들에 대해 위 조건을 만족해야 합니다. 그리하여 는 충분히 훈련 과정에서 작은 값으로 세팅됐습니다. 훈련하는 동안, 의 차이는 모든 샘플들에 대해 작아졌습니다. 따라서 는 점진적으로 효과를 유지하기 위해 커져야 합니다.
