
Lets Git It <<< 서비스 이용하기
- 기획
- 초기 세팅 단계(백)
- 서비스 로직 ✅
- 배포 과정
- 회고 및 앞으로의 운영
드디어 시작 되었다.
14개의 지표를 가져와 그것들을 분석하고 수치화하여 DB에 꽂아 넣는 것이 즐거웠다.
내가 구현한 부분은
총 2부분으로 rank와 schedule이다.
아직 보완해야 할 점은 많고 갈 길은 멀지만 하나 하나 기억에 남는 로직을 소개해보려고 한다.
메인 로직 구현
기간 : 2023년 1월 30일 ~ 2023년 2월 10일
우선 메인 로직을 구현하기 앞서 순서를 정해보았다.
-
내가 구현해야 할 API 정리
-
GITHUB API 정리
-
로직 구현 스타트
📋 내가 구현해야 할 API 정리
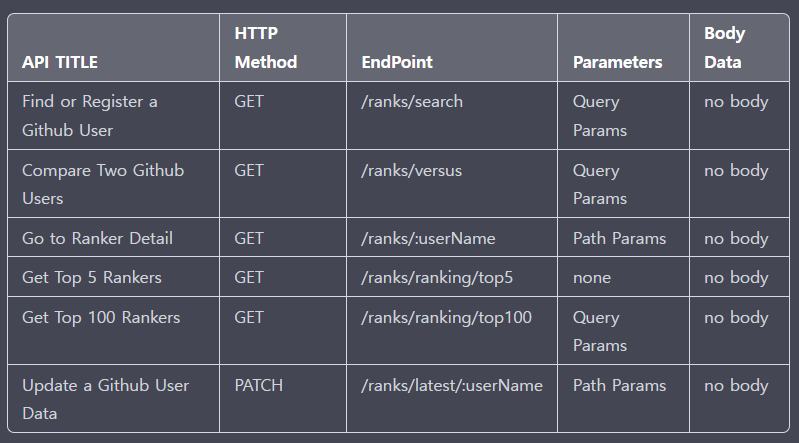
이렇게 총 6가지가 있다.
대부분 Github API를 백에서 접근해서 데이터를 긁어와 DB에 저장하고 그것을 서비스에 뿌려주는 로직이기에 GET이외에는 크게 쓰일 수 있는 HTTP Method가 없었다.
PATCH의 경우 고민을 상당히 했던 것이 유저의 정보를 업데이트 하는 것이지만 실질적으로는 Body 값이 필요가 없기 때문에 PATCH로 두는 것이 옳은 선택인가에 대해서 고민을 했었는데 간혹 Body가 없는 Patch가 있다는 공식 문서의 설명을 보고 진행하였다.
📋 Github API 정리
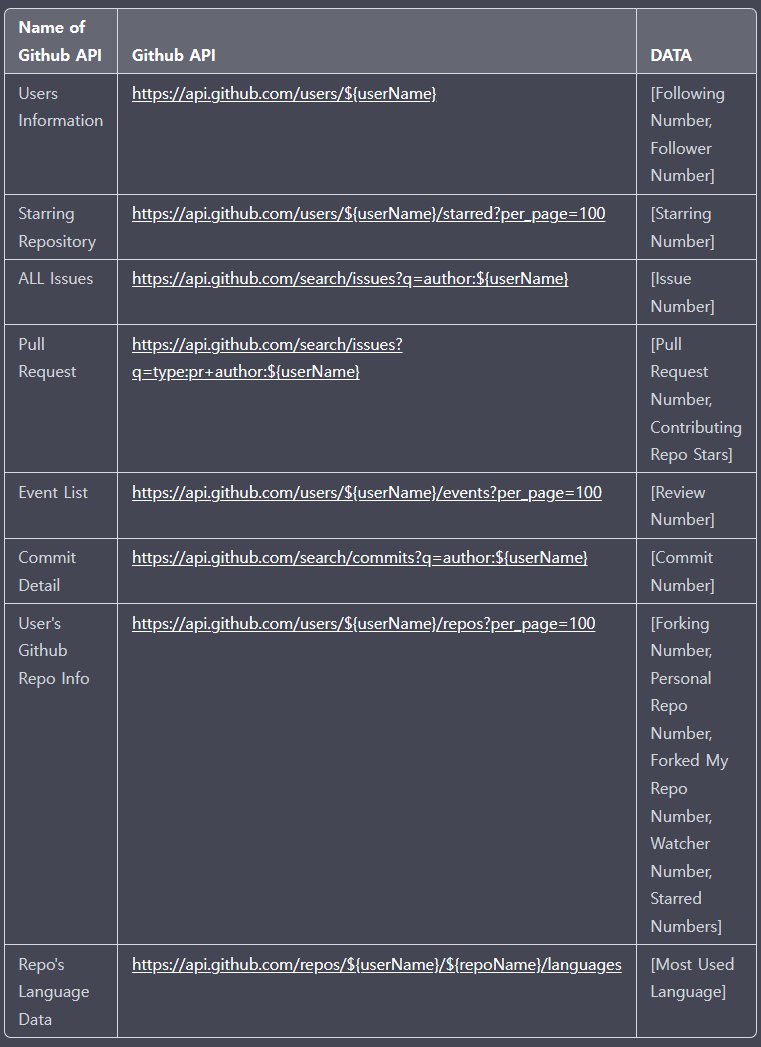
우선 간단하게 내가 쓴 외부 API들을 모아놓았다.
정리해보면 총 8개의 Github API를 쓰며, 유저마다 다르겠지만 평균 20~30번 요청한다.
그리고 Github API에는 다음과 같은 제약이 있어 서비스 로직을 중간에 바꾸게 되었는데 그건 서비스 로직 설명란에서 자세하게 설명하겠다.
✏️ Github API 제한 사항
-
Personal Access Token이 있을 시, 1시간에 최대 5000번 요청 가능
-
Personal Access Token이 있을 시, Search 관련 API의 경우 최대 분당 30번 요청 가능
=> 2번 조건 때문에 새로운 도전을 하게되었다...자세한 설명은 서비스 로직에서.
✏️ 스폰서 수 구하기...
사실 저기 모아놓은 API에서 하나 빠진 것이 있는데, 그게 바로 스폰서 수 구하기이다
스폰서의 개념이 다소 생소할 수 있는데 쉽게 말해 유투버 스트리머가 있으면 구독자라고 보면 된다.
Github에는 자체적으로 스폰서 수를 제공하는 api가 없어서 찾아보다 어떤 한 유저가 만든 api를 사용하게 되었다.
하지만...로직을 완성한 후 문제점을 찾았고..결국 저걸 버리고 아예 내가 새로 하나 만들었다.
크...이 부분에서 굉장한 희열을 느꼈는데 서비스 로직 설명란에서 설명하겠다.
📋 하이라이트 모음
✏️ Controller
사실 컨트롤러 부분에서는 하이라이트라고 할 만한 부분은 없지만...NestJS에서 기억하고 싶은 부분은 하나 있다.
어떻게 보면 가장 기초적인 것일 수도 있는데 그럼에도 불구하고 기록은 남기고 싶다.
바로!! Get 요청이다
@Controller('/ranks')
export class RankController {
constructor(private rankService: RankService) {}
@Get('/search')
async findRanker(
@Query('userName') userName: string,
): Promise<SearchOutput[]> {
return await this.rankService.findRanker(userName);
}
@Get('/versus')
async compareRanker(@Query('userName') userName: string[]) {
const firstUser = await this.rankService.checkRanker(userName[0]);
const secondUser = await this.rankService.checkRanker(userName[1]);
return { firstUser, secondUser };
}
@Get('/:userName')
async getRankerDetail(@Param('userName') userName: string): Promise<{
rankerDetail: RankerProfileOutput;
maxValues: MaxValuesOutput;
avgValues: AvgValuesOutput;
}> {
return await this.rankService.checkRanker(userName);
}저 위에 사용된 Get 요청들을 모아보자
- GET /ranks/search
- GET /ranks/versus
- GET /ranks/:userName
NestJS에서 한 가지 명심해야 할 점이, GET 요청에서 Path Parameter을 쓸 때 엔드 포인트의 앞 부분이 비슷할 경우 Path Parameter를 가지는 엔드포인트를 가장 밑에 써야 한다.
이유는 간단하다. 만약 엔드포인트 3번이 1번의 위치로 이동 후 1번과 2번의 API를 요청할 경우, search와 versus를 NestJS가 :userName으로 인식하여 3번 API를 실행하게 된다.
생각해보면 당연할 수도 있겠지만 사용하기 전까지는 모르는 것이니 기억하고 넘어가자.
✏️ Service
서비스 부분에서 하이라이트는 크게 4가지가 있다.
우선 서비스 로직은 길다보니 여기에 다 입력할 수는 없고 대부분 말로 간략하게 설명할 것이며, 로직은 깃허브 레포에서 찾아 볼 수 있습니다.
💥 Promise.all 활용으로 로직 시간 단축
처음 14개의 지표를 가져오는 과정에서 단순한 async/await 함수로만 처리를 하여 로직을 구현하였다. 그렇다보니 어느정도 유명한 인물을 랭킹 등록하려다 보니 다음과 같이 오랜 시간이 걸린다.

이 지표는 각 지표마다 console.time / console.timeEnd 메서드를 사용해서 검사해 본 수치로 정확하다고 할 수는 없지만 총량에 어느정도 기여한다고 볼 수 있다.
살펴보면 유저 스타수를 가져오는 데 2초, 유저 레포의 스타 관련 함수 약 7초, 그리고 for 문(가장 많이 사용한 언어)을 보면 34.583초가 걸린다고 볼 수 있다.
차마 서비스를 런칭하기에는 적절한 선택은 아닌 것 같다.
여기서 For문이 오래걸리는 이유는 30초가 넘는 시간이 걸리는 이유는 다음과 같다.
const scoreBasis = await axios.get(
`https://api.github.com/users/${userName}/repos?per_page=100`,
);
for (const el of scoreBasis.data) {
const repoName = el.name;
if (el.fork) {
forkingCount++;
} else {
///여기부터
const reposLang = await axios.get(
`https://api.github.com/repos/${userName}/${repoName}/languages`,
{
headers: {
Authorization: `Bearer ${TOKEN}`,
},
},
);
const languages = reposLang.data;
for (const lang in languages) {
if (programmingLang.hasOwnProperty(lang)) {
programmingLang[lang] += languages[lang];
} else {
programmingLang[lang] = languages[lang];
}
///여기까지코드를 볼 때 한 가지 알아둬야 할 사실은, 오래 걸리는 이유를 설명하기 위해 불필요한 중간 부분(변수 선언 및 카운팅 용 로직)은 다 걷어냈기에 괄호라던가 이런게 맞지 않을 수도 있다는 점이다!
저 for 문은 다른 지표를 카운팅할 때도 쓰이긴 하지만 가장 중요한건 바로 등록하려는 유저가 가장 많이 사용하는 언어를 계산할 때 쓰이는 로직(여기부터 여기까지)이 비동기 함수임에도 불구하고 실행은 병렬적으로 되는 것이기 아니 때문에 오래 걸리는 것이다. 한 마디로 하나의 레포 수를 실행을 해야 (끝난 것과 상관없이) 다른 레포에 접근한다는 얘기다. 그렇기에 아무리 비동기 함수라고 해도 실행 단계에서 차이가 생길 수 밖에 없기 때문에 레포가 많은 사람일 수록 더욱 로직이 오래 걸리게 되는 것이다 그 유명한 노마드 코더의 경우 랭킹 등록을 할 때 까지 1분이라는 시간이 걸렸다
그래서 병렬적으로 함수를 실행 할 수 있는 방법이 어떤 것이 있을까? 고민하다가 Promise.all() 메서드가 떠올라서 바로 적용했다..그랬더니 놀라운 결과를 얻을 수 있었는데 바로 이것이다.

동일 유저를 등록한 결과 For문의 걸린 시간이 대략 15배 정도 감소가 된 것이다. 대단한 성과였다.
로직은 다음과 같이 리팩토링 되었다.
for (const el of scoreBasis.data) {
const repoName = el.name;
if (!el.fork) {
personalRepoCount++;
reposLangPromises.push(
axios.get(
`https://api.github.com/repos/${userName}/${repoName}/languages`,
{
headers: {
Authorization: `Bearer ${TOKEN}`,
},
},
),
);
}
}
const reposLangArray = await Promise.all(reposLangPromises);
for (const reposLang of reposLangArray) {
const languages: object = reposLang.data;
for (const lang in languages) {
if (programmingLang.hasOwnProperty(lang)) {
programmingLang[lang] += languages[lang];
} else {
programmingLang[lang] = languages[lang];
}
}
}Promise.all()은 인자로 iterable한 프로미스들을 인자로 받기 때문에 실행해야 할 객체 Github API들을 배열에 담고 그 배열을 Promise.all에 넣어 실행시켜주는 것으로 한 방에 해결 한 것이다. 이 때 한 가지 주의해야 할 점은 배열 안에서 실행되는 프로미스들은 독립적이어야 된다는 것이기에 여기에 적용을 해 준 것이다.
물론 Promise.all()이 이와 비슷한 모든 로직에 대한 해결법은 아니다. 실행되는 깃 허브 api 중 하나라도 에러가 나면 실행이 중단되기 때문이다.
하지만 이 부분에서만큼은 그 리스크가 줄어들고 어느정도 핸들링이 가능하기에 성공적으로 적용시켰으며, 다른 비슷한 로직에서도 Promise.all() 사용하여 시간을 단축하였고 결과적으로 노마드 코더와 같은 유명하고 깃허브 활동이 활발한 사람들의 랭킹 등록시간이 15초 내외로 줄어들었다.
💥 스폰서 수를 구하기 위한 cheerio 사용
스폰서 수...
위에서 잠깐 언급했지만, Github는 자체적으로 스폰서 수를 구할 수 있는 API를 제공하지 않는다..
그래서 결국 제 3자의 API를 찾아 기뻤지만 가면 갈 수록 문제가 하나씩 들어났다.
-
평균적으로 1.5~2.5초의 시간 소요
-
연속적으로 요청시 서버 에러 발생.
그 외 API가 내가 원하는 대로 동작하지 않아서 우회해서 사용하기 때문에 2번 이상 요청을 해야 한다든 것이 있어서 짜증났지만 2번을 발견하기 전까지는 그래도 사용할 만 했다.
Github API를 사용해서 유저의 정보를 빼오는 웹사이트를 보면 평균 20~30초의 로딩 시간이 걸리는거 보면 1번은 사실상 그냥 넘어가도 될 문제였다.
근데...2번을 발견한 직후..아 이건 아니다라는 결론을 지었다.
쉽지 않았다. 그래서 제 3자의 깃허브의 코드를 하나 하나 분석해서 내 것으로 바꾸기로 결심했다.
원리는 다음과 같았다. 그 사람이 사용했던 것은 API가 아닌!! 특정 유저의 스폰서들의 이미지를 나열한 Github의 주소에서 HTML들을 가져와서 재정립한 것이다.

예를 들어 위 사진은, f라는 깃허브 유저의 스폰서 수를 보여주는 보시다시피 Private Sponsor를 포함해 11명이 존재하고 있으며, 제 3자는 이를 HTML을 가져와서 사진의 수를 센 것이다 (신기하게 TypeScript 코드를 공부한 이후, Python이나 Java와 같은 다른 언어들을 파악하는 실력이 늘은 것 같다).
어쨌든 그래서 나도 같은 방식으로 구현하기로 했다.
let pg = 1;
let rawHTMLString;
do {
const sponsors = await axios.get(
`https://github.com/sponsors/${userName}/sponsors_partial?page=${pg}`,
{
headers: {
Authorization: `Bearer ${TOKEN}`,
},
},
);
const html = sponsors.data;
rawHTMLString = cheerio.load(html);
if (rawHTMLString.root()[0]['x-mode'] === 'no-quirks') {
break;
}
sponsorsCount += rawHTMLString('div').length;
pg++;
}
while (rawHTMLString('div').length > 0);cheerio로 가져온 HTML을 확인해보니 div 태그로 사진이 나뉘어져 있었고 저 사람의 갯수를 셌더니 정확히 11개가 있어서 바로 적용했다. 다른 유저들도 덩달아 확인해본 결과 정확히 작동을 했다..
하.지.만...세상은 그렇게 호락호락하지 않았다. 저 링크에는 페이지네이션이 걸려있어 언제 끝날지 정확히 모르기 때문에 do/while을 사용하였는데 스폰서가 없는 유저의 경우 그 유저의 프로필로 리다이렉트가 되기 때문에..div가 무한히 증가한다....
그렇다...스폰서가 있는 사람과 없는 사람의 분기점을 구별할 수 없게 된 것이다..그래서 생각했다.. HTML에서 분명히 차이가 있을 것이다. 그래서 파고 또 팠다. rawHTMLString을 파고 또 파고 들어가 찾아낸 것이 바로 x-mode이다.
x-mode는 몇 몇의 브라우저에서 쓰이는 속성 중 하나로 다큐먼트의 랜더링 모드를 나타낸다. "no-quirks"는 다큐먼트가 표준 모드라는 뜻을 뜻하고 quirks는 브라우저의 예전 버젼을 위해 디자인 된 웹사이트와 호환성을 유지하기 위해 예전 브라우저에서 사용되는 랜더링 모드라고 한다.
저 사진에서 보는 것처럼 스폰서를 가진 사람들은 예전 브라우저의 형태를 유지한 채로 사진을 보여주고 있으니 quirks로 보여주는 것 같고 이 부분이 바로 분기점이라고 생각하여 적용하였더니 총 50명에게 테스트를 해본 결과 정상적으로 작동했다. 스폰서가 없는 사람들은 최신 랜더링 기법으로 리다이렉트가 되니 no-quirks를 보여주는 것 같다.
💥 환경 변수에 적용된 토큰 교환
복병이 생겼다...
위에서도 언급했지만...
Github API는 개별 토큰마다 요청 수에 제한이 걸려있는데 1시간 마다 최대 5000번을 요청할 수 있다.
그.런.데. Github API 중 Search가 들어간 API의 경우...분당 요청 수가 30번으로 제한되어 있다...
유저 한 명의 랭킹을 등록하는데 소요되는 Search API의 요청 수는 3회..즉 분당 10번만 다른 유저들을 등록해도 토큰에서 접근 거부 에러를 뱉어낸다.
절망이었다. 처음에는 어떻게 해야할지 몰랐으나 생각해보니 간단했다. 로직을 요청할 때마다 토큰을 계속 바꿔주는 것이다.
private TOKENS = (process.env.PERSONAL_ACCESS_TOKEN).split(',');
private currentTOKEN = 0;
async getRankerDetail(userName: string) {
try {
const TOKEN = this.getNextToken();
}catch(e){}
}
private getNextToken() {
const token = this.TOKENS[this.currentTOKEN];
this.currentTOKEN = (this.currentTOKEN + 1) % this.TOKENS.length;
return token;
}함수를 중간에 생략했지만 원리는 다음과 같다.
.env file에서 토큰을 PERSONAL_ACCESS_TOKEN=A,B,C,D 이런 식으로 선언하여 서비스 로직에서 배열로 변환해 주고 클래스가 인스턴스화 되면서 실행되는 고정 인덱스를 0, 서비스 CLASS 내부에서만 호출 할 수 있는 getNextToken() 함수를 만들어 인덱스를 1 씩 증가시키는 로직 만들어 준 다음 getRankerDetail() (랭커 등록 함수) 실행 할 때 마다 인덱스가 1씩 증가하면서 배열을 순회하며 토큰을 교환한다.
이렇게 하니 바로 해결! 두둥!!!
으아~ 뿌듯하다!
💥 NestJS/schedule 활용
이것도 생각보다 간단했다. 우리 서버는 아직까지 등록된 랭커들의 정보를 자동으로 갱신하는 로직을 만들어두지 않았기 때문에 처음 부여 받은 티어가 업데이트를 해주지 않는 이상 계속 유지된다. 그래서 티어만이라도 유저 수가 증가됨에 따라 변동할 수 있도록 30분 마다 실행되는 함수를 만들어 주었다.
@Cron(CronExpression.EVERY_30_MINUTES)
async refreshTier() {
const top100 = await this.rankerProfileRepository.getTop100(`IS NOT NULL`);
const tierData = await this.tierRepository.getTierData();
const scores = await this.rankingRepository.getAllScores();
const ranking = scores
.map((el) => parseFloat(el.total_score))
.sort((a, b) => b - a);
top100.forEach((el) => {
const newPercentile =
((ranking.indexOf(parseFloat(el.totalScore)) + 1) / ranking.length) *
100;
let tierId = 0;
for (const t of tierData) {
if (
newPercentile > parseFloat(t.endPercent) &&
newPercentile <= parseFloat(t.startPercent)
) {
tierId = t.id;
}
}
this.rankingRepository.updateRankerTier(el.rankerProfileId, tierId);
});
console.log('티어 갱신');
}
}@nest/schedule이란 패키지 내부에는 다양한 데코레이터를 제공해주는 데 그 중 @Cron은 @Interval과 비슷한 역할을 하지만 조금 더 User-Friendly인 것 같다.
데코레이터가 적용된 함수를 특정 분기마다 반복 실행해준다.
📋 회고
이렇게 내가 기획한 서비스 로직이 마무리 되었다.
물론 아직 서비스가 운영되고 있기 때문에 내가 생각하기에는 Refactoring 할 것도 많고 추가 구현하고 싶은 로직도 다양한다.
예를 들어
-
1주일마다, 각 유저별의 점수 차를 구하고 그 차로 얼마나 자신이 발전했는지 알수 있도록 기록하고 비교하는 로직
-
국가별로 랭킹 비교
-
DB에 등록된 모든 유저의 랭킹 정보 자동 업데이트 (이건...5개의 토큰으로는 한계가 있는 것 같다)
등 다양한 방법이 많이 남아있기에 가슴이 두근 거린다.
이번 프로젝트로 정말 많이 성장했다고 자부심있게 말할 수 있다.
비록 처음 기대했던 것과는 다른 것을 하게 되었지만 그만큼 다른 무엇인가를 많이 얻었다.
이 다음에는 어떤 로직을 만들게 될 지..가슴이 두근두근 하다.
이 다음 게시글은 배포와 운영 관련인데, 배포는 완성되었지만 개념 정립이 아직 덜되었기에 시간이 걸릴 것 같다.

역시 현상님 멋집니다 👍👍