1. 모델
어떤 X가 주어졌을 때, f라는 함수를 통해 y라는 값을 도출하는 과정
이 때, f를 모델 또는 알고리즘이라 부른다.
모델의 수식
- y = F(X)
- X : 데이터
- y : 예측값
모델의 목적
- 데이터를 이용해 값을 예측
모델의 평가
- 모델이 값을 잘 예측하는지 평가
2. Overfitting & Underfitting
과소적합 ( Underfitting )
- train data를 잘 맞추지 못하는 현상
과대적합 ( Overfitting )
- train data는 잘 맞추지만 학습 데이터 외에는 잘 맞추지 못하는 현상
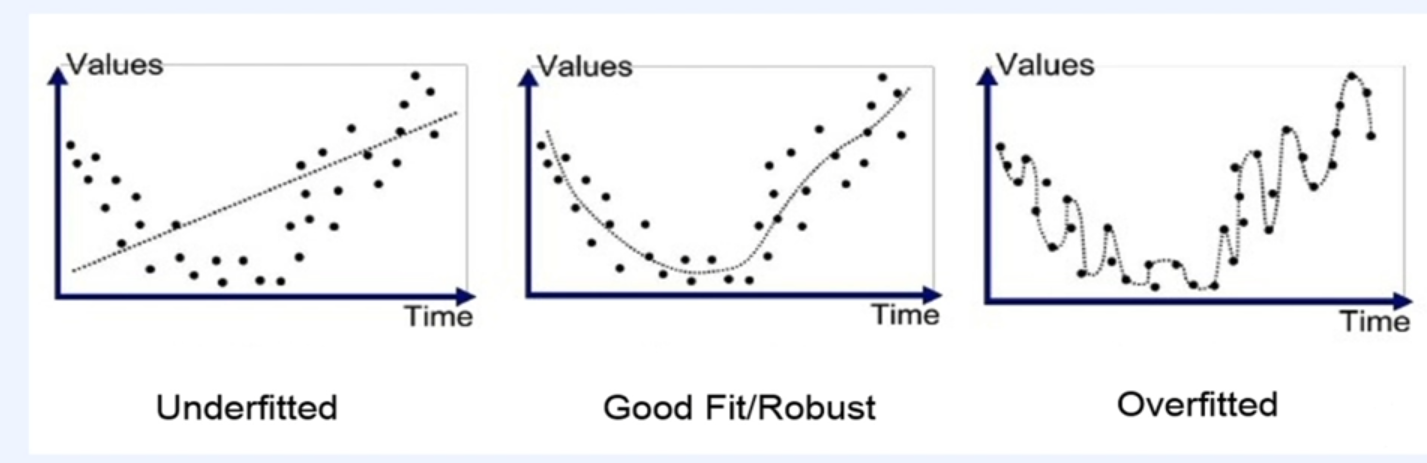
과소적합 확인 방법
- train data로 학습된 모델을 train data로 평가한다.
- train data를 잘 맞추지 못한다면 과소적합 상태
과대적합 확인 방법
- train data로 잘 학습한 모델을 Test data로 평가
- train data는 잘 맞추지만 test data를 잘 맞추지 못한다면 과대적합 상태
3. Data Split
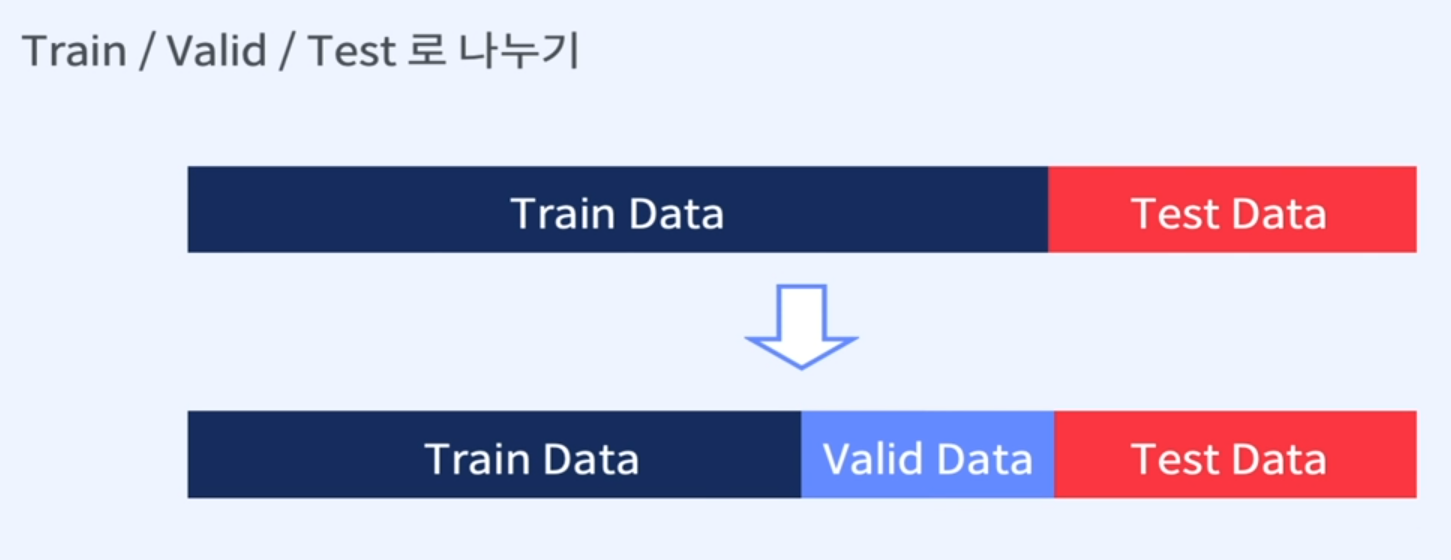
train
- 학습에 사용되는 데이터
valid
- 학습이 완료된 모델을 검증하기 위한 데이터
- 학습에 사용되지는 않지만 관여하는 데이터
test
- 최종 모델의 성능을 검증하기 위한 데이터
- 학습에 사용되지도, 관여하지도 않는 데이터
Valid data는 학습에 사용되지 않지만 관여하기 때문에,
과대적합이 될 수 있다.
Cross Validation - 교차 검증
- valid data를 고정하지 않고 변경함으로써 과대적합을 막는 방법
4.Cross Validation - 교차 검증
LOOCV ( Leave One Out Cross Validation )

- 데이터 개수만큼 학습하기 때문에 시간이 오래 걸린다.
K-Fold
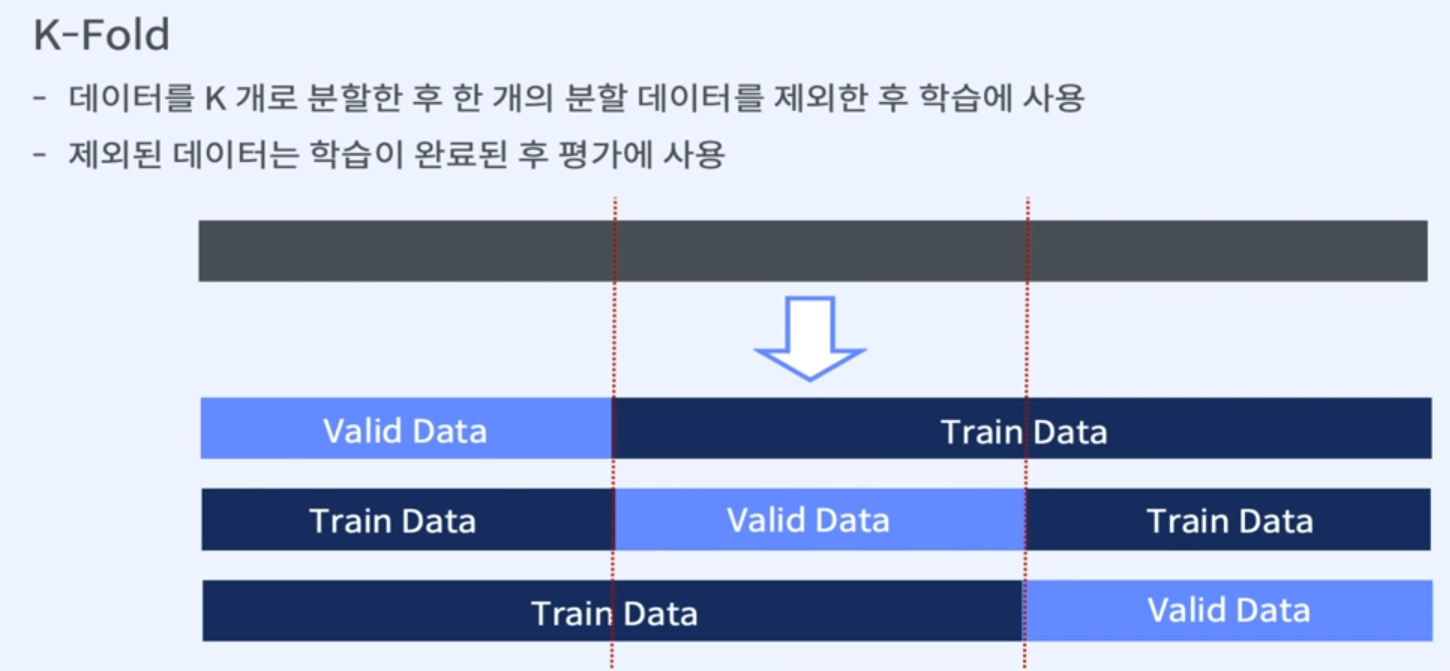
- K 개의 평개 지표가 생성
- 생성된 평가 지표의 평균을 이용해 모델의 성능을 평가
- 전체 train data를 이용해 모델 학습
