1. 정의
의사결정과 그 결과물들을 트리 구조로 도식화한 것
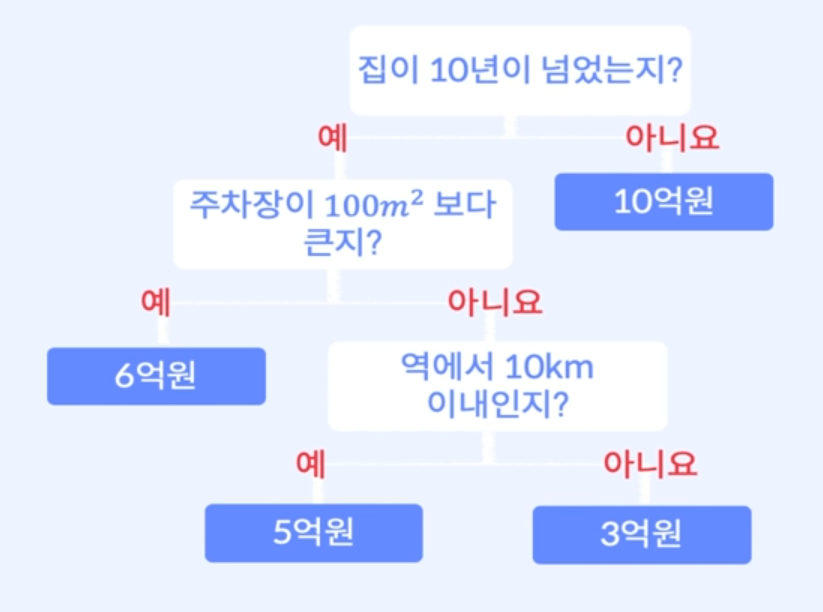
구성 요소
-
Root Node
- 트리구조가 시작되는 마디
- 전체 데이터로 이루어져 있다. -
Internal Node
- 트리 구조의 중간에 있는 마디들 -
Terminal Node
- 트리 구조의 끝에 위치하는 마디들
- 끝 마디에서는 더 이상 노드가 생성되지 않음 -
Depth
- Root Node에서 Terminal Node까지의 노드 수
2. 알고리즘
CART - Classification And Regression Tree
-
각 분할에서 정보 이득을 최대화 하는 것 ( 불순도의 감소 )
-
분할 : Node에서 데이터가 어떤 기준에 의해 나눠지는 과정
정보이득 ( 또는 불순도 ) - 정답에 범주형 변수인 경우
- 엔트로피 지수
- 지니 지수
정보 이득 ( 또는 불순도 ) - 정답이 연속형 변수인 경우
- MSE를 이용한 분산량 감소
3. 정보이득
엔트로피
정보의 불확실성의 정도를 나타내는 양.
데이터를 잘 구분할 수 없을 수록 Entropy는 커진다.
정보이득의 최대화 > 불순도 감소 > Entropy 감소
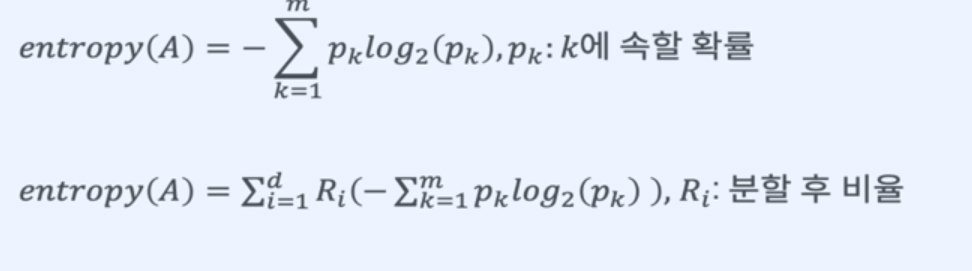
지니 지수 ( Gini Index )
불평등의 정도를 나타내는 통계학적 지수
데이터가 비슷하게 있을 수록 지니 지수가 높아짐.
정보이득의 최대화 > 불순도의 감소 > 지니 지수 감소

- Entropy VS Gini Index
둘다 확률로 계산되지만 Entropy가 지니 지수보다 큰 값으로 계산된다.
MSE
변수가 연속형일 때, node들의 평균으로 예측한다.
평균을 구할 수 있다면 분산도 구할 수 있다.
즉, 분산을 최소화 하는 분할한다.
변수 나누기 - 범주형 변수
데이터 특성의 유무로 분할
정보 이득을 최대화 하는 분할을 선택
- 색 : 정답
- 도형 : 데이터 특성


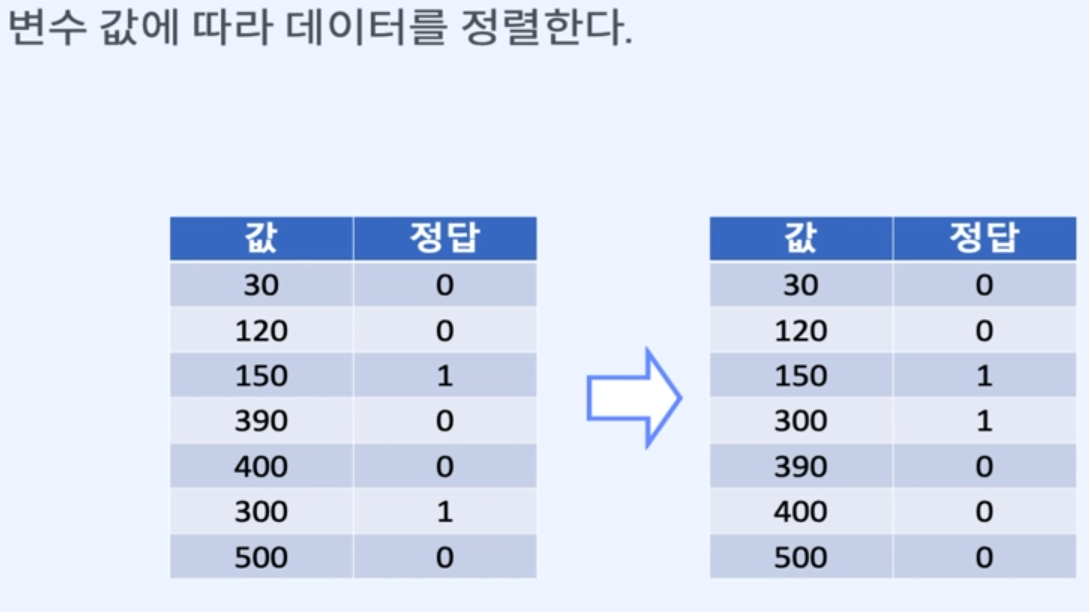
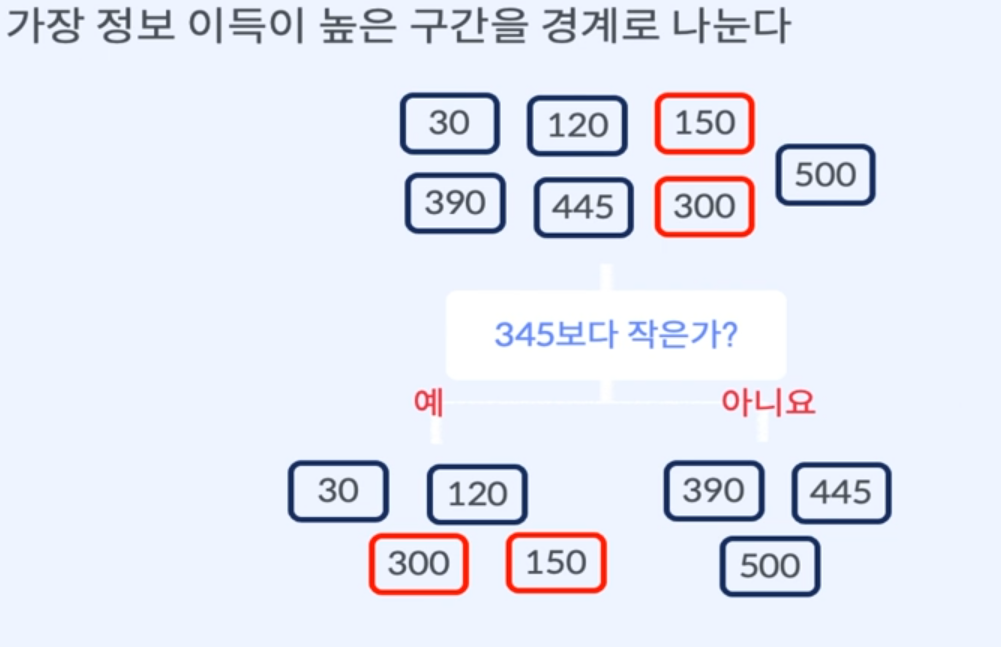
변수 나누기 - 연속형 변수
특성의 유무로 나눌 수 없다.
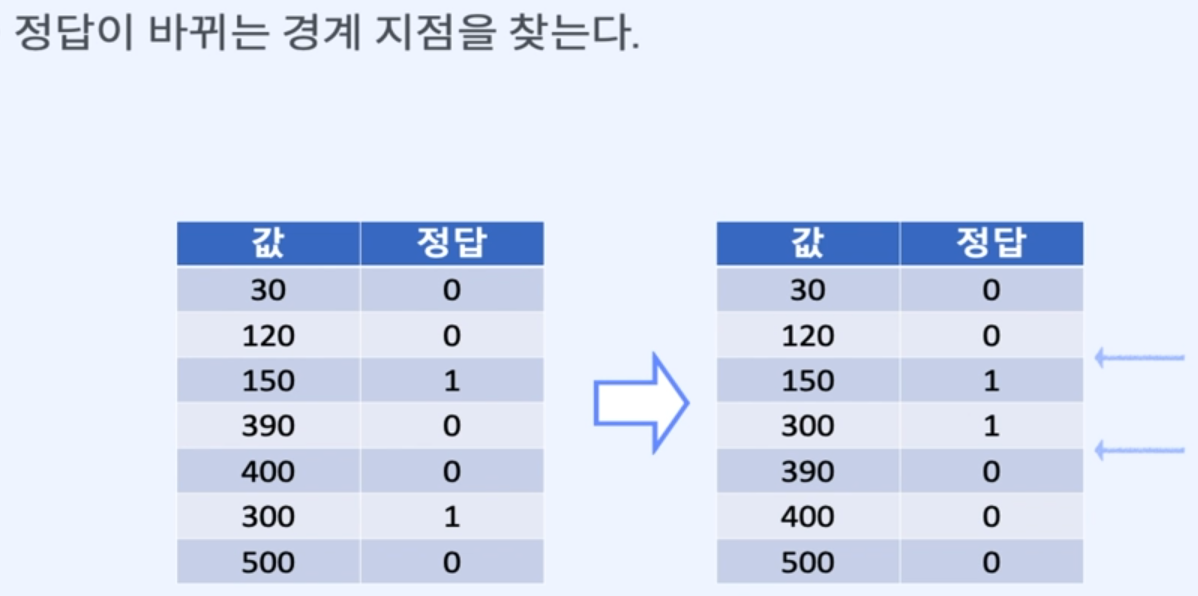
경계값을 찾고 경계값과의 비교를 통해 데이터를 분할.경계값을 찾는 방법
1. 변수 값에 따라 데이터를 정렬
2. 정답이 바뀌는 경계 지점을 찾음
3. 경계의 평균값을 기준으로 잡음
4. 구간별 경계값을 기준으로 불순도 계산
5. 가장 불순도를 낮추는 구간을 경계로 나눈다.



4. Feature Importance - 변수 중요도
Decision tree에서 어떤 변수가 가장 중요한지를 나타내는 정도
불순도를 가장 크게 감소시키는 변수의 중요도가 가장 크다
- 불순도의 감소는 정보 이득의 최대화와 동일한 뜻

5. 가지치기
Full Tree
-
모든 Terminal Node에서의 순도가 100%인 상태
-
분기가 너무 많아서 overfitting 위험이 발생할 수 있음.
분기가 너무 많아지는 것을 막기 위해 적절한 수준에서 Terminal Node를 결합해주는 것.
Pre-Pruning
decision tree의 최대 Depth나 노드의 최소 개수를 미리 지정해
더 이상 분할이 일어나지 않게 하는 방법
Post-Pruning
decision tree를 만든 후 데이터가 적은 노드를 삭제 or 병합
6. Decision Tree 장점 및 단점
장점
- 모델의 예측 결과를 해석하고 이해하기 쉽다.
- 데이터를 가공할 필요가 거의 없다.
단점
- 연속형 변수를 범주형 값으로 취급하기 때문에 분리의 경계점 부근에서 예측 오류가 있을 수 있다.
- noise 데이터에 영향을 크게 받는다.
- overfitting 문제가 발생하기 쉽다.
