
개요
서비스 운영 경험이 있다면 무조건 겪어볼 수 밖에 없는 것은 바로 장애. 모든 서빗는 코드, 시스템, 인프라, 외부 요인 등으로 장애가 발생한다.
장애가 발생하면 빠르게 대응하는 것이 가장 중요하다. 장애가 발생했을 때 얼마나 잘 대응하고 있는지, 그리고 장애 대응 능력을 확인할 수 있는 지표를 소개한다.
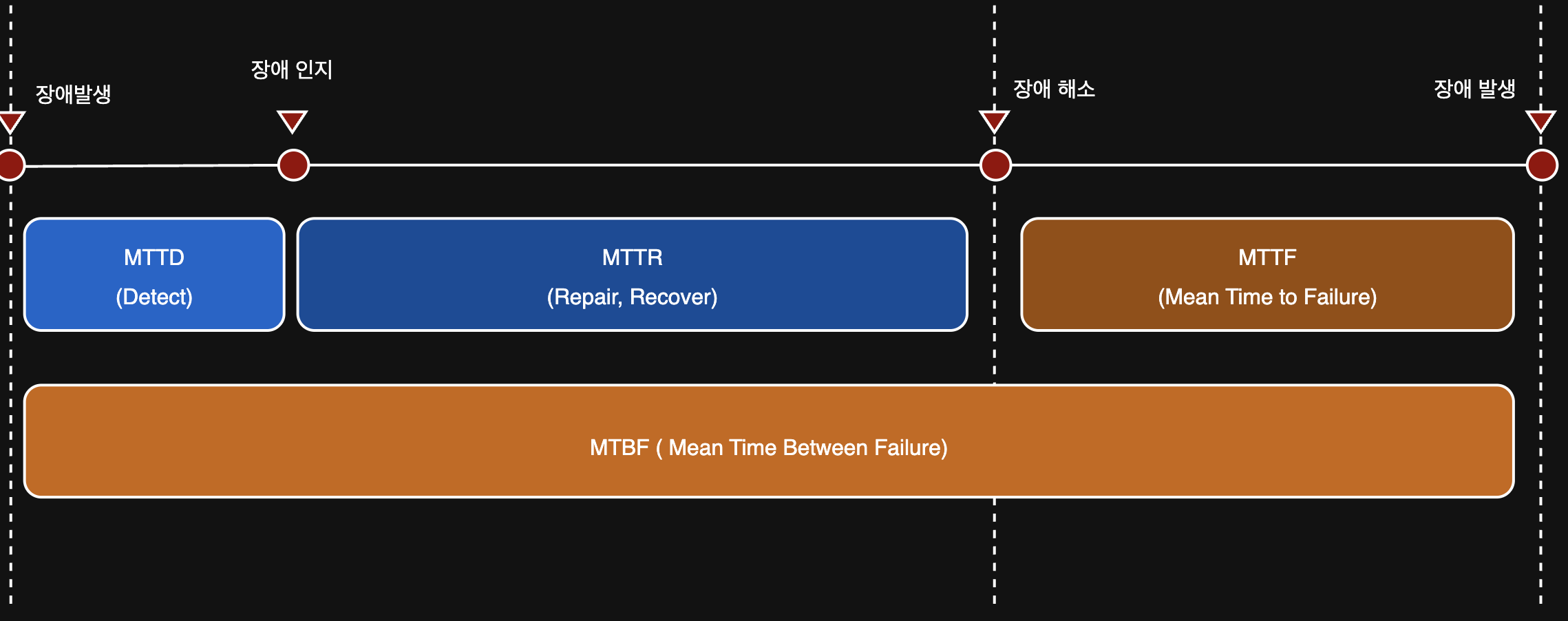
1. MTTD (Mean Time To Detect)
장애가 발생한 이후부터 장애를 인지하기 까지 걸린 평균 시간.
MTTD는 일반적으로 시간 또는 일 단위로 측정되며, 짧으면 짧을 수록 좋다.
- 모니터링이 잘 구축되어있어야 빠르게 인지할 수 있고, MTTD 수치가 표현될 수 있다.
2. MTTR (Mean Time To Rapire)
고장 난 시스템을 수리하고 정상 작동 상태로 복원하는 데 걸리는 평균 시간.
MTTR은 일반적으로 장애로 인한 총 다운타임을 수리 이벤트 수로 나누어 계산하며, 짧으면 짧을 수록 좋다.
3. MTTF (Mean Time To Failure)
시스템을 고친 이후, 다음 장애가 발생하기까지 걸린 평균 시간.
MTTF는 엔지니어링 및 제품 개발에서 구성 요소 또는 시스템의 예상 수명을 평가하는 데 자주 사용되며,
유지 보수 일정, 교체 전략 및 전반적인 설계에 관한 결정을 내리는 데 도움이 된다.
예를 들어 조직에 4대의 컴퓨터가 있고 각 컴퓨터가 10개월, 4개월, 16개월, 3개월 동안 지속된 경우 MTTF는 다음과 같습니다. (10 + 4 + 16 + 3)/4 = 8.25개월의 MTTF를 가진다.
4. MTBF (Mean Time Between Failure)
장애가 발생하는 평균 시간. (간격)
길면 길 수록 좋다.
