
awk
- 기본
awk명령어
awk [OPTION...] [awk program] [Argument...]| OPTION | description | e.g. |
|---|---|---|
-F | 필드 구분 문자 지정 | awk -F '/' '{print($5)}'awk -F "/" '{print($5)}' |
-f | awk 프로그램 파일 경로 지정 | |
-v | awk 프로그램에서 사용될 특정 variable값 지정 | awk -v path='' '{for(i=2; i<=NF; i++) if(..); else(..); print( .. ) }' |
awk program: -f 옵션이 사용되지 않은 경우, awk가 실행할 awk program 코드 지정
awk [OPTION...] 'pattern { action }' [Arguments...]pattern을 생략하면 모든 레코드가 적용action을 생략하면print(default) 동작
Type Conversion
str -> num: +0
- 스트링을 숫자로 만들려면
+0을 해주면 됩니다.
$ awk 'BEGIN{ print (12 > "111") }'
1
$ awk 'BEGIN{ print (12 > "111"+0) }'
0
$ awk 'BEGIN{ print (substr(12345, 1, 2)+0 > 111) }'
0num->str: ""
숫자를 스트링으로 만들려면 "" 로 concatenation 을 하면 됩니다.
$ awk 'BEGIN{ print (12 > 111) }'
0
$ awk 'BEGIN{ print (12 > 111"") }'
1for()
- awk 내 action에서
for()반복문 사용이 가능하다.
for() 내용 ; syntax2
for i in range(0,10):
do_something
print( )와 같은 일을 awk에서 하고 싶다면 아래처럼 해야한다.
awk '{for (i=0; i<10; i++) do_somthing ; syntax2 }'- 위 python 코드에서 저 사이에
;를 두어 syntax 구분을 한다고 생각하자.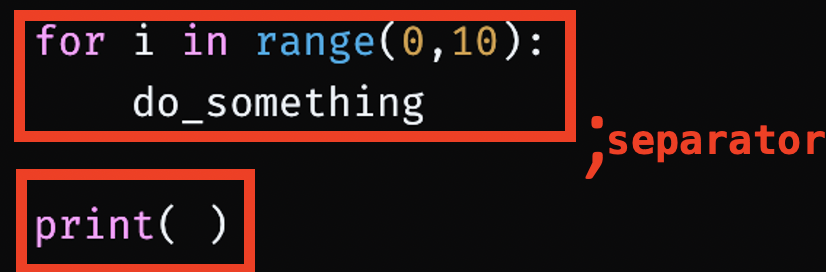

-v VAR='' '{for() ; print}'
| awk -F '/' -v path='' '{for(i=2;i<=NF;i++) path=(path"/"$i) ; syntax2 }'-F '/': awk에게 seperator를 '/'로 지정한다.-v path='': awk 변수path=''를 준다.
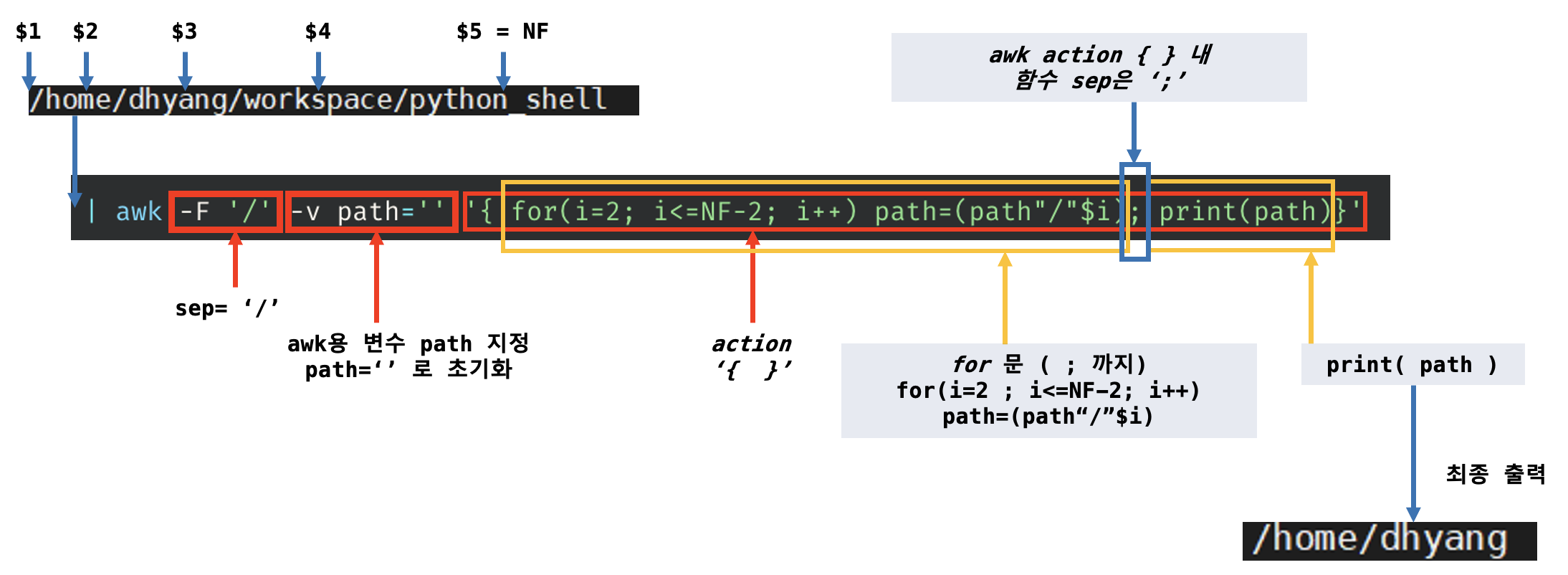
- awk 내부 변수
-v path=''를 선언해awk for문으로 path를 조작
| awk -F '/' -v path='' '{for(i=2; i<=NF-2; i++) path=(path"/"$i); print(path)}'{for() if ; else; print}
for i in range(0,10):
if i == '*':
break
else:
path="{:s}/{:d}".format("path",i)
print(path)와 같은 역할을 하고 싶다고 하자(위의 python의 i와 아래 awk 에서 $i 가 포함하는 내용은 분명 다르지만 넘어감)
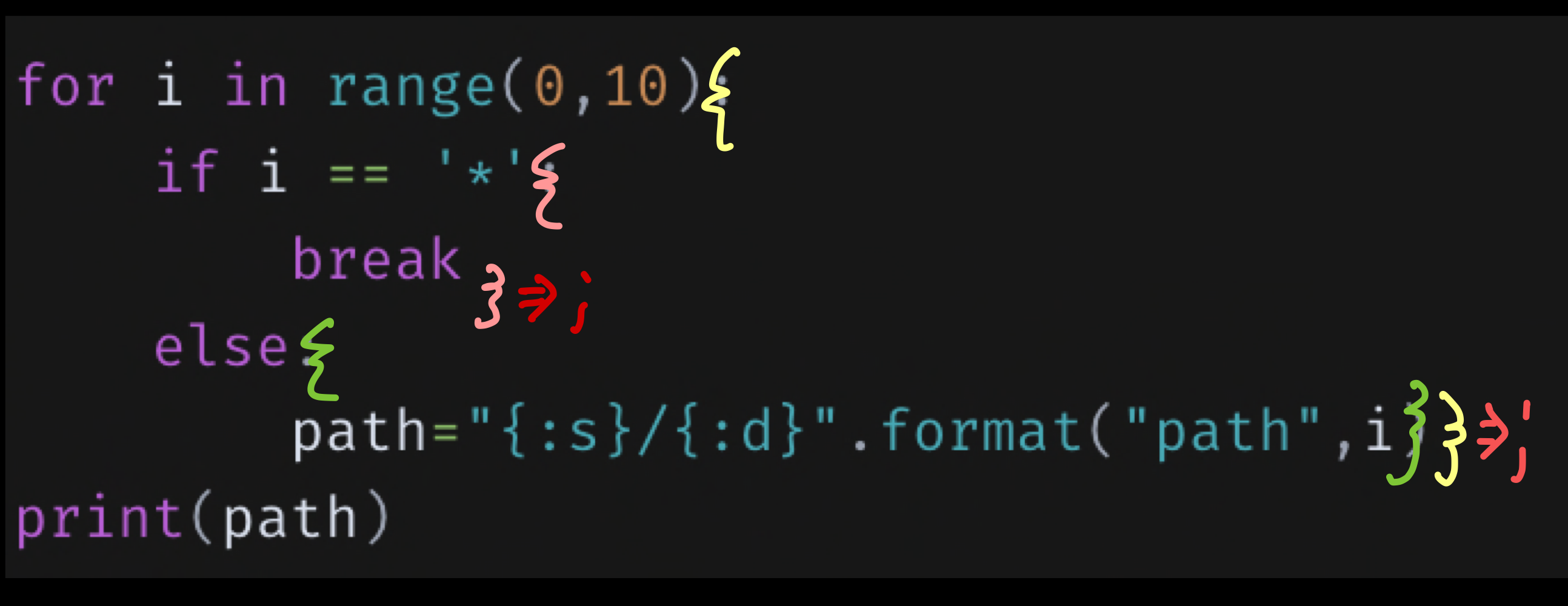 for ...->
for ...-> ;- if ... ->
; - else ... ->
;
- if ... ->
awk -v path='' '{for(i=2;i<=NF;i++) if($i=="*") break ; else path=(path"/"$i); print(path)}'PATH="/home/user/official/*/*/build-artifacts"
echo "$PATH" | awk -F '/' -v path='' '{for(i=2;i<=NF;i++) if($i=="*") break; else path=(path"/"$i); print(path)}'
# ======= 출력 ======= #
/home/user/official내부에서 변수 사용

내부 변수에 if 사용


스크립트에서 여러줄 사용
내부 변수 + 쉘변수($PWD) 사용
poky/
./meta-openembedded
├── contrib
├── COPYING.MIT
├── meta-filesystems
├── meta-gnome
├── meta-initramfs
├── meta-multimedia
├── meta-networking
├── meta-oe
├── meta-perl
├── meta-python
├── meta-webserver
├── meta-xfce
└── README.md- 여기서, ${PWD}/meta-* 를 출력하고 싶다.
find ./meta-openembedded -maxdepth 1 -mindepth 1 -name "meta-*" | awk -F '.' -v PWD="${PWD}" '{print(PWD$NF)}'
/meta-openembedded/meta-xfce
/meta-openembedded/meta-initramfs
/meta-openembedded/meta-networking
/meta-openembedded/meta-perl
/meta-openembedded/meta-python
/meta-openembedded/meta-filesystems
/meta-openembedded/meta-oe
/meta-openembedded/meta-webserver
/meta-openembedded/meta-gnome
/meta-openembedded/meta-multimedia
if()
| awk '{if (조건)}'
e.g.)
| awk '{if(NR==2 || NR==3) print}' = 레코드(행) 2,3 일 때, 한줄 다 출력
| awk '{if(index($1,"rwx") != 0) print($(NF-1))}' = $1 필드에 "rwx"가 들어가 있으면, \
해당 레코드(행)의 마지막 필드 -1의 값 출력if($1=="문자열")
awk '{if($1=="hello") print($2)}'- 필드1이 hello 일 때만, 필드2를 print
if($1 <= 24)
echo "${temp}" | awk -F ':' '{if($1 <= 24) print("yes")}'if(! A)
if(A && B)
if(A || B)
- NR이 1 혹은 2 일 때, print

if ; elseif ; else

;사용 하자

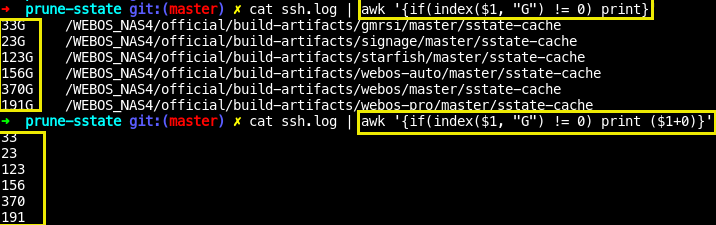
if(index($1,"G")!=0): 문자열 검사
주의!!! 반드시 ($1 , "문자열") 순으로 해야함
{if(index($1,"G")!=0) print(...)}
print 함수
| awk '{if(조건) print("true")}'printf 함수
 C-like printf 문
C-like printf 문
레코드
- 레코드: 행. newline 문자(
\n,LFunix계열)로 구분!
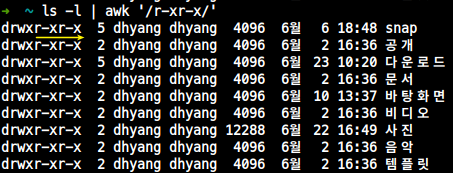
pattern: 레코드 문자 검색 출력
- 레코드(한 줄)에
r-xr-x문자가 들어가는 줄 전부 출력
| awk '/r-xr-x/'- 한 줄마다
/r-xr-x/를 찾으면 한 줄 씩 출력
NR=해당 레코드(행) idx
| awk 'NR==1'
| awk 'NR==1 {print}' 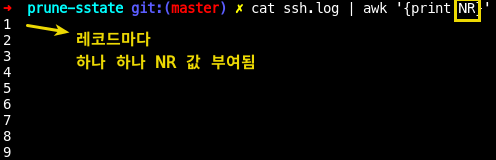
NR값은 하나 하나 해당행에 대해 부여됨
3행만 출력
| awk '{if(NR==3) print}'- 3행만 출력하게 함

2~5행 출력
awk "NR >= 2 && NR <= 5" test.txt| while read line 대체
- redirect와 pipe는 subshell 로서 실행된다.
- subshell의 bg는 부모의 wait가 기다리지 않음!
cat 'file' | while read line; do # <-- subshell 로 실행됨
eval "$line" & # <- bg
done # <-- subshell 끝
wait # 위 bg를 기다리지 않음- awk 이용해 해결하자
LINE_NO=$(cat 'file' | wc -l) # 몇 줄 라인인지 읽음
for ((i=1; i<=${LINE_NO}; i++)); do # 반드시 1 <= LINE_NO 임을 명심
line=$(awk "NR==$i" 'file')
eval $line &
done
wait # 백그라운드 기다림
필드
- 필드: 열. 공백, \t 으로 구분
NF=해당 행의 끝 필드 idx
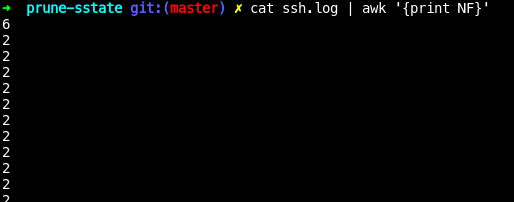
NF에는 한 행의 끝 필드 값(1부터 시작) 들어가 있음- 이를 활용할꺼면,
$를 붙여야함
NF를 활용하려면 $(NF)
awk '{print $(NF-1)}'
- 제일 끝 필드의 -1 번째 print
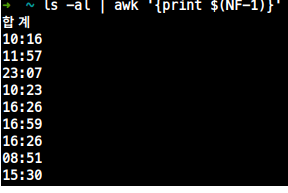
$5의 숫자 다루기(%제거, 더하기)
| awk '{print $5}' --> 53%
| awk '{print $5+0}' --> 53
| awk '{print $5+1}' --> 54- 필드에 +0, +1 등을 붙여서 직접 더할 수 있다.
BEGIN, END
| awk 'BEGIN { action } END { action }'BEGIN: patternBEGIN은awk가 레코드를 처리하기 전, 지정한 action 을 수행케하는 pattern
END: patternEND는awk가 레코드를 다 처리하고 마지막에 지정한 action 을 수행케하는 pattern
| awk 'BEGIN {print "TITLE : Field value 1,2"} {print $1, $2} END {print "Finished"}'sep 변경
-F <sep>옵션으로 변경할 수 있다.
awk -F 'sep' '{ ACTION }'- awk의 기본 separator 는
' '공백 근데, 바꾸고 싶을 때 있다.
예:locale
구분자를=로 하고 싶다.
$ locale | awk -F '=' '{print ($2)}'예: $VAR=/NAS/official/build/hello/master
1. $VAR에서 sep을 / 로 두고 나눠 쓰고 싶다.
$ echo $VAR | awk -F '/' '{print $2}'
NAS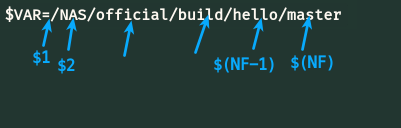
다중 sep 사용
<a herf="...> 내용 </a>
$ awk -F '<a herf=|</a>' '{for(i=2;i<=NF;i+=2){print $i}}' RS="" a.txtshell 명령 사용
awk '{system( )}'
$ cat ./output.txt | awk '{system("rm -rf "$1)}'
# ==== output.txt 내용 ===== #
/file/path1
/file/path2
# ==== awk에 의해 실행 되는 명령어 ===== #
rm -rf /file/path1
rm -rf /file/path2
Data Type
- string은 산술연산에서는
0과 같다. "123mb"와 같이 숫자가 섞여있으면 산술연산을 할 수 있다.
- string -> 숫자 하려면, 스트링에
+0을 붙이면 된다.
"111"+0- 숫자 -> string은
""로 concatenation
111""예제
floating 연산
awk에는 자체 float 연산 기능이 있다.
- Byte -> {K,M,G,T}Byte
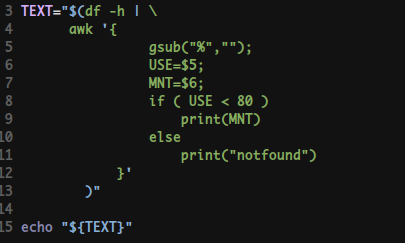
#!/bin/bash
Byte=290121512
function byteToHumanreadable () {
for ((i=0;i<=4;i++)); do
Byte=$(echo "${Byte}" | awk '{if($1<1024) printf("%.2f,done\n",$1); else printf("%f\n",$1/1024)}')
if [[ ${Byte} =~ "done" ]]; then
case $i in
0) SUFFIX="B" ;;
1) SUFFIX="KB" ;;
2) SUFFIX="MB" ;;
3) SUFFIX="GB" ;;
4) SUFFIX="TB" ;;
esac
echo ${Byte} | tr -s ",done" "${SUFFIX}"
break
fi
done
}
byteToHumanreadable
===== 출력 =====
276.68MB$( | awk) 와 | awk 차이
- 그냥
$ pgrep -a sleep
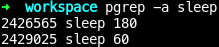
$( pgrep -a sleep | awk '{printf("%d,%s\n",$1,$NF)}' )
$( pgrep -a sleep | awk '{printf("%d,%s\n",$1,$NF)}' ) > A.txt
cat A.txt
2408464,180 2414164,60 2415927,5 2415928,4 2415931,3pgrep -a sleep | awk '{printf("%d,%s\n",$1,$NF)}'
pgrep -a sleep | awk '{printf("%d,%s\n",$1,$NF)}' > A.txt
cat A.txt
2408464,180
2414164,60
2417209,5
2417210,4
2417213,3awk {gsub( )}: 특정 문자를 바꿔서 출력
awk '{gsub("해당 문자를", "이걸로 바꾼다") print}'
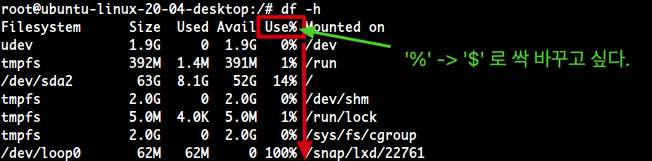
- 우선
Use%필드는 5번째이다.awk '{print$5}'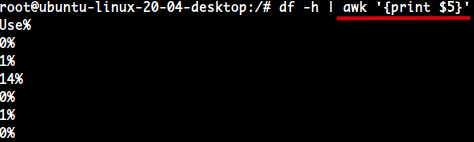
- 여기서 내장함수
gsub()를 사용한다.awk '{gsub("해당 문자를", "이걸로 바꾼다") print$5}'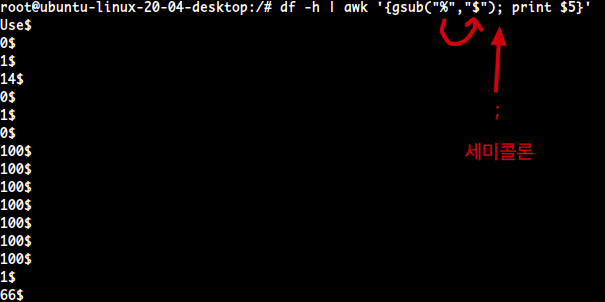
gsub로 특정 문자를 없앨 수도 있다.
awk '{gsub("%",""); print$5}'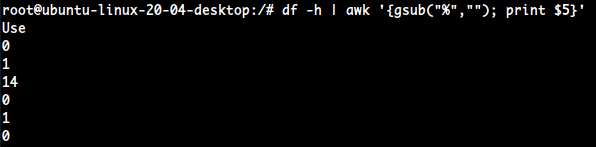
| column -t : sep을 tab으로 바꿈
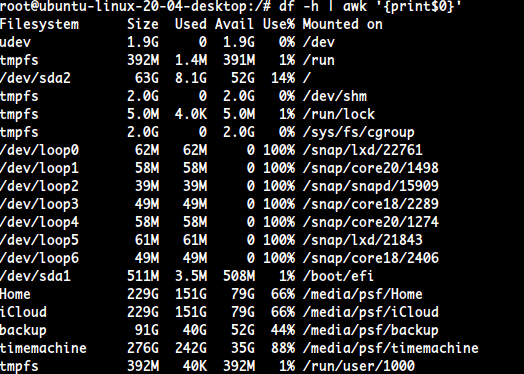
column -t를 쓰지 않았을 때
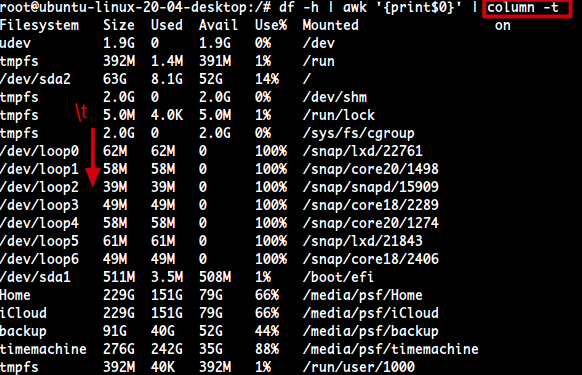
column -t를 Pipe를 통해 사용할 경우 각 구분자가\t로 출력
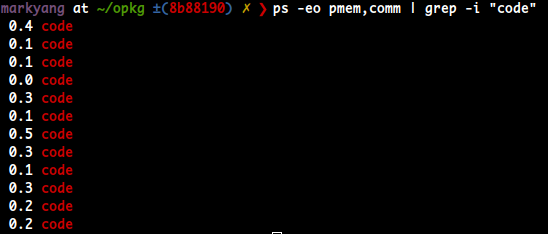
특정 필드 누적 더하기
$ ps -eo pmem,comm | grep -i "<PROCESS>" | awk '{sum+=$1} END {print sum "% of MEMORY"}'- e.g., VSCODE 가 얼마나 사용하는지 보자.


pllpokko@alumni.kaist.ac.kr