서버/인프라를 지탱하는 기술 Ch.4의 내용과 Load Average에 대해 정리하고자 한다.
1. 서론
- 1대의 서버로도 처리할 수 있는 부하를 서버 10대 이상으로 분산한다면 분산의 목적을 제대로 이루고 있지 못한 것이다.
- 우선
단일 서버의 성능을 충분히 끌어낸 다음 서버를 추가하는 방법을 고민해야 한다.
단일 호스트의 성능을 끌어내는 데에는 서버 리소스의 이용현황을 정확하게 파악할 필요가 있다.
MySQL과 같은 애플리케이션의 부하를 먼저 떠올리겠지만, 대상이 되는 것은 그 하위에 있는 OS이다.
부하를 알기 위해 필요한 모든 정보는 OS, 리눅스 커널이 지니고 있다.
ps, top, sar 등의 툴 사용
-> 원인을 추측하지 말고 계측하여야 한다.
2. Load Average와 부하
Load Average란 ?
- CPU와 디스크 I/O가 얼마나 바쁜지를 나타내는 지표이다.
- 1분, 5분, 15분의 평균 값으로 표시된다.
평균적으로 어느 정도의 Task가 대기 상태로 있었는지를 보고하는 지표이다.- Timer Interrupt를 통해 일정 주기로 CPU에 신호를 보내 부하 값을 계산한다.
- 어떤 값을 계산하는지는 바로 아래서 설명
CPU 코어 수에 따라 숫자가 달라지며, CPU 코어가 100% Load가 발생할 경우
1코어는 값 1, 2코어는 값 2로 표현된다.
1코어에서 Load Average가 2라면, 100%는 로드된 상태 100%는 대기하는 상태를 의미한다.
-> top, uptime의 명령으로 확인할 수 있다.
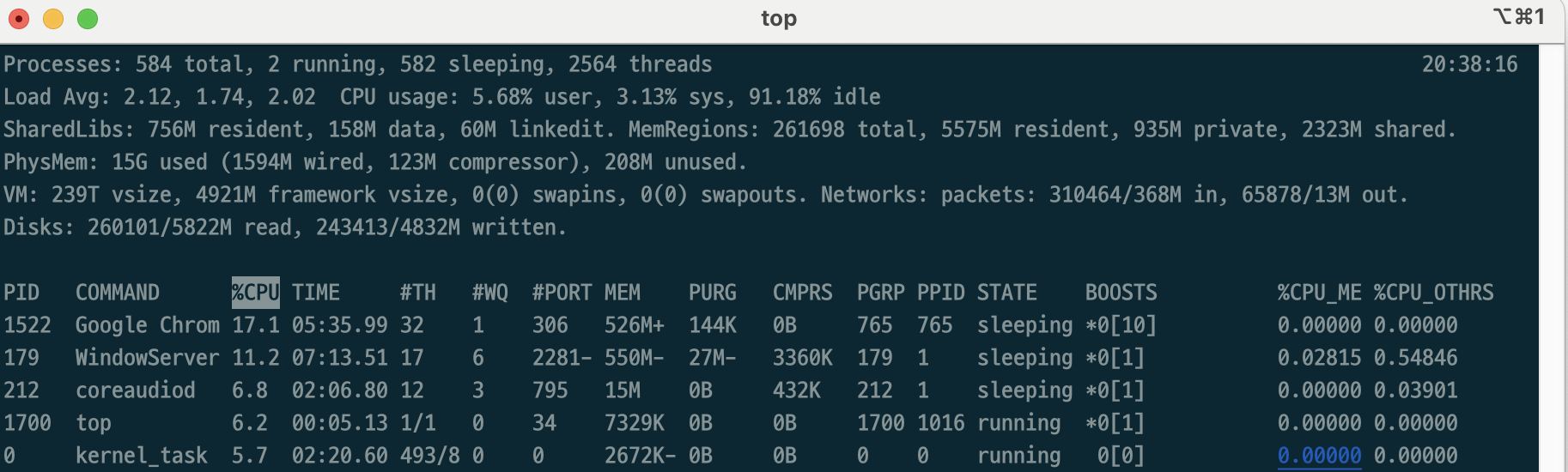
top
- 특정 순간의 OS 상태의 스냅샷을 표시하는 툴이다.
- 출력 내용은 실시간으로 변경되므로, OS의 동향을 조망하고자 할 때 편리하다.
- CPU 사용률이나 메모리 사용현황 등 다양한 값이 보고된다.
uptime
- 현재 시간, 시스템 가동 시간, 로그인한 사용자 수, 그리고 1분, 5분, 15분 간의 Load Average를 표시

부하란 ?
- 부하란 여러 Task에 의한 서버 리소스 쟁탈의 결과로 생기는
대기 시간이다. - 부하의 종류로는 크게 CPU 사용률, I/O 대기율이 있다.
프로세스 스케줄러에 의해 가질 수 있는 프로세스 상태는 다음과 같다. ( 간략히 )
TASK_RUNNING : 실행 가능한 상태 -> R(Running)
TASK_UNINTERRUPTIBLE : 디스크 입출력 대기, 중단 불가능 -> D(Uninterruptible wating)
TASK_INTERRUPTIBLE : 키보드 입력 대기, 중단 가능
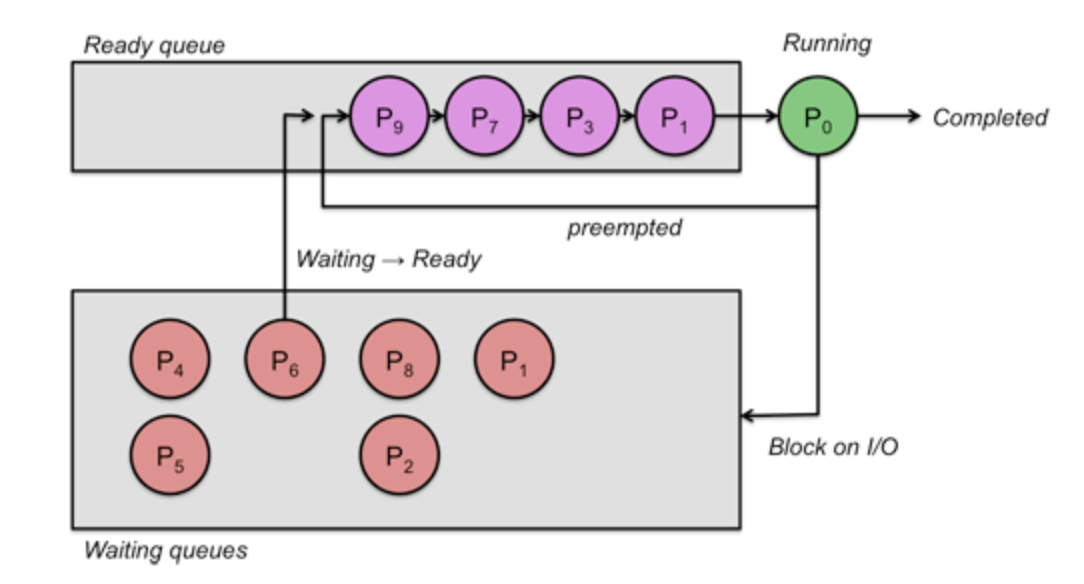
다음 그림과 같은 상황일 때, Ready queue에서 대기하거나, Waiting queue에서 네트워크 또는 디스크 I/O 작업으로 인해 대기해야 하는 시간이 부하라고 볼 수 있다.
-> 프로세스 입장에서 요청에 대한 응답이 올 때 까지 아무것도 할 수 없다.
-> 해당 상태가 많으면, 특정 요청이 끝나기를 기다리는 프로세스가 많다는 것으로 부하 계산에 포함된다.
Ready queue -> CPU의 실행 권한이 부여되기를 기다리고 있는 프로세스
Waiting queue -> 네트워크 또는 디스크 I/O가 완료하기를 기다리고 있는 프로세스
반면, TASK_INTERRUPTIBLE ( 사용자의 특정 행동을 기다리고 있을 경우) 에는 사용자가 동작을 하고 있지 않은 것이니 Load Average 계산에 포함되지 않는다.
Load Average는 시스템 전역변수 배열에 평균 4ms 마다 인터럽트를 주며 결과를 저장하고 있는다.
3. Load Average의 한계
Load Average는 어디까지나 대기 Task 수 만을 나타내는 수치이므로,
Load Average만으로는 CPU 부하가 높은지, I/O 부하가 높은지는 판단할 수 없다.
sar를 통해 관측할 수 있다.
- CPU, %iowait, %system 사용률을 볼 수 있음.
4. 멀티 CPU와 CPU 사용률
멀티 CPU가 탑재되어 있더라도 디스크는 하나밖에 없는 경우
- CPU 부하는 다른 CPU로 분산되어도, I/O 부하는 분산되지 않는다.
CPU 사용률
- Load Average는 CPU에 엮인 실행 큐가 유지하고 있는 프로세스 디스크립터의 수를 세었다.
- Load Average의 값이 저장되는 영역은 커널 내의 전역변수 배열이다.
- CPU 사용률의 계산결과는 전역변수 배열이 아닌, 각 CPU용으로 준비된 전용 영역에 저장된다.
- CPU 별로 지닌 영역에 데이터를 저장하고 있으므로 sar 등에서 CPU별 정보를 얻을 수 있다.
Load Average는 어디까지나 시스템 전체 부하의 지표가 되는 값으로, 그 이상 자세한 분석이 불가능하다.
CPU 사용률이나 I/O 대기율은 전체의 합계로 보고되지만 개별적으로 확인할 수 있고, 그럴 필요가 있다.
CPU 부하가 높은 경우
- 사용자 프로그램의 처리가 병목인지, 시스템 프로그램이 원인인지 판단한다. ( top, sar )
- ps로 볼 수 있는 프로세스의 상태나 CPU 사용시간 등을 보면서 원인이 되고 있는 프로세스를 찾는다.
- 프로세스를 찾은 후 보다 상세하게 조사할 경우는, strace로 추적하거나 oprofile로 프로파일링을 해서 병목 지점을 좁혀간다.
I/O 부하가 높은 경우
- 프로그램으로부터 입출력이 많아서 부하가 높음
- 스왑이 발생해 디스크 액세스가 발생하고 있는 상황
- sar, vmstat로 스왑의 발생상황을 확인해서 문제를 가려낸다.
프로그램 오류로 메모리를 지나치게 사용하고 있는 경우에는 프로그램을 개선
탑재된 메모리가 부족한 경우에는 메모리를 증성
메모리 증설로 대응할 수 없는 경우는 데이터 분산이나 캐시 서버 도입을 검토.
5. 튜닝
튜닝의 본래 의미는 병목현상이 발견되면 이를 제거하는작업이다.
하드웨어나 소프트웨어가 지니고 있는 성능 이상의 성능을 내는 것은 아무리 노력해도 불가능하다.
본래 지닌 성능을 충분히 발휘할 수 있도록 문제가 될 만한 부분이 있다면 제거하는 것이다.
I/O 성능을 개선하기 위한 규명
- 메모리를 증설해서 캐시 영역을 확보함으로써 대응할 수 있는가?
- 원래 데이터량이 너무 많지는 않은가?
- 애플리케이션 측의 I/O 알고리즘을 변경할 필요가 있는가?
원인을 알면 해당 원인에 대한 대응방법은 자명한 것이다.
이렇게 자명해진 대응 방법을 실천하는 것이 튜닝이다.
그 외
App의 부하분산
- 일반적인 AP 서버는 DB로 부터 얻은 데이터를 가공하여 클라이언트로 전달한다.
- 그 과정에서 대규모 I/O를 발생시키는 일은 드물다.
- AP 서버는 CPU 바운드한 서버이다.
DB
- DB는 데이터를 디스크로부터 검색하는 것이 주된 작업으로, I/O 바운드한 서버이다.
