클러스터링
- 여러 개의 DB를 수평적인 구조로 확장 (
Active - StandBy) - 노드들 간의 데이터를 동기화하여 일관성 있는 데이터를 유지할 수 있다
- 1개의 노드가 죽어도 다른 노드로 운영 가능
- 장애가 전파된 경우 처리가 까다로움
레플리케이션
- 여러 개의 DB를 수직적인 구조로 확장 ( Master - Slave )
- 비동기로 동기화 수행
해당 분산 환경에서 트랜잭션을 관리하는 방법
Two Phase Commit
- 2단계를 거쳐 커밋이나 롤백을 진행하는 과정
- 트랜재션을 조율하는 coodinator (조정자) 존재
- 1단계 : Prepare → 데이터를 저장할 수 있는 상태인지 확인
- 2단계 : Commit
- 이 과정 중 한 대의 DB라도 Commit할 수 없다면, 모두 Rollback
→ NoSQL은 제공하지 않는 문제가 있음
→ 서비스가 많아질 경우 응답 시간이 지연된다.
→ Coodinator가 단일 장애 지점
Saga 패턴
-
트랜잭션 관리 주체를 DBMS가 아닌 Application로 변경
-
App 하위에 있는 DB는 로컬 트랜잭션만 관리
-
연속적인 트랜잭션에 대한 실패 처리를 어플리케이션에서 구현해야 한다
-
격리성을 보장해 주지 않지만, 최종 일관성을 보장해준다
Choreography-Based Saga -
로컬 트랜잭션을 관리하고, 완료 시 완료 이벤트를 처리하고, 다음 어플리케이션에서 완료 이벤트를 수신하기 전까지 대기한다
-
그 후 다음 작업 실행
-
구축하기 쉬우나, 트랜잭션 상태를 알기 어려움
Orchestration-Based Saga -
트랜잭션 처리를 위한 별개의 Saga 인스턴스가 존재
-
완료 및 실패 여부를 매니저 인스턴스에 수신하고, 모두 완료되면 인스턴스를 종료하며 작업 종료
Master / Slave Data 동기화 전 까지 데이터 정합성을 지키는 방법
다중 스레드로 쓰기 작업을 수행하는 Master 와 단일 스레드로 쓰기 작업을 수행하는 Slave 간의 속도차에 의해 병목이 발생하게된다.
리플리케이션 과정 중 이러한 병목 현상을 복제 지연이라고 한다.
반동기 복제방식 (Semi-Sync Replication)
- MySQL 5.5 부터 도입
- 최소 1대 이상의 복제에 필요한 릴레이 로그 동기화를 보장한다.
- AFTER_SYNC 모드 방식으로 마스터 엔진에 커밋되기 전에 Slave 릴레이로그 저장을 기다린다.
- 모든 Slave를 기다리는 것이 아닌 Slave 중 단 1대만이라도 릴레이로그를 수신했다면 Master는 트랜잭션을 완료한다.
- 최소한의 데이터 정합성을 확보하고 Slave DB의 지연이 트랜잭션 지연으로 이어지지 않게 된다.
MHA ( Master High Availability )
- Master DB의 고가용성을 위해 개발된 오픈소스
- Master 헬스 체크를 주기적으로 수행하던 Slave에서 자동으로 가장 최신 상태의 Slave DB를 Master로 승격시켜 Fail-Over 하는 것
Semi-Sync Replication + MHA
- 단 한대라도 릴레이 로그를 수신했고, 릴레이 로그 복구 과정을 통해 동기화하기 때문에 데이터 유실가능성을 낮출 수 있다.
Shading
-
테이블의 데이터를 특정 기준으로 나누어 저장하는 방식
-
잘 분산시켜 저장해야 하고, 읽을 때 정확한 위치에서 잘 읽어야 한다.
-
이때 사용하는 것이 Shard Key
- Hash Sharding
-
샤드 수 만큼 Hash함수를 사용해 저장 ( 매우 간단 )
-
DB가 추가되면 Hash함수가 변경되어야 하므로
확장성이 낮다.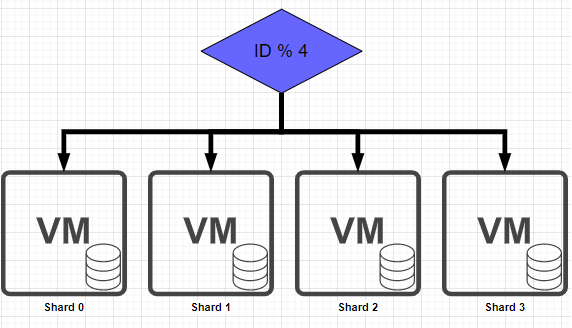
-
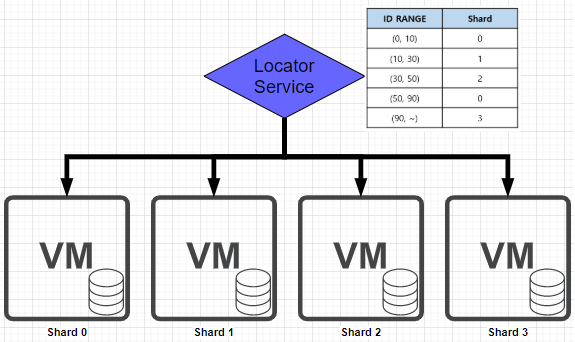
- Dynamic Sharding
-
Locator Service 를 사용해 테이블의 데이터를 기준으로 샤드를 나눔.
-
Hash Sharding과 달리 키만 추가하면 된다.
-
Locator Service가 단일 장애 지점으로 장애 발생 시 나머지 샤드에도 문제가 생김
-
- Hash Sharding
파티셔닝과의 차이점
- 샤딩은 테이블에 있는 데이터를 쪼개서 저장
- 파티셔닝은 모든 데이터를 동일한 서버에 저장
상황에 따른 선택
레플리케이션 : 가용성과 내결함성을 강조, 읽기 작업을 분산하고 장애 복구를 용이하게 한다.
- 내결함성 : 시스템의 일부가 장애가 나도 계속 서비스할 수 있는 것
샤딩 : 대량의 데이터 처리와 확장성을 강조하며, 쓰기 작업의 처리량을 향상시킨다.
