Master와 Slave 간 복제가 완료되기 전에 Master에 장애가 날 경우 어떻게 될까?
Master에 트랜잭션이 발생하면 Slave로 이동되는 Delay시간은 기본값이 0초이다. 의도적으로 이 시간을 5분으로 늘여 복제진행 전에 Master장애를 유발을 하려고 한다. slave에 아래 명령을 수행한다.
STOP SLAVE;
CHANGE MASTER TO master_delay=300;
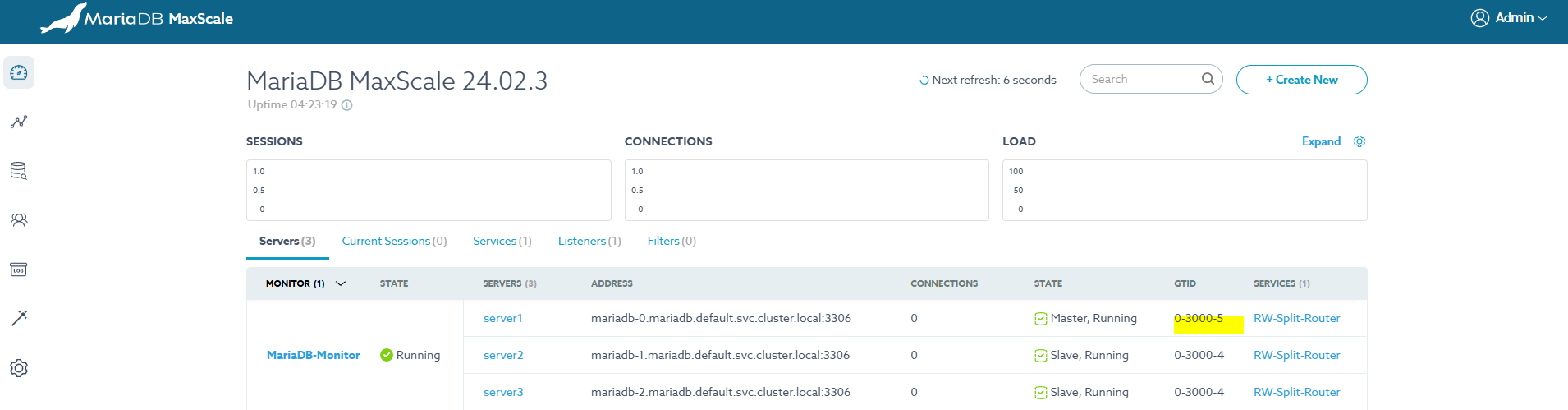
START SLAVE;slave 의 복제 지연 시간을 5분으로 두고 Master에 insert 수행 시 GTID 가 동기화 되기 전임을 확인할 수 있다. 이때 Master VM 을 종료한다.
PS C:\k8s\ubuntu> vagrant halt slave1
==> slave1: Attempting graceful shutdown of VM...일정 시간 후 slave1이 NotReady상태로 변경되었음을 확인한다.
vagrant@master:~$ k get no -owide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
master Ready control-plane 14d v1.28.15 192.168.56.10 <none> Ubuntu 20.04.6 LTS 5.4.0-189-generic containerd://1.7.23
slave1 NotReady,SchedulingDisabled <none> 14d v1.28.15 192.168.56.101 <none> Ubuntu 20.04.6 LTS 5.4.0-189-generic containerd://1.7.23
slave2 Ready,SchedulingDisabled <none> 11d v1.28.15 192.168.56.102 <none> Ubuntu 20.04.6 LTS 5.4.0-189-generic containerd://1.7.23
slave3 Ready,SchedulingDisabled <none> 14d v1.28.15 192.168.56.103 <none> Ubuntu 20.04.6 LTS 5.4.0-189-generic containerd://1.7.23
5분으로 두었던 지연 시간을 0초로 원복한다.
STOP SLAVE;
CHANGE MASTER TO master_delay=0;
START SLAVE;Master가 Slave중 하나로 변경되었음을 확인할 수 있으나, 이전 Master가 가진 최신 트랜잭션을 무시하고 있다.
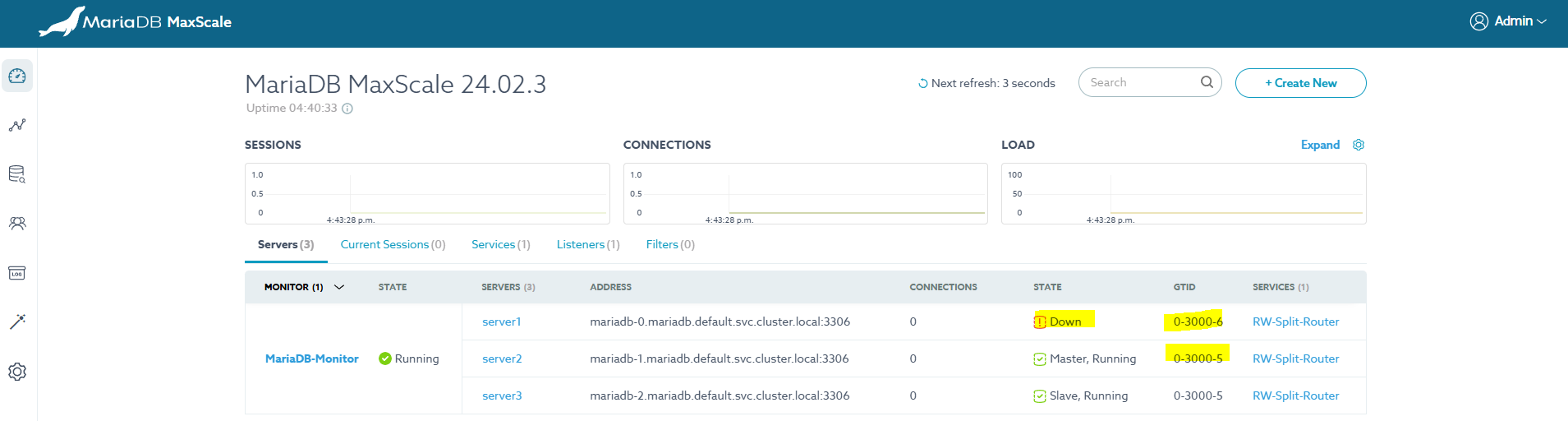
다시 이전의 Master를 복구할 경우 Master보다 더 최신 데이터를 가지고 있기때문에 정상 실행이 되지 못한다.
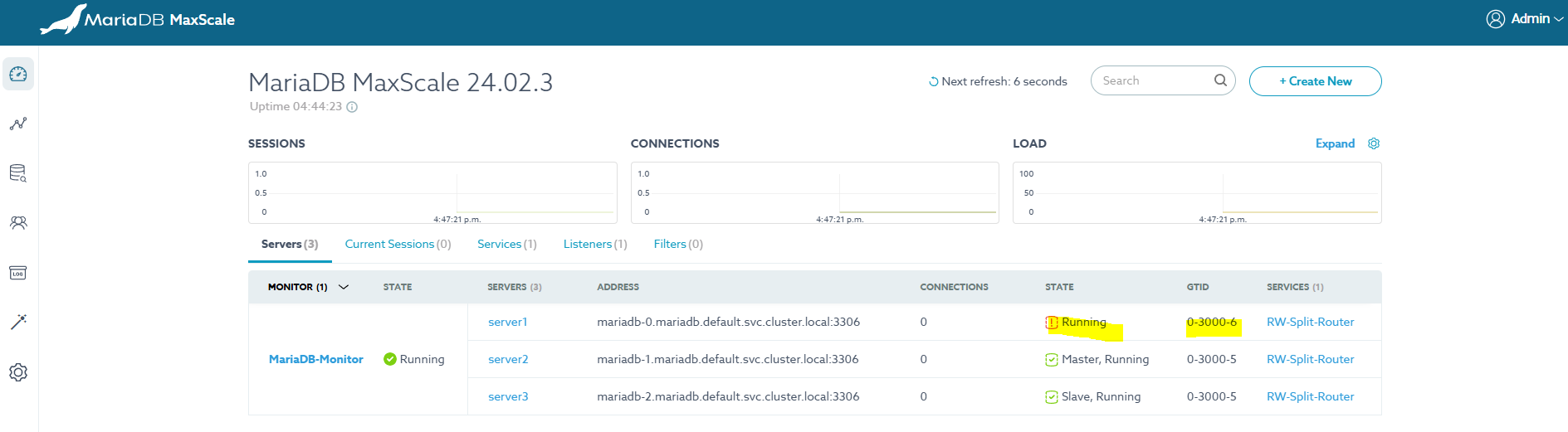
이 상태에서 이전 Master로 Switch Over 시도 시 오류 발생한다.
이어, Reset Replication 시도 시 GTID Postion이 동일하게 맞추어 졌으나 실제 데이터를 확인해 보면 여전히 Slave 가 더 많은 데이터를 가진 상태이다.
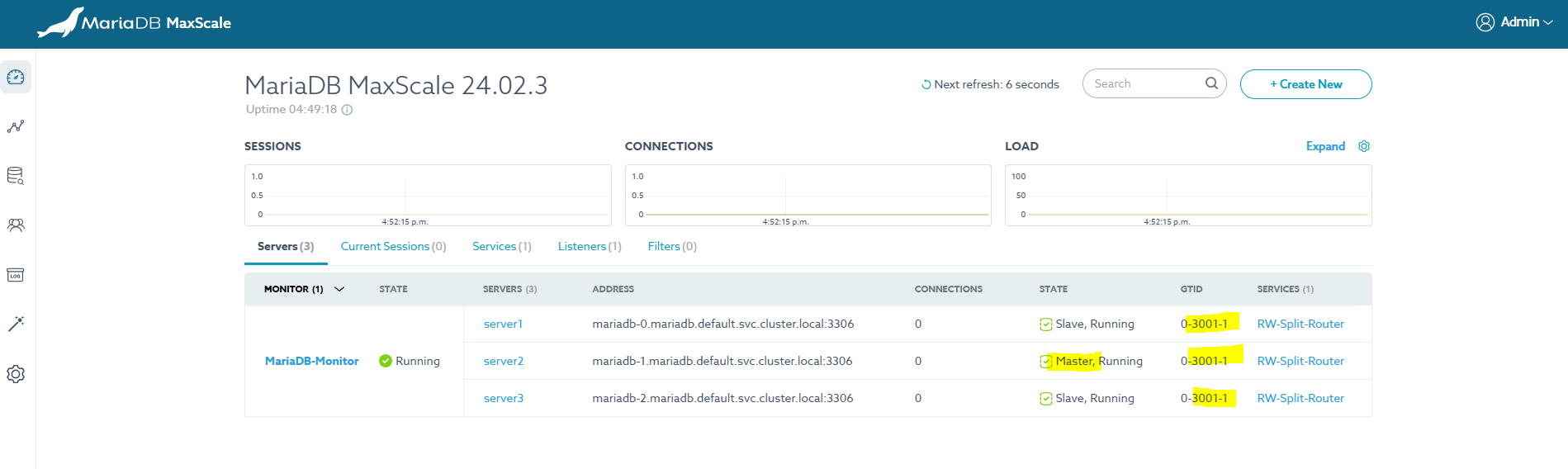
이 상태에서 Master에 쓰기 시도 시 Slave1이 이전에 가지고 있던 데이터로 인해 오류 발생한다.
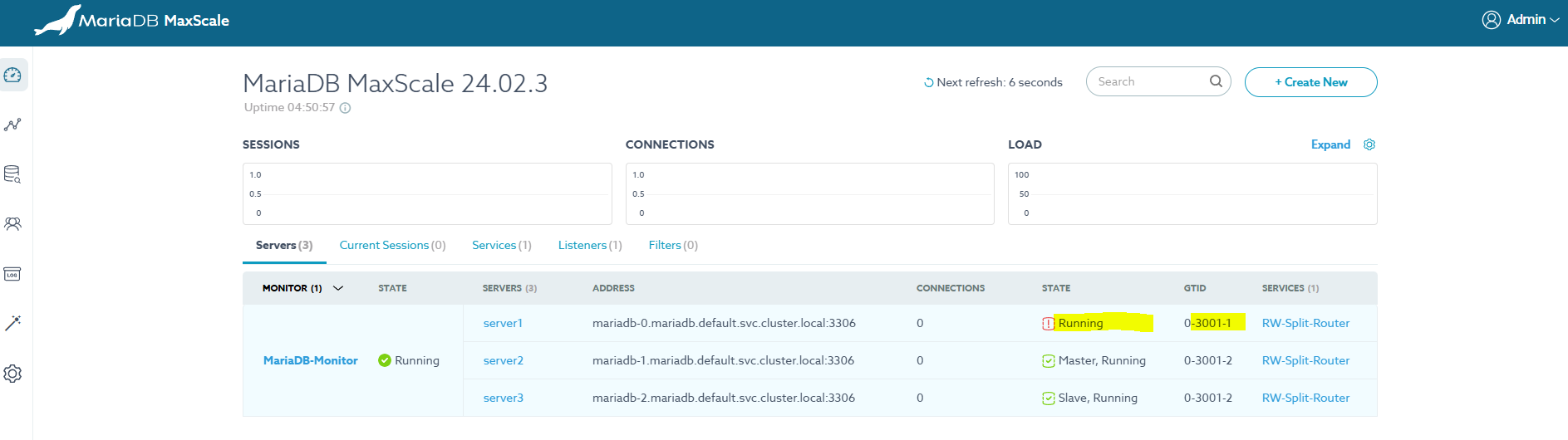
데이터 동기화 문제는 수작업으로 정리 필요하다.

khagor