코드스테이츠 AIB 부트캠프 Section 3 - Sprint 2
1.[AIB 18기] Section 3 - Sprint 2 - Note 1 - 자연어처리(NLP, Natural Language Processing)

자연어처리자연어처리를 통해 어떤 일을 할 수 있는지 알 수 있습니다.전처리(Preprocessing)토큰화(Tokenization)에 대해 설명할 수 있으며 SpaCy 라이브러리를 활용하여 토큰화를 진행할 수 있습니다.불용어(Stop words)를 제거하는 이유를 설명
2023년 4월 25일
2.[AIB 18기] Section 3 - Sprint 2 - Note 2 - 분산 표현(Distributed Representation)
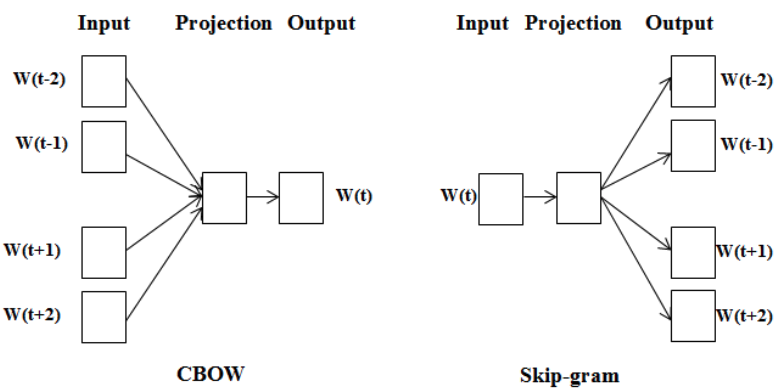
비슷한 위치에 등장하는 단어들은 비슷한 의미를 가진다 라는 분포가설을 토대로 단어 자체를 벡터화 하여 분석하는 Word2Vec 방법이 있습니다.Word2Vec은 단어를 고정 크기의 벡터로 나타내는 기법으로, 분산 표현(distributed representation)의
2023년 4월 26일
3.[AIB 18기] Section 3 - Sprint 2 - Note 3 - 언어 모델과 RNN(Recurrent Neural Network, 순환 신경망)
각 단어의 확률을 계산하는 모델전체 말뭉치 중에서 시작하는 단어의 횟수 토대로 확률을 구합니다. 다음에 어떤 문장이 왔는지도 계산하여(조건부) 확률을 구한 뒤 서로 곱하면 문장이 등장할 확률을 구할 수 있습니다.말뭉치에 없는 단어가 있다면 예측이 불가능하다는 한계점이
2023년 4월 27일
4.[AIB 18기] Section 3 - Sprint 2 - Note 4 - Transformer
RNN 기반 모델이 가진 구조적 단점은 단어가 순차적으로 들어온다는 점입니다.그렇기 때문에 처리해야 하는 시퀀스가 길수록 연산 시간이 길어지는데요.트랜스포머는 이런 문제를 해결하기 위해 등장한 모델입니다.모든 토큰을 동시에 입력받아 병렬 처리하기 때문에 GPU 연산에
2023년 4월 28일