
이 글의 목적?
혼자서 서비스를 구축해야하는 신입 백엔드 개발자는 어떤 전략을 사용해 서비스를 확장시켜야하는가? 금전적으로 여유가 있다면 단순하게 고사양의 여러 대의 서버를 두는 방법이 있지만, 회사의 지출을 줄이는 것도 개발자의 영역이기에 조금 더 효율적인 방법을 내가 참고한 레퍼런스로 정리해보자.
대규모 서비스에서 사용하는 용어
우선 내가 참고한 레퍼런스에서 나온 개념들을 정리해보자.
- Elastic : 트래픽이나 상황에 따라 서버의 추가 및 제거가 쉬워야 한다.
- Resiliency : 특정 장비의 장애 등은 자동으로 복구되어야 한다. (복구의 의미는 서버가 복구되는 개념이 아니며, 해당 장비의 장애가 다른 쪽에 영향을 주어선 안된다.)
- Scale-up : 서버의 사양을 높이는 전략이다.
- Scale-out : 서버의 수를 늘리는 전략이다.
- SPOF (Single Point Of Failure) : 장애가 발생한 지점으로 인해 서비스 전체를 마비시키는 병목지점을 의미한다. 즉, 동작하지 않으면 전체 시스템이 중단되는 요소를 의미한다.
- Sharding : DB를 조각으로 나누는 것을 의미하며, 나누어진 블록들을 Shard라고 한다. 나누어진 데이터를 Logical Shards라고 부르며, 이렇게 나눠진 데이터를 Physical Shards에 뿌려진다.
SPOF 해결책?
레퍼런스에서 SPOF를 해결하기 위한 구조는 간단하다.
여러 대의 API 서버에서 여러 클라이언트의 요청을 받고, 마스터 DB와 그를 Replicate한 슬레이브 DB에서 각 API 서버에 필요한 데이터를 처리하는 구조다. 그리고 추가적으로 클라이언트의 요청이 API 서버에 도달하기 전에 로드 밸런서로 트래픽을 제어하여 각 API 서버에 전달하는 구조를 이야기했다.
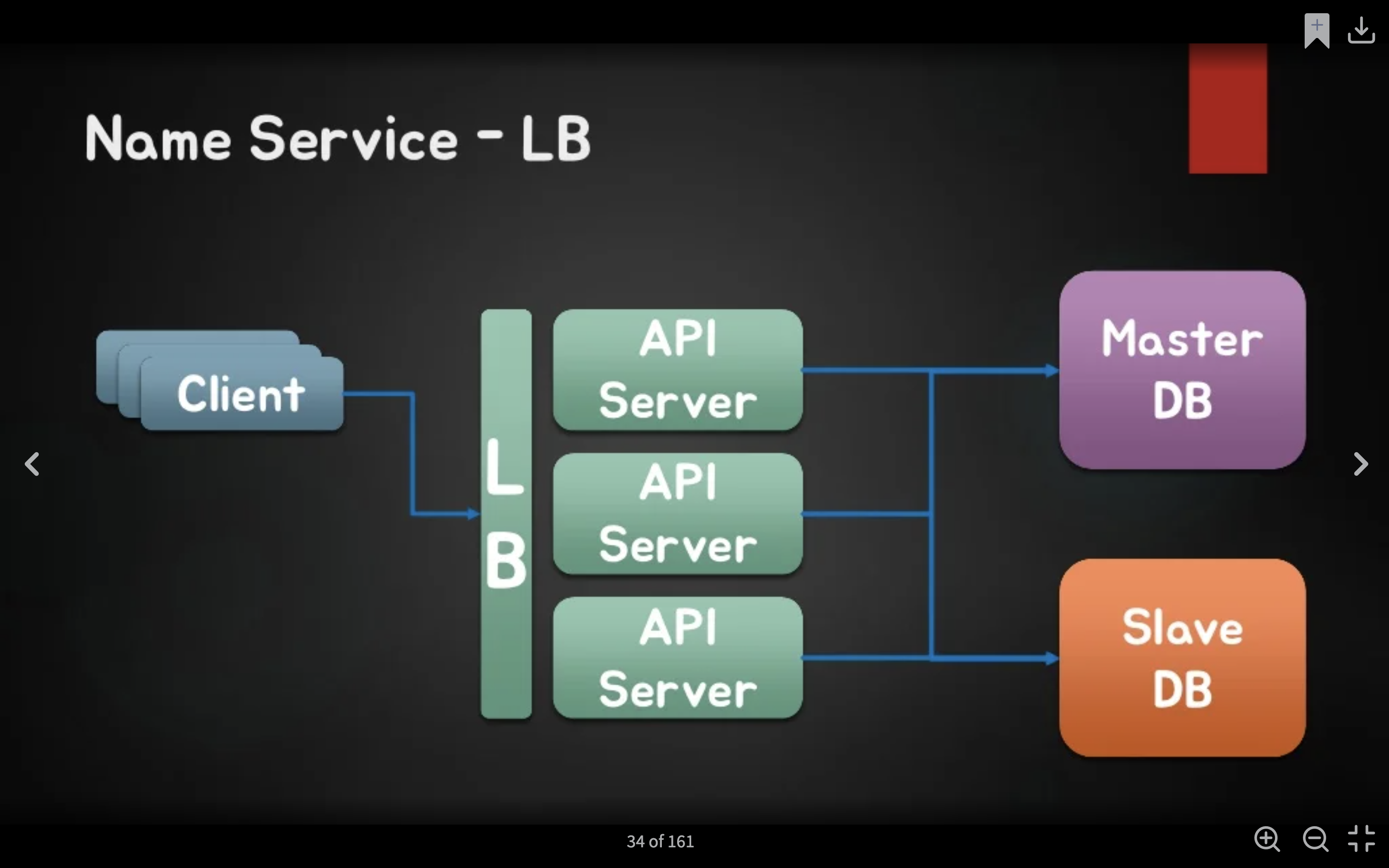
중간에 DNS 쿼리를 질의한 결과에 대한 내용도 언급되어있는데, 이는 실제로 네이버나 구글에 DNS 쿼리를 질의하면 여러 개의 IP 주소가 보이는 것 처럼 여러 개의 API 서버가 구축되어있다는 사실을 보여주려는 것 같다. 🙂
확장해야하는 지점을 생각해보자
위에서 언급한 구조를 살펴보면 API 서버와 DB 서버 - 두 가지 영역에서 확장되는 것을 알 수 있다.
API 서버의 확장은 레퍼런스에 적힌 내용을 간략하게 요약하자면 - 이미지와 같은 정적 파일을 처리하거나 CPU나 다른 작업이 많이 필요한 경우에 부하가 되기에 확장이 필요하다. 반대로 DB 서버의 확장은 수 많은 데이터를 저장하고 조회하는 것 자체에서 부하가 발생하기에 확장이 필요한 영역이다.
그럼 어떻게 확장해야할까?
Stateless 하게 설계하자
Stateful하다는 의미는 쉽게 말해 - 우리가 흔히 아는 쿠키 혹은 세션 정보를 가지고 있다는 것이다. 즉, 클라이언트의 상태를 가지고 있다는 의미다. Stateful도 물론 장점을 가지고 있으나, 서버의 확장에 있어서 생각해야하는 부분(서버가 중간에 변경될 경우, 클라이언트의 상태에 대한 공유 등)들이 많기 때문에 Stateless하게 설계하는 것을 권장하는 편이다.
그렇다고 해서 무조건 Stateless한 것이 좋은 것만은 아니다. 단점들에 대해서는 쉽게 구글링으로 찾을 수 있으니 생략하자.
내가 참고한 레퍼런스에 따르면, API 서버를 Stateless하게 하자는 의견이지만, 상황에 따라서 알맞게 사용하는게 가장 좋은 정답인 것 같다.
DB 읽기 분산을 하자
DB 서버의 부하는 대부분 쓰기보다 조회에서 많이 발생한다. 따라서 마스터 DB에서는 오로지 쓰기만을하고 그 외의 모든 읽기는 슬레이브 DB로 넘기자는거다. (그렇다고 읽기용 슬레이브 DB를 늘린다고 해서 성능이 항상 향상되는 것은 아니니 무분별한 추가는 주의하도록 하자!)

이러한 기술은 Query Off Loading이라고 하는데, 이 기술을 적용하는 것도 꽤나 까다로운 작업이다. 일반적으로 애플리케이션 서버에서는 커넥션을 커넥션 풀을 이용하여 관리한다. 그리고 읽기 DB의 경우 N개의 슬레이브 DB로부터 읽기 때문에 애플리케이션이 N개의 슬레이브 DB에 대한 요청을 로드 밸런싱해야한다. 생각만해도 복잡하다..
또한 슬레이브 DB에서 장애가 발생했을 경우 다른 슬레이브 DB에 접근할 수 있도록 고가용성을 제공해야하는데, 이는 로드 밸런싱 기능이 있는 커넥션 풀을 이용하거나 JDBC 드라이버와 같이 DBMS용 드라이버 자체의 로드 밸런싱을 이용하여 해결할 수 있다. 이 마저도 구성해야 한다.. 😱
더 들어가자면, 각각의 슬레이브 DB는 마스터 DB와의 복제(동기화)가 이루어져야한다. 그리고 이러한 작업은 마스터 DB에 부담이 되기 때문에 스테이징 DB를 두어 성능 저하를 방지시킨다고 한다. 스테이징 DB를 이용한 복제 작업은 CDC(Change Data Capture) 기술을 이용하여 해결한다고 한다. 애플리케이션 단 말고도 생각해야하는 부분이 정말 많다... 😭
DB 데이터 분산처리를 하자
DB 파티셔닝의 경우 Vertical Partitioning과 Horizontal Sharding이 있다.
Vertical Partitioning은 연속된 데이터에 대해서 범위별로 데이터를 나누는 방법이다.

Horizontal Sharding은 연속된 키가 아닌 종류에 따라서 데이터를 수평적으로 분리하는 방법이다.

하지만 이러한 기술에도 고려해야하는 부분이 있다. Vertical Partitioning의 예시로, '나이'라는 기준으로 10대, 20대, 30대, 40대 등으로 데이터를 분산 저장하게 될 경우를 생각해보자. 만약 서비스가 젊은이들이 주 고객층이라면 아마 10대, 20대에 데이터가 몰리는 현상이 일어날 것이다. 어떻게 해결을 해야할까?
정말 단순하다. 10대와 20대에 더 좋은 CPU와 메모리를 가지는 서버를 배치하는 방법이 있다. 하지만 이 방법은 10대와 20대에 데이터 몰림 현상이 일어날 것이라는 예측이 가능할 경우에 적용이 가능하다. 반대로 한 테이블의 Row를 나누기 때문에 예측이 불가능한 Horizontal Sharding 경우에는 어떻게 해야할까?
이 경우에는 특정 키를 두어서 해결이 가능하다. 가정을 해보자. 하나의 서버에 최대 5개의 데이터만 저장이 가능할 때, 6개의 데이터가 있을 경우 어떻게 나눠야 데이터 분산이 잘 되었다고 할까? 이 후 두 개의 추가적인 데이터가 들어왔을 경우에는 어떻게 처리를 해야할까?
내가 참고한 레퍼런스에서는 Horizontal Sharding에서 사용할 수 있는 방법으로 총 4가지를 기술했다.
Range Sharding
Range Sharding은 특정 범위 대역으로 나누는 방법이다. 쉽게 말하자면, PK의 범위를 기준으로 DB를 특정하는 방식이다. Modular Sharding에 비해 증설에 비용이 들지는 않지만 일부 DB에 데이터가 몰릴 수 있다는 단점을 가지고 있다.
Range Sharding을 구현하는 방법에 대해서는 첨부해놓은 사이트에 자세히 기술되어있다. 나중에 직접 구현해보고 다시 정리도 해보자. 😭
Modular Sharding
Modular Sharding은 PK를 모듈러 연산한 결과로 DB를 특정하는 방법이다. Range Sharding 보다 데이터가 균일하게 분산이되지만, DB를 추가 증설하는 경우에는 이미 적재된 데이터의 재정렬 같은 귀찮은 작업이 필요하다. Modular Sharding은 일정 수준에서 유지될 것으로 예상되는 데이터의 성격을 가진 곳에 적용할 때 어울리는 방식이라고 한다.
레퍼런스의 Modular Sharding의 예시에서는 서버의 수로 나눈 나머지 값으로 처리했다. 그리고 2개의 서버로 운영되다 한 대가 더 추가되었을 때 데이터의 이동이 심해지는 문제에 대해서도 언급을 했는데, 이는 서버를 한 대만 추가되지 않고 두 대씩 - 즉, 추가되는 서버의 수를 두 배로 늘려 해결을 했다.
즉, 서버가 추가가 되거나 제거가 되어지는 부분에서 Range Sharding과 처럼 균일하게 데이터가 분산되지 않고 한쪽에만 몰리는 현상이 발생할 수 있다는 점이다.


Indexed / Complexed
Indexed는 특정 데이터의 위치를 가르키는 서버를 별도로 구축하는 방법이다. 그리고 추가적으로 Indexed 보다 더 복잡한 방법으로 Complexed에 대해서 언급되어있는데, 이 방법은 복잡한 만큼 조금 더 연구가 필요해보인다.


Consistent Hashing
Consistent Hashing은 노드나 서버의 수에 독립적으로 동작한다. 즉, Modular Sharding에 비해 비교적으로 서버의 추가나 제거로부터 자유롭다는 의미다. 내가 찾은 블로그에서 작성된 동작 과정을 가져와보자.
먼저 서버의 위치를 찾기 위해 서버의 IP 주소나 서버 번호와 같은 서버의 고유번호에 해시를 취한 후 해시 함수를 사용하여 위치를 계산한다. 그리고 계산된 위치에 링의 위에 서버를 배치한다.
키와 동일한 해시값을 가지는 서버에 키를 매핑하고, 키 해시값이 어떤 서버에도 일치하지 않는 경우에는 시계 방향으로 가장 가까운 서버에 매핑시킨다.
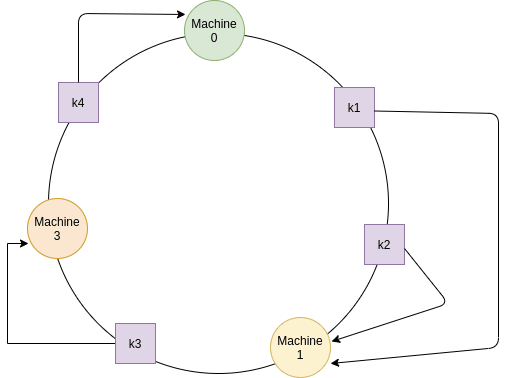
서버를 새로 추가했을 경우를 살펴보자. 서버를 새로 추가했을 경우에는 Modular 처럼 데이터를 재정렬할 필요없이 추가한 서버와 바로 직전의 서버 사이에 있는 데이터만 재할당해주기만 하면 된다.
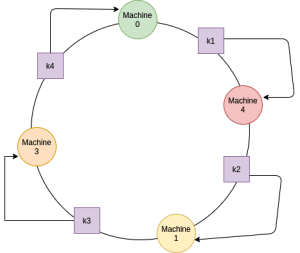
서버를 제거했을 경우도 간단하다. 그 내부에 저장된 데이터는 시계방향으로 인접한 서버에 저장된 키만 다시 할당해주기만 하면 된다.
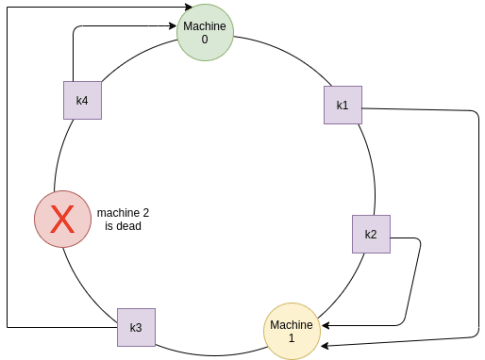
하지만 이 방법에도 단일 서버 근처에 해시되었을 때 비균일 분포의 문제가 존재한다.
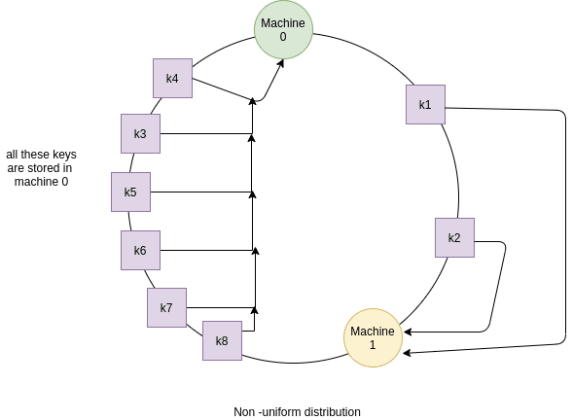
이러한 비균일 분포는 복제본을 여러대 두어 해결할 수 있다.
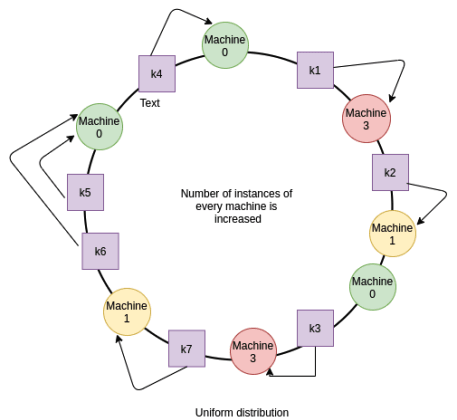
추가적으로 Consistent Hashing 방법을 개선한 Jump Consistent Hashing 방법이 있는데, 지금은 너무 깊게 들어가지 말자.
그럼 어떻게 Sharding을 구현할까?
Sharding은 DBMS에서 지원하는 방법으로 구현하거나, OR Mapper와 같은 DB 접근용 프레임워크에서 제공하는 방법으로 구현하거나, 애플리케이션 자체에서 직접 코드로 구현할 수 있다.
DBMS에서 지원하는 방법은 Microsoft SQL Server Azure의 Federation model이나 RDBMS는 아니지만 NoSQL 중 MongoDB의 경우 Sharding을 DB단에서 지원한다고 한다.
프레임워크단에서의 자바 Hibernate는 Hibernate Shard라는 기능을 통해서 Sharding을 지원하고, 프로그래밍 언어인 Grail에서는 자체 프레임워크에서 Sharding 플러그인을 제공한다고 한다.
그 외
그 외에도 내가 참고한 레퍼런스에서는 Sharding할 때의 키의 설계 방법과 클라이언트 사이드, 서버 사이드, Health 체크, ZooKeeper와 같은 분산 Coordination 등에 대해서도 이야기했다. 이러한 내용들은 위에서 정리한 이론적인 내용을 토대로 구현할 때 발생할 수 있는 문제에 대한 해결책이거나 필요한 내용으로 보이므로 나중에 직접 구현해보면서 천천히 정리해보자. 일단 이번 글에서 다룬 내용부터 내 것으로 만들자.
이 글의 레퍼런스
Modular Sharding, Range Sharding
Consistent Hashing
