최근에 한 시니어 분이 추천해주셔서 오늘부터 새롭게 보기 시작한 유튜브 시리즈입니다.
aws 채널에서 하는 This is My Architecture라는 시리즈인데 aws의 파트너나 고객들의 클라우드 아키텍쳐를 소개하는 유익한 컨텐츠입니다. 500개 정도의 영상이 있는데 한국어 컨텐츠도 종종 있고, 전세계 고객 기업들의 사례들을 볼 수 있습니다. 차근차근 몇개씩 보고 요약하여 내용을 남겨보려 합니다 🤭
먼저 이 포스팅에서는 'recommendation'와 'game service'를 키워드로 '삼성전자 Game Launcer'와 'Voodoo'의 사례를 살펴보겠습니다 ✨
1. 삼성전자 Game Launcher 서비스
고객 서비스
Game Launcher 서비스는 삼성 갤럭시 스마트폰에서 설치된 게임을 한 곳에 모여서 보여주고 사용자들에게 보다 나은 게임 플레이 환경을 제공하기 위한 서비스로, 사용자의 게임 실행 기록을 통해서 게임 플레이 시간을 통계를 내서 게임에 대한 랭킹을 제공하고 있으며, 게임과 관련된 동영상 컨텐츠를 추천해주는 서비스입니다.
Game Launcher에서는 사용자의 게임 실행 기록을 수집하고 있는데, 이를 바탕으로 랭킹을 만들고 이 랭킹에서 상위 랭크된 게임들에 대해서 동영상을 수집하고 있다고 합니다.
Game Launcher 4.0으로 넘어오면서 기존에는 게임 관련 동영상을 단순히 게임 제목으로 검색해서 제공했다고 하면, 4.0이후 부터는 게임 관련 영상을 수집을 하고 게임과의 관련성을 파악한 후에 관련성이 높은 영상을 추천해주고 있습니다.
챌린지와 aws 사용 계기
머신러닝에 대한 경험이 부족했고, 개발 기간이 짧은 편이기 때문에 완전관리형 서비스인 Amazon의 Comprehend를 사용하게 되었다고 합니다. 우선은 완전관리형 서비스이기 때문에 개발 기간이 많이 단축되었고, 기존의 단순히 게임 제목으로 검색하여 동영상을 추천해주었을 때와 달리, 게임과 더 관련성이 높은 동영상을 제공할 수 있게 되었다고 합니다. Comprehend의 다양한 기능 중에 Custom Classification을 사용하였습니다.
Amazon Comprehend란? 기계 학습을 사용하여 텍스트 안에 있는 통찰력과 관계를 찾아내는 자연어 처리(NLP) 서비스입니다. 기계 학습을 통해 비정형 데이터 속의 통찰과 관계를 밝혀낼 수 있도록 도와줍니다. 이 서비스는 텍스트의 언어를 식별하고 핵심 문구, 장소, 사람, 브랜드 또는 이벤트를 추출합니다. 또한 토큰화 및 Parts of Speech(PoS)를 사용하여 텍스트가 얼마나 긍정적인지 또는 부정적인지를 이해하며 텍스트 파일 모음을 주제별로 자동으로 정리합니다. Amazon Comprehend의 AutoML 기능으로 해당 조직의 필요에 꼭 맞게 조정된 사용자 지정 개체 세트나 텍스트 분류 모델을 빌드할 수도 있습니다.
아키텍쳐 다이어그램
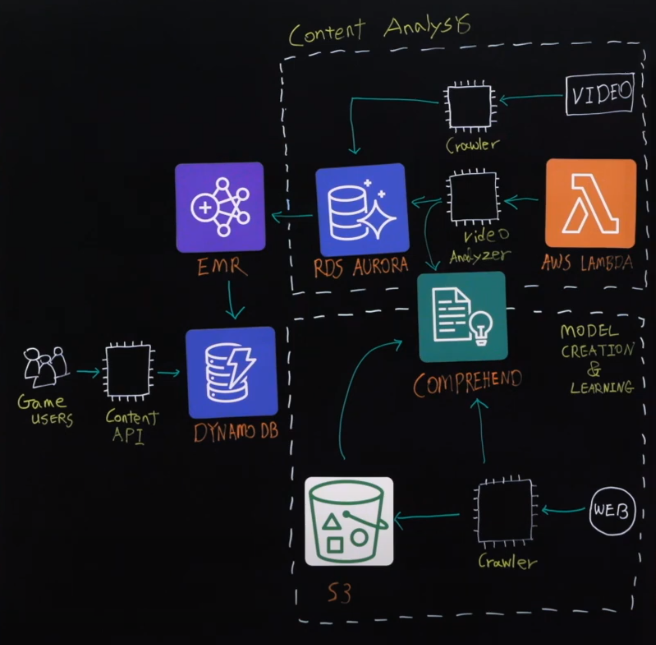
사용한 아키텍쳐 다이어그램은 다음과 같습니다.
아키텍쳐 설명
우선, 크게 두가지로 분류되는데 아래 부분은 머신러닝을 하기 위해 제일 기본이 되는 모델을 생성하는 부분이고, 윗 부분은 게임과 관련된 영상을 수집하고, 수집된 영상이 얼마나 게임과 연관성이 높은지 판단하게 되는 컨텐츠 분석부분입니다.
- 모델을 생성하는 부분을 먼저 설명드리면, 게임과 관련된 텍스트를 크롤러라는 모듈이 웹에서 수집합니다. 그 이후 S3에 저장을 하게 되고, 크롤러가 COMPREHEND에 모델 생성을 요청하게 됩니다. 요청할 때 S3에 있는 학습데이터를 COMPREHEND에 input으로 제공하게 됩니다. 몇시간 후에 COMPREHEND가 모델을 생성하고 결과를 제공합니다.
-
이후, 수집된 동영상을 분석하는 단계에서는 Lambda가 주기적으로 video analyzer라는 모듈을 호출하고 video analyzer는 수집한 동영상에서 제목과 같은 텍스트를 COMPREHEND에 분석을 요청합니다. 분석된 결과가 COMPREHEND에서 나오고 동영상이 어떤 게임과 어떤 스코어 정도로 매칭되는지의 결과도 얻을 수 있습니다.
-
얻은 결과를 AURORA DB에 저장하게 되고, AURORA DB에는 어떤 게임과 얼마의 스코어로 매칭되는지의 결과가 저장되게 되고 EMR을 통해 분석하여 그 결과를 DYNAMO DB에 저장하게 됩니다. DYNAMO DB에서는 특정 스코어가 넘는 동영상 컨텐츠에 대해서만 저장을 하고 있습니다. 이렇게, 어떤 영상을 game launcher app에서 추천해주어야 하는지 확인할 수 있게 됩니다.
2. Voodoo
(이 영상은 프랑스어와 영어자막으로만 이루어져 있어서 한국어로 보고 싶은 분들께 이 블로그 포스팅이 도움이 되면 좋을 것 같습니다)
고객 서비스
Voodoo는 모바일 게임을 제작하는 회사입니다. 현재 전세계를 이끄는 모바일 게임 공급자라고 합니다. 또한, 앱스토어에서 구글을 잇는 두번째로 다운로드수가 가장 많은 회사라고 합니다.
서비스의 챌린지
Voodoo의 주요 챌린지는 게임에서 사용자가 그들이 가져오는 것보다 Voodoo에게 더 적은 비용을 지불하여, Voodoo의 사용자들이 이를 통해 수익화하고 그것들을 획득하는 것이였습니다. 결국 사용자들에게 이익을 주고 돈을 벌 수 있도록 하는 것입니다.
이 아키텍쳐는 cross promotion의 최적화입니다. 그래서 이것은 Voodoo games 안에서 Voodoo 앱들의 배포입니다. 이것은 Voodoo가 새로운 게임을 출시할 때 가장 적은 비용으로 고객들을 지킬 수 있도록 도와줍니다. 그리고 Voodoo의 앱을 설치할 기회를 극대화 하기 위해 노력합니다.
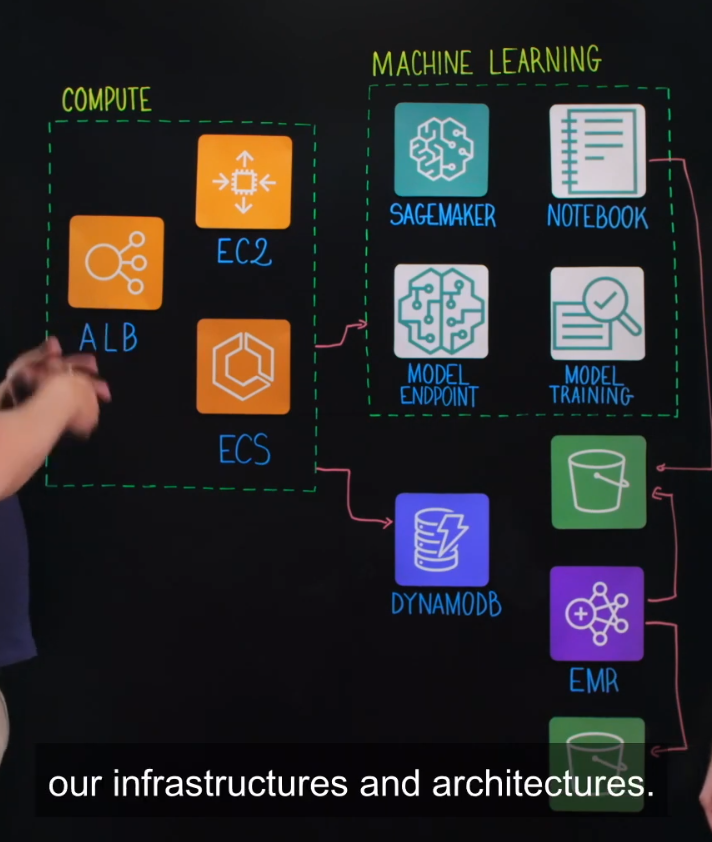
아키텍쳐 다이어그램
아키텍쳐 설명
-
사용자가 앱에 도달하면 앱은 Voodoo와 일하는 모든 에드 네트워크로부터 광고를 요구할 것입니다. 사용자 덕분에 ALB와 ECS가 있는 Auto Scaling Group이 있는 매우 고전적인 ECS 스택에서 당사에 대한 요청을 처리할 수 있습니다. 그런 다음 이 앱은 여러 비즈니스 필터를 수행한 후 DynamoDB를 호출하여 머신 러닝 모델을 호출하는 데 필요한 모든 기능들을 갖춘 모든 정보를 얻습니다.
-
그런 다음 SageMaker Endpoint에 호출하여 이 사용자에 대한 모든 예측들을 얻을 수 있습니다. 각 예측은 이러한 광고들을 표시함으로써 이 사용자가 일부 앱들을 설치할 확률을 나타냅니다. 그리고 설치 가능성이 가장 높으면, 이 광고를 사용자에게 표시합니다.
-
우측 하단 두개의 S3 버킷은 머신러닝을 위한 정보의 준비입니다. 하단의 버킷에는 Data Lake가 있습니다. 그리고 우리는 Data Lake에서 정보를 얻고, 결합하고, 여러 데이터 소스를 병합하는 EMR을 실행할 것입니다. 그리고 데이터 세트를 생성하여 다른 S3 버킷에 쓸 것입니다.
Data Lake: 정형/비정형 데이터 종류와 모델에 상관없이 모든 유형의 데이터를 저장할 수 있는 중앙 집중식 저장소
-
이 s3 버킷은 데이터 사이언티스트가 모델을 테스트하고 모델의 오프라인 예측을 관찰할 수 있도록 하기 위해서Jupyter Notebooks을 사용하여 사용할 것입니다. 그런 다음 SageMaker로 보냅니다. 이러한 예측이 충분하다면, 모델을 교육하고 새로운 엔드포인트를 배치할 수 있을 것입니다. 그런 다음 해당 엔드포인트가 트래픽의 일부를 차지하게 됩니다. 결과적으로, 해당 엔드포인트에 할당하려는 트래픽의 양을 선택할 수 있습니다.
-
처음에는 온라인 성능만 검증하기 위해 너무 많은 트래픽을 할당하지 않으려고 노력합니다. 그리고 온라인 성능이 검증되면, 점차적으로 이 엔드포인트가 할당받는 트래픽을 증가시킵니다.
-
꾸준히 증가하고 있지만, 현재로써는 하루에 약 1억개의 모델 호출이 있을 것입니다. 그리고 각 모델 호출은 약 10개, 심지어는 15개의 예측을 유발합니다. 따라서 하루에 약 10억개의 예측이 있습니다. 왜냐하면 엔드포인트에 요청을 한번 하려면, 우리는 각 광고 캠페인에 대해 한 가지 예측을 해야하기 때문입니다.
-
SageMaker를 사용하게 된 주요 장점은 확장성과 더불어 데이터 사이언티스트들을 완전히 자율적으로 만들어주는 것입니다. 즉, 모델을 교육하고, 데이터 레이크에서 온라인 데이터를 검색하고, 모델을 배포하기 위해 데이터 사이언티스트들은 완전히 자율적입니다. 데이터 엔지니어도, DevOps도 필요하지 않게 됩니다. 따라서 DevOps는 아키텍처와 인프라를 산업화하는 데 집중할 수 있고, 데이터 엔지니어들은 데이터셋 생성을 최적화하는 데 집중할 수 있습니다.
