오늘은 'Huge amount of Data'를 키워드로 'Nielsen'의 사례와 'Alert Logic'의 사례를 살펴보도록 하겠습니다! ✨
1. Nielsen
소개
Nielsen은 데이터 관리 플랫폼으로 캠페인에 사용할 수 있는 마케팅 세분화 데이터를 준비합니다. 기본적으로 시스템의 다른 부분에서 모든 데이터를 생성하고나서 DataOut이라고 불리는 시스템이 파일을 받아 그들을 처리하고 파트너인 AD Network에 파일을 업로드합니다.
아키텍쳐 다이어그램
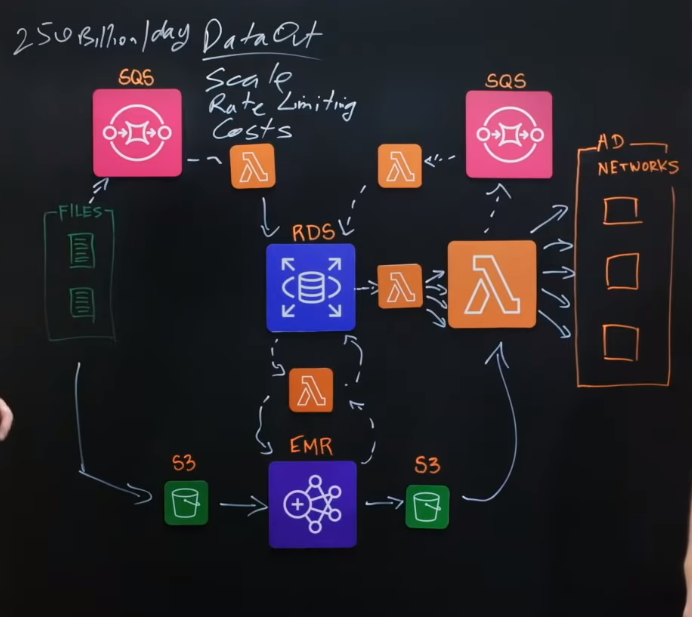
아키텍쳐 설명
-
가장 먼저 말씀드릴 것은 이 시스템은 정말 많은 양의 데이터를 가동합니다. 하루에 2500억개의 이벤트를 처리합니다. 이러한 이벤트들이 파일 형태로 오며 각 파일은 세분화 데이터인 많은 이벤트들을 가지고 있습니다. 이것들은 처리되어 AD Network로 보내집니다.
-
그 파일들은 거의 시스템에 들어와 S3 버킷에 쓰여집니다. 그들은 Spark EMR 클러스터를 통해 변환과 같은 프로세싱과 포맷팅을 받게되고 다른 S3 버킷에 다시 쓰여집니다.
-
그 이후 LAMBDA 함수로 가서 마지막 포맷팅과 같은 프로세싱을 하게 되고 AD platform으로 보내집니다. LAMBDA 함수는 모든 플랫폼들에 업로드하는 실질적으로 마지막 작업을 하게됩니다.
-
아키텍쳐 다이어그램의 위로 올라가면 파일과 어떻게 그들을 관리하는지에 대한 모든 데이터인 추가 데이터 레이어가 있습니다. 따라서 이러한 정보는 files -> SQS -> LAMBDA 를 통해 Postgres RDS 데이터베이스에 쓰여집니다. 이 정보들을 읽고 어떤 파일들을 어떻게 작업할지에 관한 결정을 내리는 작은 작업관리자인 LAMBDA가 아래에 하나더 있으며, 이것을 Spark 클러스터에 보내서 다시 RDS 데이터베이스로 쓰게 됩니다. 모든 메타데이터는 기본적으로 RDS에 저장되고, 계속 플로우로 업데이트를 하는 것입니다.
-
두번째 작업관리자인 LAMBDA가 있습니다. 이는 프로세스 파일들에 대한 정보를 읽으며, 펼쳐지는(fanout) 아키텍쳐와 같이 생겨서 아주 많은 LAMBDA들을 호출합니다. 그리고 이것을 AD Network에 업로드합니다. 전체적으로 데이터를 업로드하는 100개가 넘는 네트워크들이 있습니다. 이러한 LAMBDA가 끝나면, SQS 대기열을 통해 다시 업데이트되고, SQS는 RDS 데이터베이스로 다시 업데이트됩니다.
챌린지
-
이 시스템에 대해 흥미로운 3가지는 1. 규모 2. 속도 제한 3. 비용 입니다. 먼저 규모에 대해 말해보자면, 최고의 날의 경우에는 55TB 의 데이터가 있습니다. 그리고 그날에는 1700만개의 파일이 있고, 약 3000 만개의 LAMBDA 호출이 있습니다. 이것은 단 하루동안의 일입니다. 그리고 이 아키텍쳐의 시스템은 어떠한 문제없이 이를 관리합니다. 몇분안에 3000개의 LAMBDA가 동시에 작동하기도 합니다.
-
일반적인 날의 경우 가장 낮은 시간에는 1TB의 데이터를 가지고 있습니다. 하지만 피크 시간대에는 6TB 정도가 보통입니다. 따라서 시스템은 들어오는 데이터에 따라 위아래로 조정되어야만 하고, 하루 동안에도 끊임없이 위아래로 확장이 일어나야 합니다. 하지만 서버리스 LAMBDA 아키텍쳐를 사용하기 때문에 시스템이 스스로 작동하고 이러한 확장에 대해서 별도의 작업을 하지 않아도 됩니다.
-
원래에는 속도 제한에 대해서는 문제라고 생각하지 않았습니다. 하지만 파트너사들로부터 Nielsen이 서버를 죽이고 있다는 메일들을 받게 되었고, Nielsen은 자동으로 들어오는 모든 데이터를 처리할 수 있지만, 모든 회사가 Nielsen과 같이 동작하지 않기 때문에 많은 데이터를 보내는 시스템 중 일부는 그들에 대해 DDoS 공격을 하는 것과 같은 것이었습니다. 따라서 속도 제한 메커니즘을 도입했습니다. 작동 방식은 이 작업관리자 LAMBDA의 기능을 활용했고 LAMBDA는 파일 크기에 따라 몇가지 결정을 내립니다. 즉, 원하는 모든 것에 대해 거의 속도 제한을 할 수 있습니다. 예를 들어 초당 메가비트, 열린 http 연결 수, 요청 수 등을 제한 할 수 있습니다. 이는 네트워크별로 구성되어 있어서 특정 네트워크를 제한할 수도 있습니다. 예를 들어 초당 250 메가비트로 제한했다면, 그보다 많은 데이터들은 큐에 남아서 기다릴 것입니다.
-
또 다른 흥미로운 점은 자체 DDoS 공격이 있다는 것입니다. 그래서 LAMBDA의 호출수가 증가함에 따라 기존에는Postgres RDS 데이터베이스에 다시 쓰고 있었지만 데이터베이스를 열고 시작할 수 있는 연결 수의 제한에 도달을 했고, Nielsen은 모든 LAMBDA가 대기열에 다시 보고할 수 있는 다른 SQS를 버퍼로 도입했습니다. 또한, 이벤트 묶음으로 수집하여 작성하는 LAMBDA 한 개가 있습니다.
-
다음은 비용에 관한 이야기입니다. Nielsen이 시스템을 구축하면서 가장 걱정했던 부분입니다. 오늘날의 시스템 비용은 하루에 약 $1,000입니다. 연간 약 $300,000입니다. 시스템을 구축하면서 Nielsen은 비용을 통제하고 싶었습니다. 따라서 비용을 측정하기 시작했고 현재는 10억개의 이벤트당 77달러에서 약 42달러까지 줄였으며 여전히 줄여가고 있습니다. 이렇게 77달러에서 42달러로 줄이게 된 것은 LAMBDA는 코드를 개선하면 즉시 비용 절감으로 이어진다는 것입니다. 비용 절감을 위해 몇가지 계획을 세웠었는데, 그중 하나는 LAMBDA 함수 실행 시간 및 메모리 사용량, 메모리 공간을 줄이면 비용이 절약 된다는 것입니다. LAMBDA에 대한 다양한 부하를 시뮬레이션할 수 있는 다른 메모리 크기의 시뮬레이터를 작성하여 실험하고 조합했고 최적화 위치를 발견한 것입니다. 그런 다음 코드를 개선하여 그 스팟에서 정확히 작동하도록 했습니다.
-
또 다른 계획은 http연결 수 였는데, 더 많은 연결을 보내면 모두 완료되기를 기다리고 있는데 이는 시간은 더 오래걸릴 수 있지만 총 비용은 더 낮을 수 있다는 것입니다.
2. Alert Logic
소개
Alert Logic은 4,000명 이상의 고객에게 연중무휴서비스를 제공하는 보안 회사입니다. 이를 통해 약 25 페타바이트의 데이터를 처리하고 그 외에도 고객과 보안엔지니어 모두에게 검색 기능을 제공합니다. 오늘 설명드릴 아키텍쳐는 검색에 사용되는 시스템입니다.
아키텍쳐 다이어그램
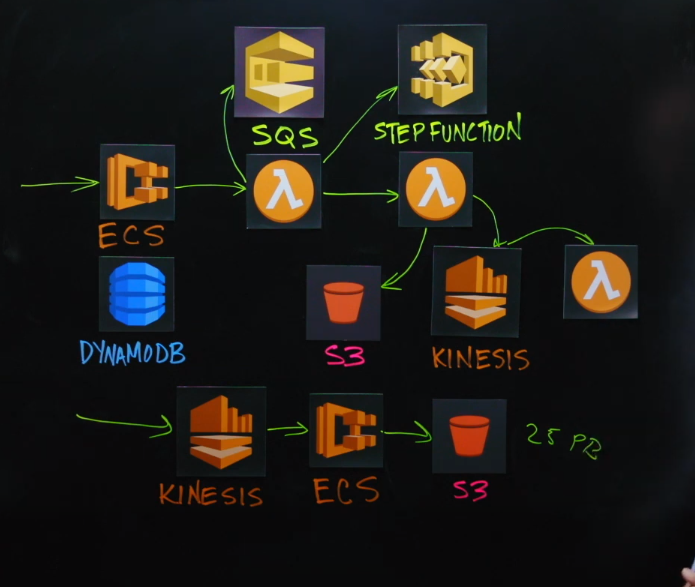
아키텍쳐 설명
-
시스템은 2개의 파트로 이루어져 있습니다. 하나는 사소한 일일 ingestion 파트입니다. 데이터는 에이전트들과 고객의 기기들로 부터 와서 Kinesis stream으로 오게 됩니다. 그 다음 ECS로 약간의 pre-processing을 하고, S3의 data lake로 오게 됩니다. S3는 25PB의 프로세스된 데이터셋으로 구성됩니다.
-
그 위에 Alert Logic는 많은 데이터가 포함된 풍부한 sql 구문으로 의미를 추출하는 파싱을 하는 검색엔진이 있습니다. 검색하는 데이터와 검색 엔진은 기본적으로 MapReduce 엔진입니다. 여러 개의 LAMBDA함수로 구성되어 있으므로 살펴보겠습니다.
-
검색 요청은 ECS 클러스터로 들어와 유효성 검사 및 실행을 계획한 다음 단일 LAMBDA 함수로 가게 됩니다. 특정 고객에 대한 데이터 양에 기반하여 엔진 실행을 위한 작업 섀도잉을 실행합니다.
-
그 이후 데이터를 프로세싱하고 필터링하고 요청한 데이터로 그것을 보강하는 수천개의 필터 함수를 사용하게 됩니다. 이러한 검색결과들은 다른 S3 버킷으로 보내지고, 사용자에게 돌아가 ECS로 결과를 보여줍니다. 그 이후 Kinesis와 다른 LAMBDA 함수로 통합을 위해서 데이터가 보내집니다. 이 모든 과정은 STEP FUNCTION 아래의 단일의 LAMBDA함수로 통제됩니다. 프로세스의 관리를 위한 것입니다.
-
단일 검색에 수천개의 LAMBDA함수가 사용되고, 매우 급격한 수요 곡선과 작업 부하가 발생합니다. 0개에서 때때로 10,000개의 LAMBDA 함수로 스파이크되기도 합니다. 검색이 몇 주 또는 몇 달 또는 몇 년에 걸쳐서 검색하는 내용은 일반적으로 수백 테라바이트이므로 플래시 스케일로 확장해야합니다. 검색 엔진에 대한 성능 검사를 해보았는데 한시간 만에 0에서 50,000으로 확장되었고 동시에 멈췄을 때 0으로 돌아가 비용을 절약할 수 있었습니다.
AWS Lambda란? 서버를 프로비저닝하거나 관리하지 않고도 코드를 실행할 수 있게 해주는 컴퓨팅 서비스입니다. AWS Lambda는 필요 시에만 코드를 실행하며, 하루에 몇 개의 요청에서 초당 수천 개의 요청까지 자동으로 확장이 가능합니다. 사용한 컴퓨팅 시간에 대해서만 요금을 지불하면 되고 코드가 실행되지 않을 때는 요금이 부과되지 않습니다. AWS Lambda에서는 사실상 모든 유형의 애플리케이션이나 백엔드 서비스에 대한 코드를 별도의 관리 없이 실행할 수 있습니다. AWS Lambda는 고가용성 컴퓨팅 인프라에서 코드를 실행하고 서버 및 운영 체제 유지 관리, 용량 프로비저닝 및 자동 조정, 코드 및 보안 패치 배포, 코드 모니터링 및 로깅 등 모든 컴퓨팅 리소스 관리를 수행합니다.
AWS Lambda가 지원하는 언어 중 하나로 코드를 공급하기만 하면 됩니다. AWS Lambda를 사용하여 Amazon S3 버킷 또는 Amazon DynamoDB 테이블의 데이터 변경과 같은 이벤트에 대한 응답으로 코드를 실행할 수 있습니다. Amazon API Gateway를 사용하여 HTTP 요청에 대한 응답으로 코드를 실행할 수도 있으며, 또는 AWS SDK를 사용하여 만든 API 호출을 통해 코드를 호출할 수 있습니다. 이러한 기능을 제공하므로 Lambda를 사용하여 Amazon S3 및 Amazon DynamoDB와 같은 AWS 서비스에 대한 데이터 처리 트리거를 손쉽게 빌드하거나, Kinesis에 저장된 스트리밍 데이터를 처리하거나 AWS 규모, 성능, 보안에 따라 작동하는 자체 백엔드를 생성할 수 있습니다. 또한 이벤트에 의해 트리거되고 CodePipeline 및 CodeBuild를 사용하여 자동으로 배포하는 함수로 구성된 서버리스 애플리케이션을 빌드할 수 있습니다.
