-
비동기 I/O, 코루틴 이해에 도움이 된다고 생각하여 번역해보았습니다.
-
원글
The Story
검색 엔진을 개발한다고 합시다. 싱글 코어 컴퓨터를 컴퓨터를 사용하여 인덱스(색인)를 작성할 겁니다. 단순하게 생각해서, 우리의 작업은 웹 페이지를 가져오는 것(I/O 작업)과 그 내용을 처리하는 것입니다. 개별 작업은 아래처럼 생겼습니다.
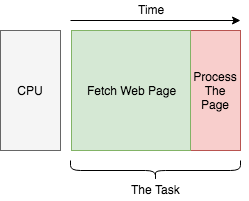
웹 페이지의 색인이 아주 많을, 간단하게 하나씩 처리해봅시다.
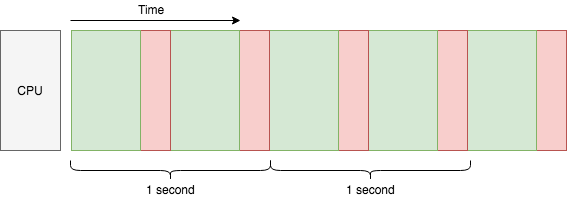
각 태스크의 소요 시간이 같다고 가정해봅시다. 매 초마다, 태스크 2개가 끝납니다. 그렇다면 우리는 이 시스템이 초당 2개의 태스크를 처리한다고 할 수 있습니다. 어떻게 하면 여기서 성능을 더 개선시킬 수 있을까요? 확실한 답 중 하나는 CPU 코어를 추가하는 것입니다.
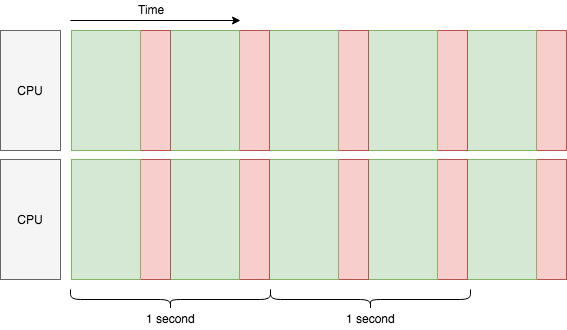
이렇게 하면 초당 태스크 4개로 태스크 처리량이 두 배로 늘어납니다. 네트워크가 병목이 아니라고 가정하면, 그리고 우리가 CPU코어를 늘릴때마다 처리량은 선형적으로 증가합니다. 여기서 CPU 코어당 처리량을 더 개선시킬 수 있을까요? 멀티쓰레딩을 하면, 가능합니다.
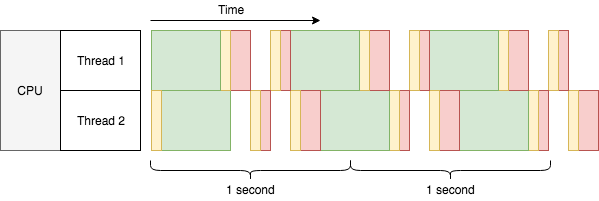
2 쓰레드가 초당 거의 6 태스크를 처리합니다, 초당 약 2.7 태스크 정도를 처리하지만 2코어일 때의 초당 4태스크보다는 훨씬 부족합니다. 멀티쓰레딩엔 어떤 문제가 있을까요? 위 다이어그램을 확인해보면
- 추가 작업시간이 있습니다.(노란색 부분)
- 초록색 부분은 다른 쓰레드와 겹칠 수 있습니다만
- 초록색이 아닌 부분은 다른 초록색이 아닌 부분과 겹칠 수 없습니다.
여기서 노란색 부분은 컨텍스트 스위칭을 의미합니다. 컨텍스트 스위칭은 단일 코어 CPU에서 병렬적으로 멀티쓰레딩 혹은 멀티쓰레딩을 할 때마다 반드시 필요합니다. 하나의 CPU 코어는 한번에 작업 하나만 할 수 있습니다. (하이퍼 쓰레딩이나 그 비슷한 건 없다고 가정하에) 그래서 여러 쓰레드를 병렬적으로, 또 순서대로 돌리기 위해서는, CPU는 반드시 시간을 작은 단위로 쪼개고 각 쓰레드가 이 작은 단위 안에서 각 쓰레드를 조금씩 실행해야 합니다. 다소 극단적 예시긴 하지만 어쨌든 설명에 큰 문제가 되는 부분은 아닙니다.
여기서 다시 생각해봅시다. 초록색 부분은 쓰레드 간에 겹치는 부분입니다. CPU가 동시에 두 작업을 하는 것일까요? 아닙니다. CPU는 초록색 부분 가운데에서는 아무것도 하지 않습니다. HTTP 응답(I/O)를 대기하기 때문입니다. 이것이 멀티쓰레딩 처리량을 초당 1.7개로 줄이는 대신 2.7개로 늘릴 수 있는 이유입니다. 실제로 단일 코어에서 멀티 쓰레딩으로 CPU 집약적 작업을 실행할 수도 있습니다만, 성능 향상은 전혀 없을 겁니다. 다중화된 빨간 부분처럼(태스크에 따라 실제로는 컨텍스트 스위칭이 좀 더 있을 수도 있습니다.) 실제로 동시에 실행되는 것처럼 보이지만, 모든 작업을 끝내는 총 시간은 실제로는 태스크 하나 하나씩 실행하는 것보다 깁니다. 그래서 이게 동시성(parallelism)이 아니라 병행성(concurrency)로 불리는 이유입니다.
상상하는 것처럼, 추가 쓰레드당 처리량 상승은 미미합니다. 추가 쓰레드에 쓰이는 메모리 공간을 제외하더라도, 컨텍스트 스위칭에 쓰이는 낭비 때문에 큰 처리량 상승은 기대하기 힘듭니다. 보통 단일 CPU 코어에서 수만 개의 쓰레드를 실행하는 것은 적절치 못합니다. 그렇다면 단일 CPU 코어에서 동시에 수 만개의 I/O 태스크를 실행하는 것은 가능할까요? 이건 한 때 c10k문제로 유명했던 것으로 비동기 I/O를 통해 해결할 수 있습니다.
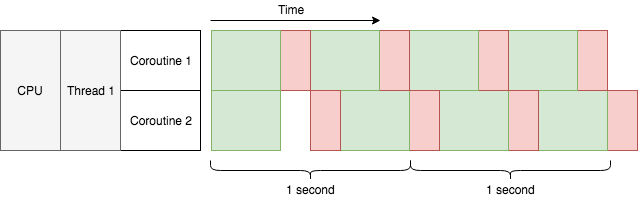
초당 3.7태스크로 처리량이 늘었습니다. 2 CPU 코어일 의 초당 태스크 4개에 거의 근접했습니다. 이것이 실 데이터는 아닙니다만, OS 쓰레드와 비교했을 때 코루틴은 메모리를 더 적게 쓰고 컨텍스트 스위칭 타임도 더 적게 씁니다.
협력적 멀티태스킹
그래서 코루틴은 뭘까요?
위 마지막 다이어그램에서, 이전 다이어그램과의 큰 차이를 확인할 수 있습니다. 초록색 부분이 동일한 쓰레드에서 겹칩니다. 왜냐하면 마지막 다이어그램에서, 기존에는 블로킹 I/O를 사용했던 것과는 다르게 우리의 코드는 비동기 I/O를 사용했기 때문입니다. 이름이 말해주듯, 블로킹 I/O는 I/O 결과가 준비될 때까지 쓰레드를 블록합니다. 블로킹 I/O로 병행성을 달성하기 위해서는, 멀티쓰레딩이나 멀티 프로세싱이 필요합니다. 반대로 비동기 I/O는 수 천개의 동시 I/O 읽기 쓰기 작업이 동일 쓰레드 안에서 가능합니다. 각 I/O 작업은 전체 쓰레드가 아닌 개별 코루틴만 블로킹합니다. 멀티쓰레딩처럼, 코루틴은 I/O 동안 동시성을 가지는 수단을 제공하지만 멀티쓰레딩과는 다르게 이 동시성은 싱글 쓰레드 안에서 발생합니다.
OS에 의해 관리되는 쓰레드는 선점적 멀티태스킹이라 불리는 접근을 사용합니다. 예를 들면, 이전의 멀티쓰레딩 다이어그램에서는 CPU 코어가 하나만 있습니다. 쓰레드 2번이 첫 번째 페이지 처리를 시작할 때, 쓰레드 1번은 프로세싱을 끝내지 않은 상태입니다. OS는 강제로 쓰레드 1번에 인터럽트해서 일부 자원을 쓰레드 2번과 공유시킵니다. 그러나 쓰레드 1번도 동시에 프로세스를 끝내려면 CPU 시간이 필요합니다. 그래서 OS는 잠시 뒤 쓰레드 2번을 중지시키고 다시 쓰레드 1번을 실행시켜야 합니다. 태스크의 크기에 따라 이 작업은 여러 번 일어날 수 있습니다. 이런 방식으로 모든 쓰레드는 공정하게 실행 기회를 얻게 됩니다. 대략 아래와 비슷합니다.
Thread 1: 나 실행해야해!
OS: Ok, 실행해.
Thread 2: 나 실행해야해!
OS: 음 1초만 ... Thread 1, 잠깐 대기해!
Thread 1: 아니 나 아직 안 끝났는데, 상사니까 어쩔 수 없지...
OS: 오래 안 걸릴 거야. Thread 2 네 차례야.
Thread 2: 나이스! (&%#$@..+*&#)
Thread 1: 나 실행해도 돼?
OS: 잠시만 ... Thread 2, 쉬어!
Thread 2: 알았어... 하지만 난 아직 CPU가 필요해.
OS: 나중에 해. Thread 1, 서둘러!
반대로 코루틴은 이벤트 관리자의 도움을 받아 그 자체로 협력적으로 스케줄됩니다. 이벤트 관리자는 코루틴 쓰레드와 같은 쓰레드에 존재하고 강제로 컨텍스트 스위칭을 발생시키는 OS 스케줄러와 다르게 코루틴 그 자체가 멈출때만 작동합니다. 쓰레드는 언제 코루틴이 실행되는 것이 좋은지 알지만 코루틴은 모릅니다 - 이벤트 관리자만 언제 코루틴이 실행되어야 좋은지 압니다. 이벤트 관리자는 대개 이전의 코루틴이 이벤트(HTTP 응답 등)를 대기하기 위해 실행권을 양보하고 난 뒤 다음 코루틴이 실행되도록 트리거합니다. 병행성을 달성하는 이런 접근을 협력적 멀티태스킹이라고 부릅니다. 대략 아래와 비슷합니다.
Coroutine 1: 이벤트 A가 도착하면 알려줘. 난 여기서 멈췄어.
Event manager: Ok. 너는 어떄 coroutine 2?
Coroutine 2: 이벤트 B가 오기 전까지는 할 게 없어.
Event manager: 좋았어. 내가 보고 있을게.
Event manager: (잠시 뒤) coroutine 1, 이벤트 A가 도착했어!
Coroutine 1: 좋아! 어디 보자... 됐군 , 이제 난 이벤트 C가 필요해.
Event manager: 잘 되가고 있군. 이벤트 B가 방금 도착한 것 같아, coroutine 2?
Coroutine 2: 파일에다 저장 좀 하고... 짠! 난 끝났어.
Event manager: 잘했어! 이벤트 C가 올 기미가 안 보이네. 난 잠시만 쉴게.
(잠시 침묵)
Event manager: 이런 이벤트 C가 타임아웃이야!
Coroutine 1: 어, 에러를 던지고 나를 종료할게:S
Event manager: 알았어, 널 믿을게 :/
코루틴 입장에서, 태스크는 외부적 요소로 중단되지 않습니다. 태스크는 코루틴 내부에서 그 스스로만 중단할 수 있습니다. 코루틴이 매우 많으면, 병행성은 각 코루틴들이 이벤트 대기하는 시간에 따라 달라집니다. 만약 절대 중지되지 않는 코루틴을 작성한다면, 다른 코루틴들이 절대 실행될 기회를 얻을 수 없기 때문에 어떤 병행성도 실행 중이 허용되지 않습니다. 다르게 말하자면, 중단점들 사이에서는 코드가 안전하다고 볼 수 있습니다. 왜냐면 그것은 다른 어떤 코루틴도 공유 상태를 건드리지 않고 실행될 수 없기 때문입니다. 이것이 마지막 다이어그램에서, 붉은 부분이 쓰레드처럼 인터리브되지 않는 이유입니다.
장단점
비동기 I/O는 수 천 개의 병행 I/O 작업을 같은 쓰레드에서 처리할 수 있습니다. 컨텍스트 스위칭 비용과 메모리 사용을 멀티 쓰레딩에 비해 크게 절감할 수 있습니다. 그러므로 다 수의 I/O 처리 태스크를 처리한다면, 비동기 I/O는 효율적으로 한정된 CPU와 메모리를 사용하고 처리량을 크게 늘릴 수 있습니다.
코루틴으로, 협력적으로 스케줄되는 순차적 코드를 작성할 수 있습니다. 만약 비즈니스 로직이 복잡하다면, 코루틴은 비동기 I/O 코드의 가독성을 크게 향상시킬 수 있습니다.
하지만 단일 태스크에서 비동기 I/O는 실제로는 처리량을 낮출 수 있습니다. 예를 들면 간단한 recv() 작업에서 블로킹 I/O는 결과를 얻을 때까지만 블록되지만, 비동기 I/O는 추가적인 작업이 필요합니다. 읽기 이벤트를 등록하고, 이벤트가 도착할 때까지 대기한 다음, 결과가 반환될 때까지 recv() 를 시도하고, 마지막으로 콜백을 통해 결과를 받습니다. 코루틴으로, 프레임워크 비용이 훨씬 커집니다. (파이썬에서 이 비용을 크게 낮춰준uvloop 라이브러리에 감사드립니다.) 그러나 생 블로킹 I/O와 비교했을 때 추가적인 오버헤드는 여전히 남아있습니다.
비동기 I/O에서 타이밍은 그 협력적 특성상 예측이 잘 되지 않습니다. 예를 들면 코루틴에서 1초를 sleep 하고 싶을 수 있습니다. 그러나 다른 코루틴에서 실행권을 받고 2초간 실행된다면, 첫 코루틴으로 실행권이 돌아갈 때까지 이미 2초가 지나갑니다. 그래서 sleep 1은 최소 1초를 기다린다는 것을 의미합니다. 실제로 말 그대로 협력적이려면 await 사이 모든 코드를 ASAP 하게 끝내도록 노력을 기울여야 합니다. 여전히, 당신의 코드는 당신은 통제 밖에 있고, 그래서 이 예측 불가능한 타이밍을 인지하는 것이 중요합니다.
마지막으로, 비동기 프로그래밍은 어렵습니다. 좋은 비동기 코드는 말처럼 잘 작성하기 쉽지 않으며, 디버깅하는 것은 유사한 동기 코드를 작성하는 것보다 어렵습니다. 특히 전체 팀이 같은 비동기 코드 조건에서 작업할 때, 잘못되기 쉽습니다. 그러므로 비동기 I/O를 사용하는 일반적으로 권장되는 방법은, 높은 병행성 시나리오에서만 조심스럽게 사용하는 것입니다. 비동기 I/O는 만능 도구가 아니라 양날의 검입니다. 그리고 시간에 예민한 작업을 다룬다면, 더더욱 조심해야 합니다.
