[해석/Diffusion/KerasCV]High-performance image generation using Stable Diffusion in KerasCV
diffusions
학습을 위해 기존 문서를 번역한 글임을 미리 서두에서 밝힙니다
원본 : https://keras.io/guides/keras_cv/generate_images_with_stable_diffusion/
케라스 CV의 Stable Diffusion 을 사용한 고성능 이미지 생성
Overview 개괄설명
이번 가이드에서, 우리는 stability.ai의 text-to-image 모델 KerasCV 구현체인 Stable Diffusion을 사용하여 어떻게 새로운 이미지 생성이 텍스트 프롬프트를 기반으로 만들어지는지 보여줄 것입니다.
Stable Diffusion 은 강력한, 오픈소스인 텍스트를 이미지로 생성하는 모델입니다. 이미 오픈소스 구현채로 몇가지들이 존재하는데, 이것은 여러분들에게 문맥 프롬프트로써 쉽게 이미지를 생성할 수 있도록 합니다. KerasCV는 몇몇 눈에 띄는 장점들을 제공합니다. 이는 XLA compilation 과 mixed precision 지원을 포함하고 있는데, 이것들은 최신의 생성 속도를 달성하도록 합니다.
이번 가이드에서, 우리는 KerasCV의 Stable Diffusion 구현채를 탐색할 것인데, 이러한 강력한 퍼포먼스 부스트를 어떻게 사용하는지 보여줄 것이고, 그것들이 제공하는 것을 수행할 때의 장점을 살펴볼 것입니다.
시작하기위해, 몇몇 의존성 패키지들을 설치하겠습니다.
!pip install --upgrade keras-cv
import time
import keras_cv
from tensorflow import keras
import matplotlib.pyplot as plt소개
먼저 주제를 설명한 다음 구현 방법을 보여주는 대부분의 자습서와 달리 텍스트를 이미지로 생성하면 설명하는 대신 보여주기가 더 쉽습니다.
keras_cv.models.StableDiffusion() 의 파워를 확인해보세요.
먼저, 우리는 모델을 구성합니다.
model = keras_cv.models.StableDiffusion(img_width=512, img_height=512)우리는 프롬프트를 넣을 것입니다.
images = model.text_to_image("photograph of an astronaut riding a horse", batch_size=3)
def plot_images(images):
plt.figure(figsize=(20, 20))
for i in range(len(images)):
ax = plt.subplot(1, len(images), i + 1)
plt.imshow(images[i])
plt.axis("off")
plot_images(images)꽤 놀랍지않나요?
그러나 이것이 모델이 할 수 있는 전부가 아닙니다. 더 복잡한 프롬프트를 시도해보겠습니다.
images = model.text_to_image(
"cute magical flying dog, fantasy art, "
"golden color, high quality, highly detailed, elegant, sharp focus, "
"concept art, character concepts, digital painting, mystery, adventure",
batch_size=3,
)
plot_images(images)가능성은 글자그대로 무한합니다(또는 적어도 Stable Diffusion 의 잠재 매니폴드의 경계만큼 확장됩니다)
Wait, how does this even work? 잠깐, 어떻게 이렇게 작동할까요?
여러분들이 아마 이 부분에서 예상한 것과 달리, Stable Diffusion 은 실제 마법은 아닙니다. 이는 ‘잠재 디퓨전 모델’의 종류입니다. 이게 어떤 의미인지 더 깊게 파고들어가보겠습니다.
여러분들은 아마 super-resolution의 개념에 대해 익숙할것입니다 : 이는 딥러닝 모델이 인풋 이미지의 노이즈를 제거하는 것에 대한 학습이 가능한 것을 말합니다. — 그리고 그 지점에서 더 높은-해상도 버전을 제공합니다. 딥 러닝 모델은 잡음이 많은 저해상도 입력에서 누락된 정보를 마법처럼 복구하여 이를 수행하지 않습니다. 오히려 모델은 훈련 데이터 분포를 사용하여 입력이 제공되었을 가능성이 가장 높은 시각적 세부 사항을 보이게 합니다. super-resolution에 대해 더 학습하고 싶다면, 아래의 keras.io 튜토리얼을 살펴보셔도 됩니다 :
- Image Super-Resolution using an Efficient Sub-Pixel CNN
- Enhanced Deep Residual Networks for single-image super-resolution
만약 여러분이 이 생각을 한계가 다다를때까지한다면, 아마 질문하기 시작할 것입니다 — 만약 우리가 어떤 모델을 완전히 pure 한 노이즈에 실행한다면 어떻게 될까요? 그 모델은 아마 ‘denoise the noise(노이즈제거)’ 후 최신의 이미지를 보여주기 시작할 것입니다. 이러한 과정을 여러번 반복하다보면, 여러분은 작은 노이즈 가득한 조각이미지를 점점 선명하고 고해상도의 인위적인 사진으로 바꿀 수 있습니다.
잠재 디퓨전의 주요 아이디어가 이것입니다, 이는 2020년의 논문, High-Resolution Image Synthesis with Latent Diffusion Models 에서 제안되었습니다. 디퓨전을 더 깊게 이해하기 위해서는, 아래 케라스 튜토리얼도 참고하시면 됩니다.
이제, 잠재 디퓨전에서 text-to-image 시스템까지 가기 위해서 여러분들은 하나 더 주요 기능이 필요합니다 : 프롬프트의 키워드에서 생성된 시각화 콘텐츠를 조절하는 능력 말입니다. 이는 “conditioning 컨디셔닝”을 거쳐 완성이 됩니다. 텍스트 들을 재현한 벡터에, 노이즈 조각을 통합하는 것으로 구성된 기본적인 딥러닝 기술 말입니다. 그리고 나서, {image : caption} 쌍의 데이터셋으로 모델에 학습합니다.
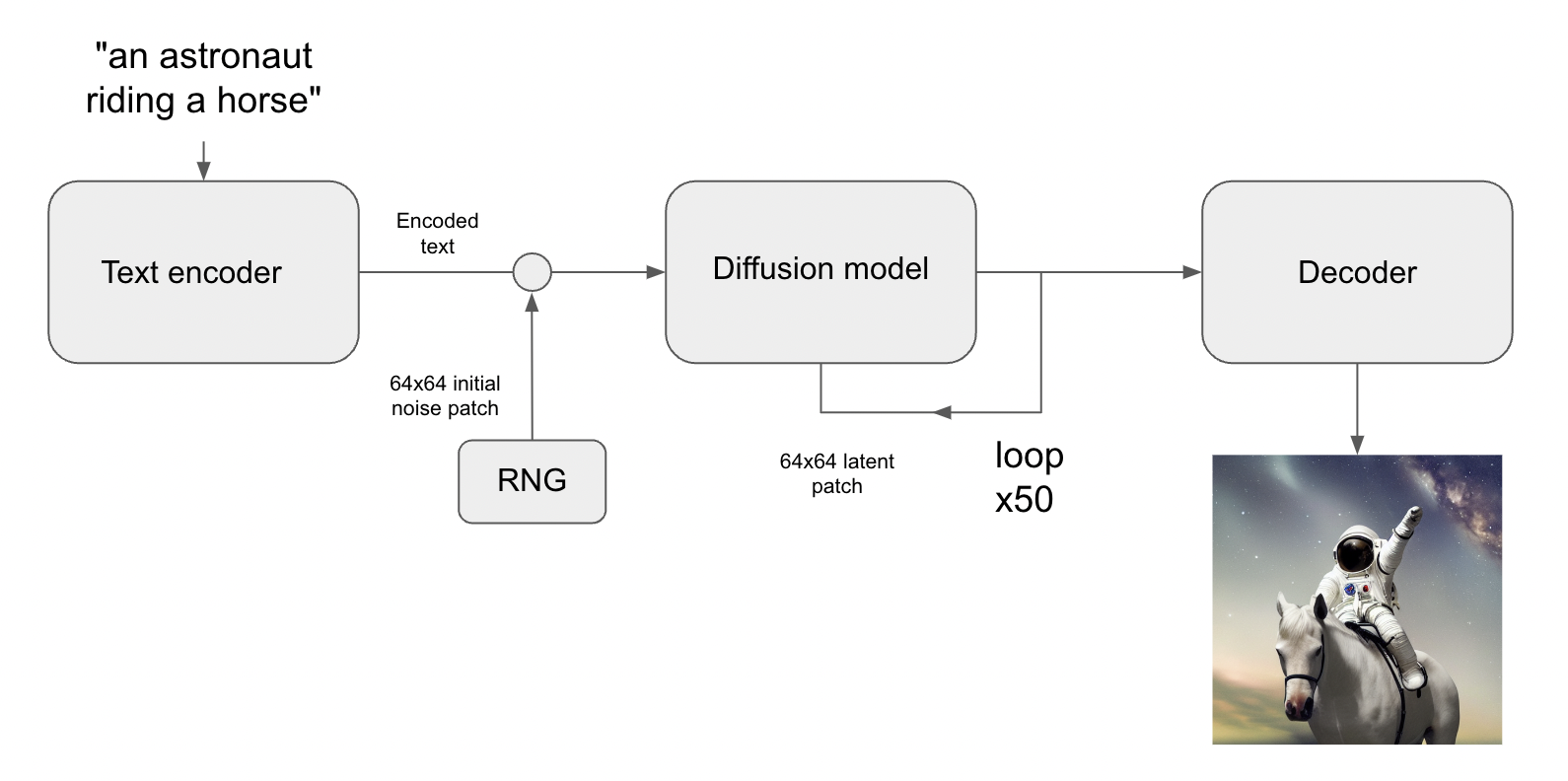
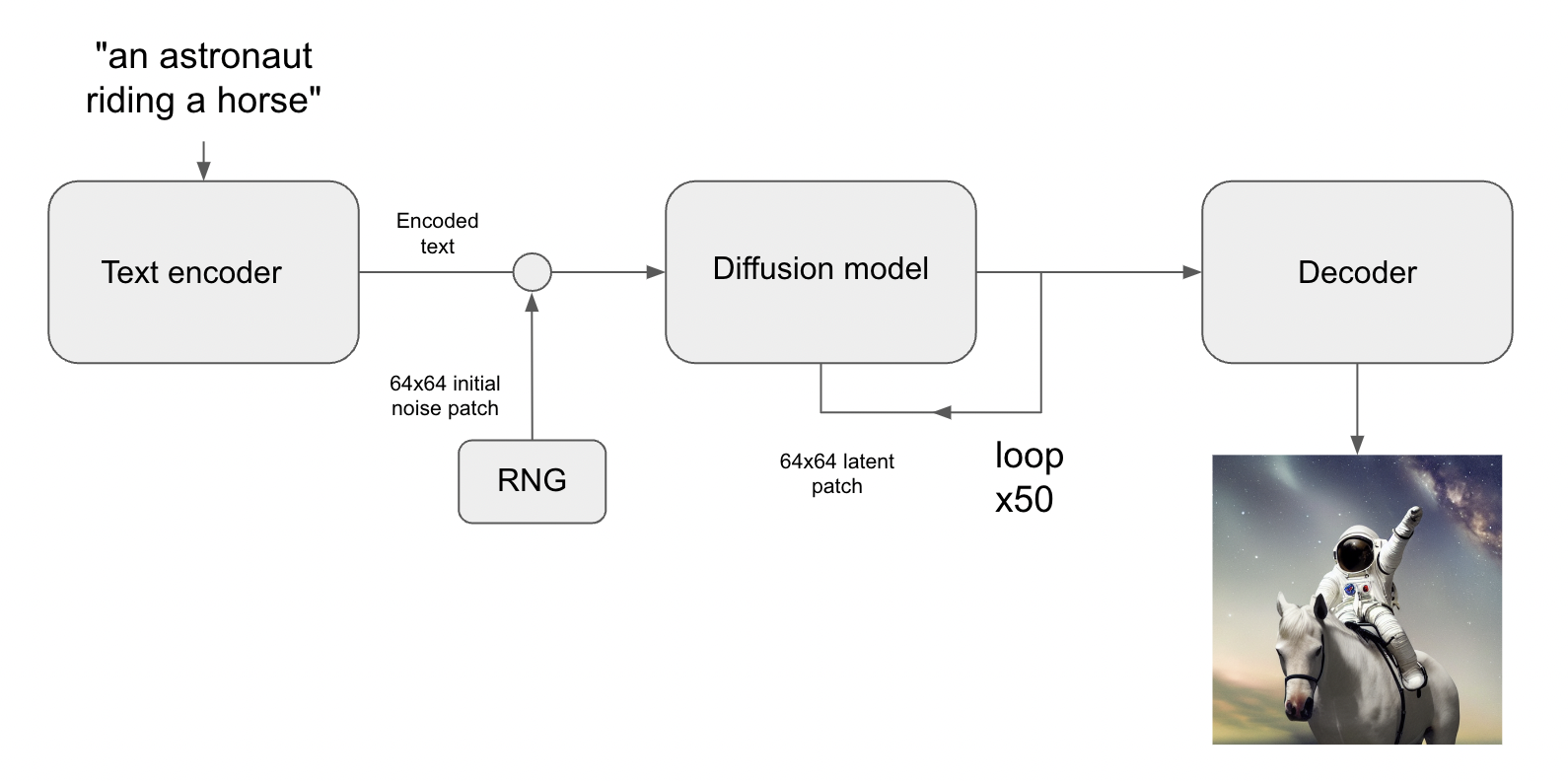
이는 Stable Diffusion 아키텍쳐를 키웁니다. Stable Diffusion 은 3가지 파트로 구성되어있습니다 :
- 텍스트 인코더 : 여러분의 프롬프트를 잠재벡터로 변경
- 디퓨전 모델 : 반복적으로 64x64 잠재 이미지 패치를 ‘denoise’ 함
- 디코더 : 최종 64x64 잠재 패치를 고 해상도 512x512 이미지로 변경
먼저, 여러분의 텍스트 프롬프트는 텍스트 인코더에 의해 잠재 벡터 공간으로 투영될 것입니다. 이는 단순히 미리 학습된 것이고, frozen 언어 모델입니다. (frozen language model?) 그리고나서 프롬프트 벡터는 임의로 생성된 노이즈 조각을 통합하게 되는데, 이는 steps 시리즈를 넘어서는 디코더에 의해 반복적으로 ‘denoise’ 하는 것을 말합니다. (더 많은 step 을 실행할 수록, 여러분의 이미지는 더 명확하고 좋아질 것입니다 - 기본 값은 50step 입니다)
마지막으로, 64x64 잠재 이미지는 이코더로 보내지고, 그것의 고해상도로 적당히 렌더링됩니다.
이 모든것들을 한번에 정리해보자면, 꽤나 간단한 시스템입니다 — 4가지 파일 안에 있는 케라스 구현체들은 500줄보다 적은 코드로 구성되어있습니다
- text_encoder.py : 87줄
- diffusion_model.py : 181줄
- decoder.py : 86줄
- stable_diffusion.py : 106줄
수백맨장의 사진과 그 캡션을 한번에 학습할 때, 이 상대적으로 간단한 시스템은 마법처럼 보일 것입니다. Feynman 은 이 세계에 대해 이야기를 했습니다. “이것은 복잡하지 않고, 조금 많은 것일 뿐이다!”
Perks of KerasCV
Stable Diffusion 의 몇몇 구현체들은 공통적로 ‘왜 우리가 keras_cv.models.StableDiffusion을 사용해야 하는지’ 에 대해 설명합니다.
쉽게 사용할 수 있는 API일 뿐 아니라(?aside from), Keras CV의 Stable Diffusion 모델은 몇몇 강력한 이점을 가지고 있는데요, 포함하는 것들은 :
- Graph mode execution 그래프 모드 실행
- XLA compilation through jit_compile=True jit 컴파일=True를 사용한 XLA 컴파일화
- Support for mixed precision computation mixed
이것들이 통합될 때, KerasCV Stable Diffusion 모델은 단순한 구현채보다 훨씬 빠른 중력의 속도로 실행될 것입니다. 이 부분은 모든 피쳐들이 어떻게 사용할 수 있는지 보여주고, 이들을 사용함으로부터 산출할 수 있는 퍼포먼스 결과를 보여줍니다.
비교를 목적으로 하기에, 우리는 벤치마크인 Stable Diffusion 의 HuggingFace diffusers 의 실행시간을 KerasCV 구현체와 비교 실행하였습니다. 두 구현채 모두 각 이미지의 50개 step 을 사용하여 3개의 이미지를 생성하는 과제를 얻었고, 이 벤치마크에서 우리는 Tesla T4 GPU를 사용하였습니다.
모든 벤치마크들은 깃헙에 오픈소스로 공유되어있으며, 이 결과는 Colab으로 재실행해볼 수 있습니다. 아래 테이블에서 벤치마크의 결과물들은 표시됩니다.
Tesla T4에서 실행 시간에 대하여 30% 정도 개선되었습니다. 개선된 수준은 V100에서는 훨씬 낮았는데요, 우리는 벤치마크의 결과가 KerasCV 에 대하여 지속적으로 호의적일 것이라고 점점 기대하고 있습니다.
완벽함 속에서도, 콜드스타트와 웜스타트 생성 시간은 기록되었습니다. 콜드스타트 실행 시간은은 1개 모델 생성/컴파일 시간 코스트를 포함합니다. 생산 환경 속에서 neglible 하므로 ( 여러분은 동일한 모델 인스턴스를 여러번 재사용할 것입니다.) 그럼에도 불구하고, 여기 콜드스타드 수치들이 있습니다.
이 가이드에서 아마 다양하게 실행하여 나온 런타임 결과에서, KerasCV 구현체는 pytorch와 비교하였을 때 눈에 띌 정도로 빨랐습니다. 이는 XLA 컴파일화에 많은 기여를 했기 때문일 것입니다.
기억하세요! 각 최적화의 베네핏은 하드웨어 셋업간에 매우 눈에띄게 다양합니다.
시작하기 위해, 우리의 최적화 되지 않은 모델을 먼저 벤치마크 합니다.
benchmark_result = []
start = time.time()
images = model.text_to_image(
"A cute otter in a rainbow whirlpool holding shells, watercolor",
batch_size=3,
)
end = time.time()
benchmark_result.append(["Standard", end - start])
plot_images(images)
print(f"Standard model: {(end - start):.2f} seconds")
keras.backend.clear_session() # Clear session to preserve memory.Mixed Precision 혼합 정밀도
“Mixed precision’은 float16 precision 를 사용하는 계산으로 구성되어있는데, 가중치는 float32 포맷으로 저장됩니다. float16 은 float32 보다 더 눈에 띌 정도로 빠르게 동작한다는 이점을 살렸습니다. (현대 NVIDIA GPU 에서 말이죠).
케라스에서 mixed precision 계산을 가능하게하는 것은 아래와 같습니다. (keras_cv.models.StableDiffusion)
keras.mixed_precision.set_global_policy("mixed_float16")
print("Compute dtype:", model.diffusion_model.compute_dtype)
print(
"Variable dtype:",
model.diffusion_model.variable_dtype,
)이게 전부입니다. 작동합니다
여러분도 볼 수 있듯, 위에 구성한 모델은 mixed precision 계산을 사용합니다; float16의 속도를 끌어올립니다. 그러는 동안 float32 precision 에 변수가 저장됩니다.
# Warm up model to run graph tracing before benchmarking.
model.text_to_image("warming up the model", batch_size=3)
start = time.time()
images = model.text_to_image(
"a cute magical flying dog, fantasy art, "
"golden color, high quality, highly detailed, elegant, sharp focus, "
"concept art, character concepts, digital painting, mystery, adventure",
batch_size=3,
)
end = time.time()
benchmark_result.append(["Mixed Precision", end - start])
plot_images(images)
print(f"Mixed precision model: {(end - start):.2f} seconds")
keras.backend.clear_session()XLA Compilation XLA 컴파일화
텐서플로우는 XLA: Accelerated Linear Algebra 가속화된 선형 대수 컴파일러를 내부에 가지고 있으며, keras_cv.models.STableDiffusion 은 jit_compile 인자를 지원합니다. 이 인자를 True 셋팅하면 XLA 컴파일 사용이 가능하고, 눈에 띌 정도로 높은 스피드로 결과물을 냅니다.
아래 코드를 사용해보세요:
keras.mixed_precision.set_global_policy("float32")
model = keras_cv.models.StableDiffusion(jit_compile=True)
# Before we benchmark the model, we run inference once to make sure the TensorFlow
# graph has already been traced.
images = model.text_to_image("An avocado armchair", batch_size=3)
plot_images(images)우리의 XLA모델을 벤치마크 해봅시다
start = time.time()
images = model.text_to_image(
"A cute otter in a rainbow whirlpool holding shells, watercolor",
batch_size=3,
)
end = time.time()
benchmark_result.append(["XLA", end - start])
plot_images(images)
print(f"With XLA: {(end - start):.2f} seconds")
keras.backend.clear_session()A100 GPU에서, 우리는 2배의 속도를 냈습니다. 놀랍지 않나요?
모두 함께 하기 putting it all together
자, 세계에서 가장 뛰어난 stable diffusion 추론 파이프라인을 어떻게 모아볼 수 있을까요?
2 줄의 코드를 포함하고,
keras.mixed_precision.set_globa_policy('mixed_float16')
model = keras_cv.models.StableDiffusion(jit_compile=True)
그리고 이것도 사용합니다 .
# Let's make sure to warm up the model
images = model.text_to_image(
"Teddy bears conducting machine learning research",
batch_size=3,
)
plot_images(images)정확히 얼마나 빠를까요? 살펴봅시다!
start = time.time()
images = model.text_to_image(
"A mysterious dark stranger visits the great pyramids of egypt, "
"high quality, highly detailed, elegant, sharp focus, "
"concept art, character concepts, digital painting",
batch_size=3,
)
end = time.time()
benchmark_result.append(["XLA + Mixed Precision", end - start])
plot_images(images)
print(f"XLA + mixed precision: {(end - start):.2f} seconds")
print("{:<20} {:<20}".format("Model", "Runtime"))
for result in benchmark_result:
name, runtime = result
print("{:<20} {:<20}".format(name, runtime))
완전히 최적화된 모델은 A100 GPU에서 텍스트 프롬프트를 사용하여 3개의 새로운 이미지를 생성하는데 4초가 걸립니다.
결론
KerasCV 는 가장 최신의 Stable Diffusion 구현체를 제공해줍니다 — 그리고 XLA과 mixed precision 을 사용함으로써, 가장 빠른 Stable Diffusion 파이프라인이 2022년 9월에 이용가능하도록 제공하였습니다.
일반적으로 keras.io 튜토리얼 마지막 부분에서 우리는 더 학습하기 위한 미래 방향성을 남겨두곤 하는데요, 이번에는 여러분에게 한가지 아이디어를 남겨봅니다:
Go run your own prompts through the model! It is an absolute blast!
만약 여러분이 NVIDIA GPU를 가지고 있거나, M1 맥북프로륵 가지고 있다면, 여러분의 머신에서 모델을 로컬로 실행해볼 수 있습니다. 만약 맥북프로 M1로 실행한다면, mixed precision 은 불가능할 것입니다, Apple 의 Metal runtime 을 아직 지원하지 않고 있습니다.
