Session Clustering 방식
앞서 sticky 세션은 각 서버에 세션을 저장해놓았더니 세션 불일치는 해결되었지만 도리어 성능이 안좋아진다는 결과를 낳았다.
그러면 세션 정보를 각 서버마다 저장하는게 아닌 세션 데이터를 복사해 서버들에게 전파해 가져다 쓸수 있으면 되지 않을까?
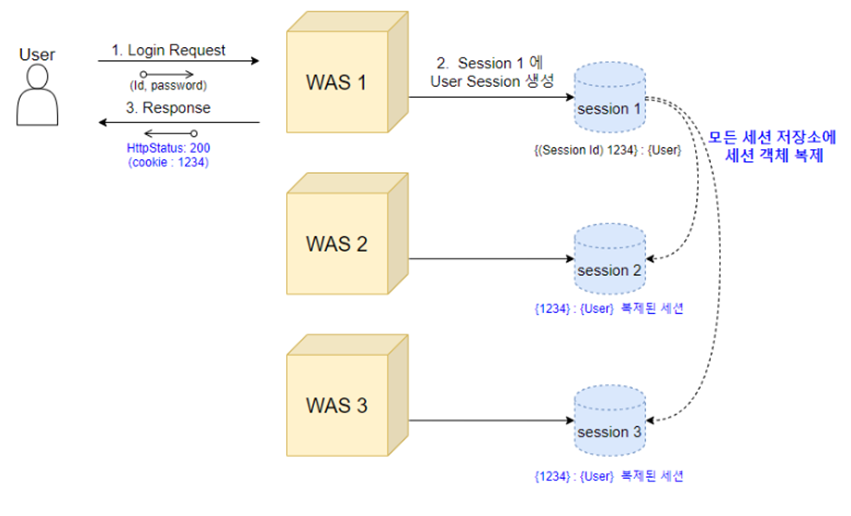
세션 클러스터링은 서버들을 하나의 클러스터로 묶어 관리하고, 클러스터 내의 서버들이 세션을 공유할 수 있도록 하는 방식이다.
예를들어 서버1에서 login session이 저장되었다면, 서버2와 서버3에도 서버1에 저장되어있는 세션을 전파(복사)하는 것이다.
WAS마다 session clustering을 지원하는 방식이 조금씩 다른데,
그중 가장 대표적 WAS인 톰캣(Tomcat)에서는 어떻게 Session Clustering을 구현하고 있는지 알아보자.
Tomcat Session Clustering
Tomcat에서는 크게 두 가지 방식으로 Session Clustering을 구현 기능을 제공한다.
1. All-to-All Session Replication
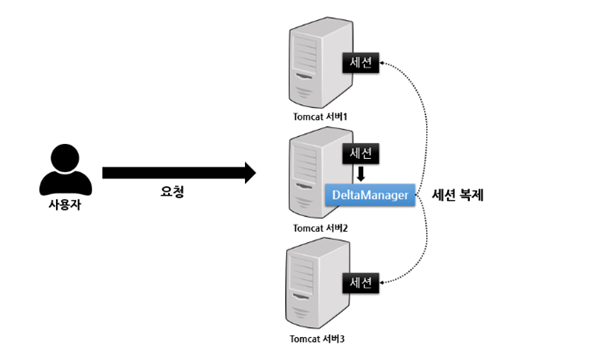
All-to-All 방식은 하나의 세션 클러스터 내에서 데이터가 변경되면 변경된 사항이 다른 모든 서버로 복제 되는 방식으로, 톰캣에서 제공하는 DeltaManager 클래스를 통해 구현된다.
특정 서버에 생성된 세션을 클러스터를 이루는 모든 서버에 세션을 복제하기 때문에 클라이언트의 요청을 한 곳으로 지정하지 않아도 되고 다른 서버로 요청을 보내더라도 같은 세션을 유지할 수 있다.
만일 이용하고 있는 서버에 장애가 발생해도 다른 서버에서 세션을 유지하고 있기 때문에 클라이언트는 동일한 서비스 환경을 제공받을 수 있게 된다.
하지만 All-to-All 방식에서는 모든 서버가 전체 세션 데이터를 유지하고 있기 때문에, 다른 서버에서 세션을 찾기 위한 추가적인 네트워트 I/O가 발생하진 않지만, 그만큼 많은 메모리가 필요하다는 단점이 있다.
그리고 세션을 저장할 때 서버 수 만큼 복제하고 각 서버에 전달, 저장해야하기 때문에 서버 수에 비례하여 네트워크 트래픽이 증가하게 되기도 한다.
추가적으로 세션 전파 작업 중 모든 서버에 세션이 전파되기까지의 시간차로 인한 세션 불일치 문제와 같은 예상치 못한 문제가 발생할 가능성이 존재한다.
📌Tip
톰캣 공식 문서에서도 All-to-All 방식은 소규모 클러스터 환경(노드가 4개 미만)에서 좋고, 이보다 큰 클러스터 환경에서는 추천하지 않는다고 한다.
그리고 DeltaManager를 사용한 방식은 애플리케이션이 배포되지 않은 노드에도 복제를 시도하기 때문에 불필요한 트래픽을 서버에 발생시키는 문제도 존재한다.
Tomcat에서는 이러한 문제를 해결하기 위해 다음으로 소개할 BackupManager를 이용한 방법도 제공해준다.
2. Primary-Secondary Session Replication
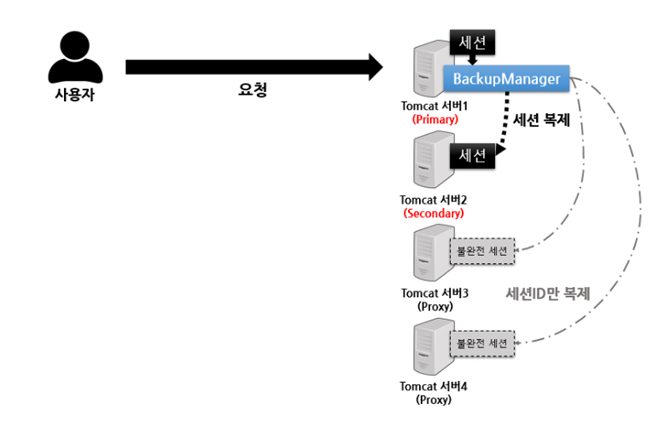
Primay-Secondary 방식은 Primary 서버의 세션 데이터를 Secondary(Backup) 서버에만 전체 복제하여 저장하는 방식으로, BackupManager 클래스를 통해 이 방식을 제공하고 있다.
All-to-All Session Replication 방식은 그냥 무식하게 모든 서버에 복제하고 저장하는 것과 달리, Primary 서버와 Secondary(Backup) 서버에만 전체 세션을 복제하여 저장하되, 나머지 이외의 서버들에는 세션의 Key에 해당하는 JSESSIONID만 복제, 저장함으로써 메모리를 절약할 수 있는 방식이다.
하지만 만일 Primary, Secondary 서버를 제외한 다른 서버에 세션 정보를 요청할 경우 다시 온전한 세션 정보를 얻기 위해서는 Primary, Secondary에 다시 요청을 보내야한다는, 세션 복제를 위한 과정이 수행되는 문제점이 존재한다.
📌Tip
Primary-Secondary Session Replication 방식은 비교적 대규모 클러스터 환경에서 적합한 방식이라고 한다.
Session Clustering 문제점
위에서 톰캣 세션 클러스터링을 설명하면서 간간히 문제점에 대해 언급했지만 취합하여 정리하자면 다음과 같다.
서버 세팅의 어려움
이 방식은 scale out 관점에서 새로운 서버가 하나 뜰 때마다 기존에 존재하던 WAS에 새로운 서버의 IP/Port를 입력해서 클러스터링 해줘야 하는 불편함이 있다.
추가 메모리 비용
서버마다 동일한 세션 정보를 가지고 있어야 되기 때문에, 서버가 확장될 수록 복제해야 할 세션 데이터가 늘어나고 이는 추가적인 오버헤드로 이어진다.
Tomcat을 예로 들었을 때, 모든 데이터를 각각의 Tomcat 노드에게 전달해야 해야 하고 배포하는 노드가 아닐 경우에도 복사를 진행하기 때문에 불필요하게 메모리를 차지된다.
즉, 효율적인 메모리 관리가 이루어지지 않는다.
네트워크 트래픽 증가
데이터 변경이 발생할때 마다 세션을 전파(복사)하는 작업이 일어나기 때문에 네트워크 요청 트래픽이 증가하게 된다.
그리고 서버가 늘어날수록 이 트래픽은 더욱 심해질 것이다.
또한, 복사 뿐만 아니라 서버가 늘어남에 따라 세션을 저장하고 찾아오는 과정에서 추가적인 트래픽이 발생 할수도 있어 확장에 한계가 있다.
시차로 인한 세션 불일치 발생
세션 전파 작업 중 모든 서버에 세션이 전파되기까지의 시간차로 인한 세션 불일치 문제와 같은 예상치 못한 문제가 발생할 가능성이 존재한다.
이처럼 세션 클러스터링은 sticky 세션의 문제점인 특정 서버에만 트래픽이 몰리는 문제를 해결할 수 있었다.
그러나 세션 클러스터링이나 sticky 세션이나 서버가 세션이라는 상태(데이터)를 가진다는 것은 변함이 없다는 특징이 있다
"서버가 상태(데이터)를 가진다"라는 의미는 Scale out 방식으로 확장을 했을 때 서버가 가지고 있는 데이터를 확장하는 서버에도 똑같이 맞춰줘야 한다는 뜻이다. 이는 곧 오버헤드로 이어진다.
정리하면, 세션 클러스터링은 정합성 이슈를 해결할 수 있지만, 성능적인 한계가 존재한다고 말 할 수 있다.
