LLM
1.To Believe or Not to Believe Your LLM

GOAL : Uncertainty quantification in large language models (LLMs)위 논문에서는 LLMs에서의 불확실성 측정을 다룬 논문.Decouple Epistemic and aleatoric uncertaintyAim to ide
2.[Build GPT-1] Dataset

Reference : Let's build GPT: from scratch, in code, spelled out. (youtube) get-dev.ipynb (Colab) 이 post는 위 유튜브 영상을 기반으로 만들어졌습니다. Dataset 준비 shakesp
3.[Build GPT-2] Model
이제 모델을 보자.이 예시에서는 가장 간단한 예시인 bigram language model을 사용한다.먼저, pytorch를 임포트 해준다.여기서 nn.Embedding(num_embeddings, embedding_dim)이 중요한데,num_embeddings(int
4.[Build GPT-3] Self-attention
이전까지 Model을 만들어내는 것 까지 완료를 했다.그런데 아직 모델은 좋은 생성모델이 아닌 상태. (막무가내 출력)어떻게 좋아지게 만들까..Toy example로 self-attention의 트릭을 살펴보자.먼저 B, T, C 의 데이터를 만들어본다.이전 데이터셋을
5.[Build GPT-4] Residual Block and LayerNorm
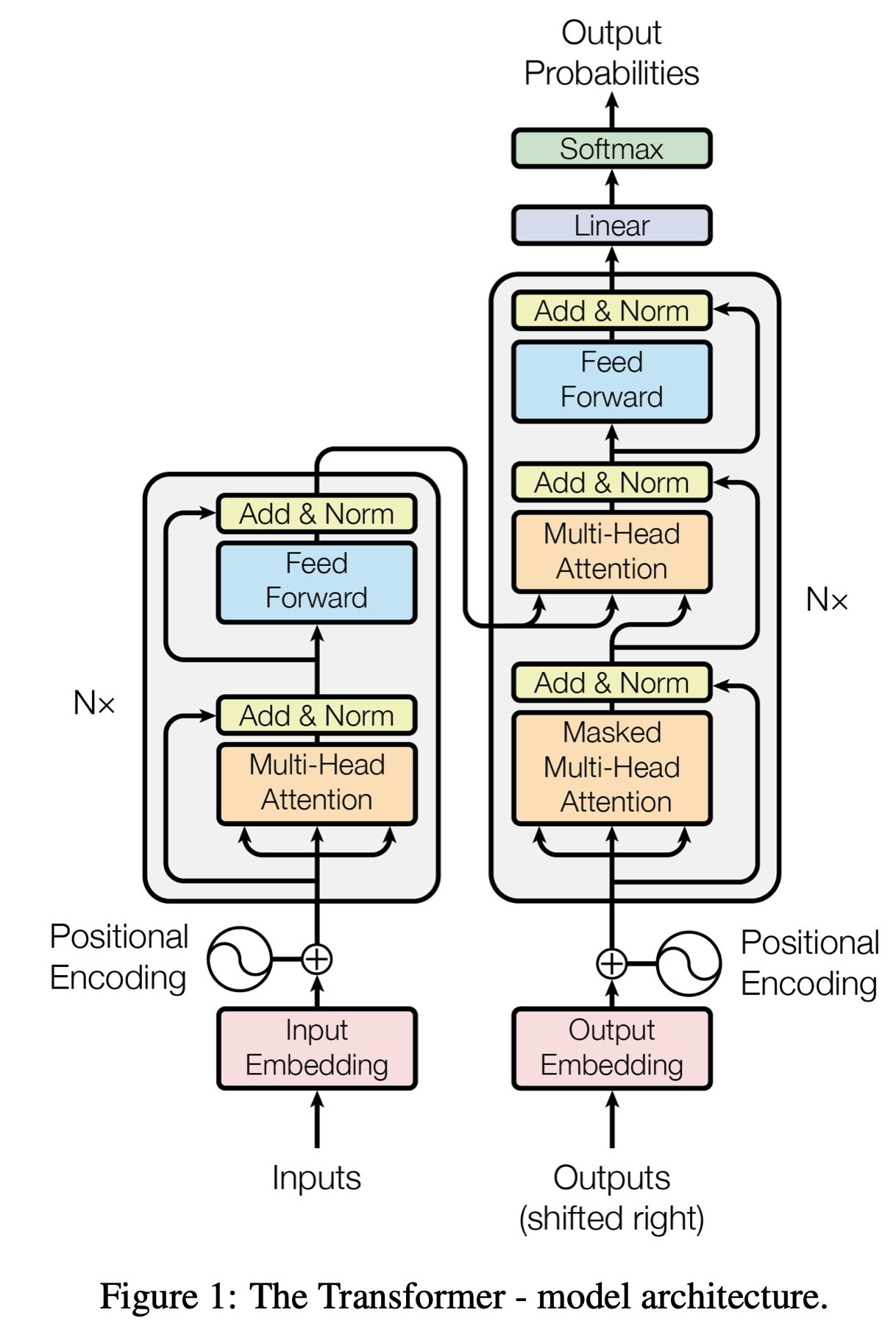
지금까지 위 Transformer Decoder에 위치하는 대부분의 component들에 대해 알아보았다.순서대로 나열해보면Token EmbeddingPositional EmbeddingSelf-AttentionMasked Multi-Head Attention이렇게 알
6.[PEFT] LoRa - Low-Rank Adaptation of Large Language Models
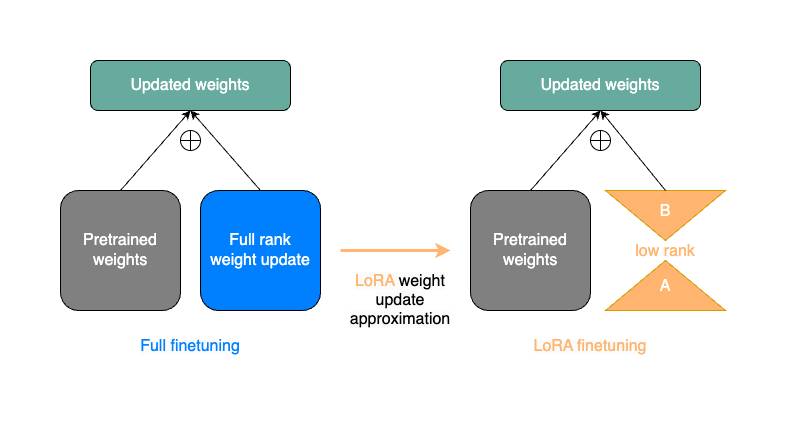
Reference : https://pytorch.org/torchtune/stable/tutorials/lora_finetune.htmlLoRA의 기본적인 아이디어는 pre-trained matrices (i.e. paprameters of the origi
7.[llama3/llama/generation.py][class Llama] def build def __init__
class llama에 대해 알아보자.해당 build 함수는 모델 체크포인트를 로딩하고 initializing해서 Llama instance를 빌드하는 과정.Args:가장 먼저 build가 정의되어 있다.ckpt_dir (str) : checkpoint file이 들어
8.[llama3/llama/model.py][class Transformer] def __init__ and def forward
[llama3/llama/generate.py def build](https://velog.io/@ma-kjh/llama3llamageneration.pyclass-Llama-def-build) 에서 Transformer
9.[llama3/llama/model.py][class TransformerBlock] def __init__, def forward
RMSNorm (Root Mean Square Normalization) is a normalization technique used in the architecture of large language models like LLaMA (Large Language Mod
10.[llama3/llama/tokenizer.py] class ChatFormat
The list.extend() method in Python is used to extend a list by appending all the elements from another iterable (such as another list, tuple, string,
11.[llama3/llama/generation.py][class Llama] def generate
text sequences를 만들어내는 함수.prompt를 입력으로 받아서 텍스트를 만들어냄.prompt_tokens (List\\\[List\\\[int\\]\\]): tokenized된 prompt의 리스트를 의미함. 각 프롬프트는 list of integer를 의
12.[llama3/llama/generation.py][class Llama] def text_completion
bos=True: Ensures the BOS token is added, marking the start of each prompt.eos=False: Ensures the EOS token is not added, allowing the model to contin
13.[llama3/llama/generation.py][class Llama] def sample_top_p
In the context of the sample_top_p function you've provided, "cumulative probability mass" refers to the sum of probabilities for a sequence of tokens
14.[vLLM] GPU utilization
ref : https://sjkoding.tistory.com/91 ( 압도적 감사.)위 링크 들어가면 자세히 설명되어 있습니다.vllm은 대규모 언어 모델의 효율적인 추론을 위해 설계된 library이다. 모델 추론 중에 반복적으로 참조되는 데이터의 캐싱을
15.[Tokenizer]token_embedding
NLP 모델을 학습할 때 tokenizer의 output은 tokenized된 text 꾸러미들이다. (text_embedding이 아님)LLM(대규모 언어 모델)의 가장 앞단에서는 토크나이저의 출력(Token IDs)이 입력으로 사용되며, 이를 임베딩(Embeddin
16.[LLM sampling] token prediction
LLM(대규모 언어 모델)에서 마지막 토큰의 출력을 생성할 때, 다양한 샘플링 기법이 사용됩니다. 이러한 기법은 모델의 출력을 제어하여 보다 자연스럽거나 특정한 특징을 가지는 텍스트를 생성하도록 돕습니다. 아래는 주요 샘플링 기법과 그 예시에 대한 구체적인 설명입니다.