오늘 공유드릴 논문은
Learning to Augment Distributions for Out-of-distribution detection
https://openreview.net/pdf?id=OtU6VvXJue
이라는 논문으로 NeurIPS 2023에서 발표된 논문입니다.
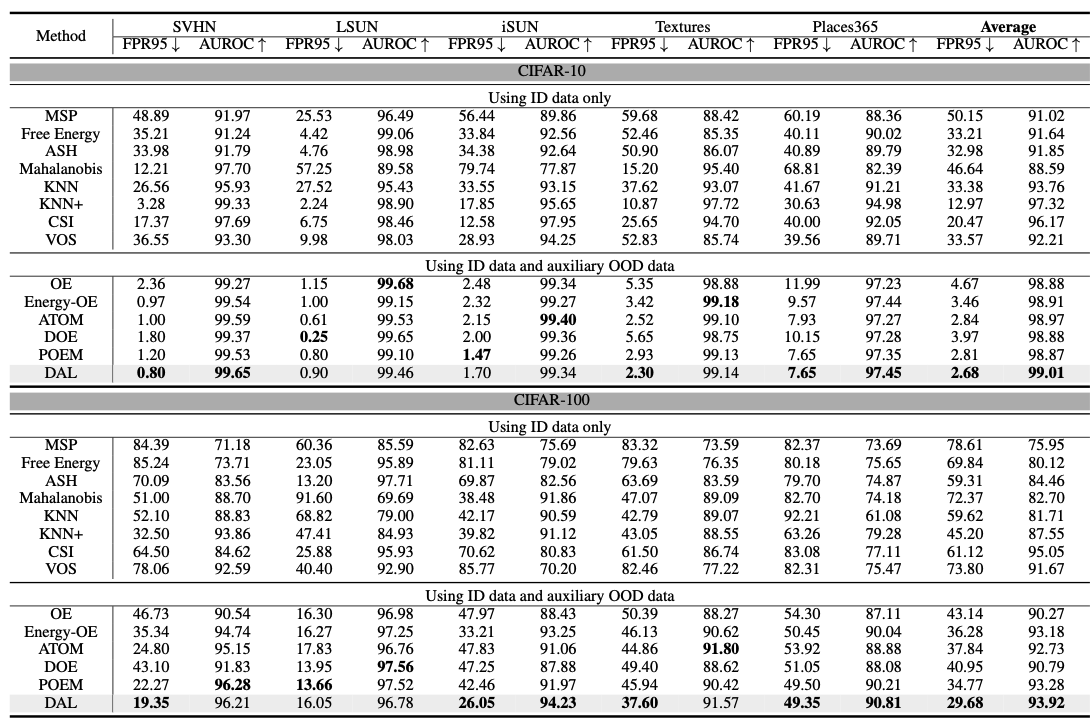
OODD task에서 항상 문제가 되는 것은 unseen data의 부재입니다. 이 논문에서는 특히 Auxiliary OOD data를 가지고 있는 상황에서 Auximilary OOD data 와 unseen real ood와의 distribution discrepancy 를 줄이는 것으로 문제를 해결하고자 합니다.
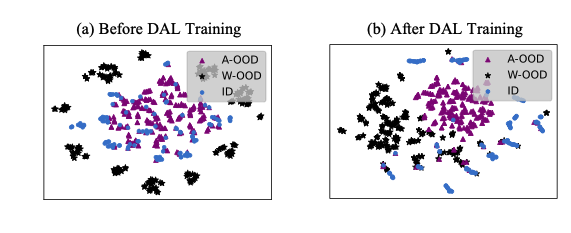
일반적인 outlier exposure의 경우 ID 데이터에 대해서는 classification confidence가 높고, oulier의 경우 낮은 confidence를 내뱉도록 학습을 진행하는데요. 한마디로 OOD data에 대해서 OOD score의 confidence가 낮도록 학습을 진행하여, 이 차이를 통해 OODD를 수행합니다. 그런데, 만약 Auxiliary ood data가 Real OOD Data와 멀게 될 경우 real detection effectiveness(실제 OOD를 탐지하는 성능)이 하락할 수 밖에 없습니다(당연히 Real OOD data에 대한 confidence를 낮추는 작용이 적어질 것임). 이는 자연스럽게 발생하는 문제이기 때문에, 어떻게 이런 실제 OOD와의 distribution discrepancy를 줄일 수 있을까 ? 에 대한 물음에 논문은 다음의 방법으로 문제를 해결합니다.
Real OOD와 Auxiliary OOD data 사이의 distribution discrepancy를 줄이는 방법으로 효과적인 learning framework (Distributional Augmented OOD Learning (DAL))를 제안합니다.
- Distributional Augmented OOD Learning
a. optimization solution을 위한 적절한 data distribution D를 설정해줘야하는데, 이 때 D는 optimization problem을 tractable하게 수행할 수 있어야 하고, auxiliary data에 의해 선택됩니다.
b. 본 논문에서는 Auxiliary data distribution의 Wasserstein ball을 이용해서 D를 설정해주는 방법을 사용합니다. (Auxiliary data distribution 주변 Wasserstein ball 사이의 데이터를 D로 정의) - Predictor가 D에서 worst OOD distribution으로부터 학습하도록 만들어줍니다.
a. worst OOD은 ? -> distribution discrepancy의 부정적인 효과를 가장 줄여주는 sample일 것임, 어떤 의미냐면 Auxiliary data distribution에 대한 ball 안에 존재하는데이터셋 중에서, l_OE값을 가장 크게 만들어주는 sample로 학습을 수행
b. 직관적으로 이해해봤을 때는, Auxiliary OOD data와 멀 경우로 이해
c. 이 때, intractable하기 때문에 feasible surrogate를 제안
d. tractable한 problem으로 바꾸고
e. data search procedure를 embedding space에서 수행