[NeurIPS 2023] Dream the Impossible : Outlier Imagination with Diffusion Models
0
Outlier Synthesis
목록 보기
3/3
https://arxiv.org/pdf/2309.13415.pdf
2023 Neurips에서 poster로 발표된 논문입니다.
간략하게 설명하면 ID data의 embedding을 text-condition으로 이용해 Diffusion model을 통한 Outlier을 생성하여 OoD Detection을 수행하는 Framework를 제안하는 논문입니다.
다음과 같은 방법으로 Outlier를 생성합니다.
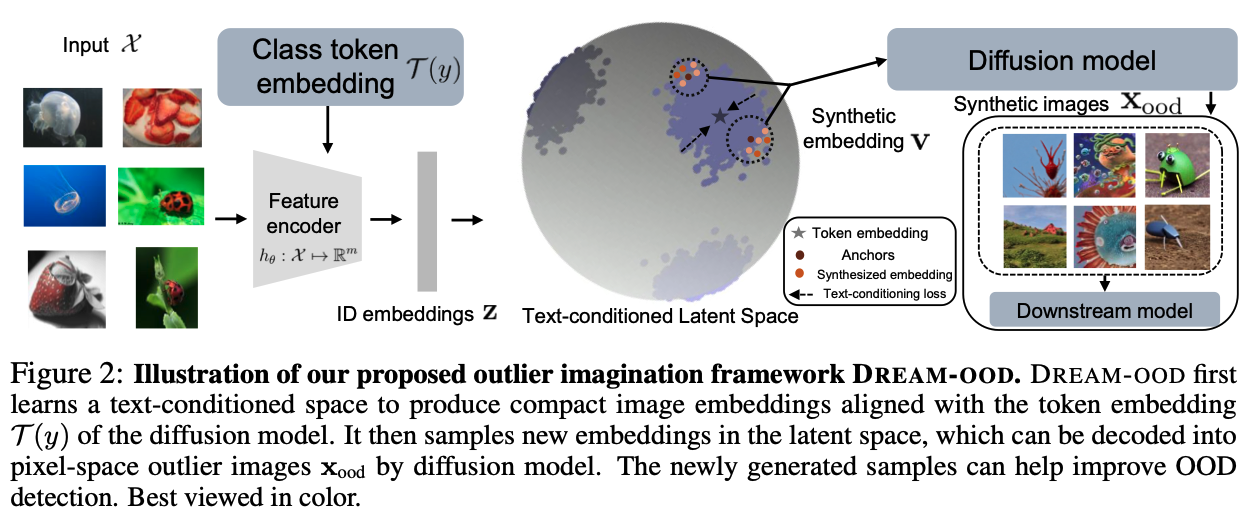
- ID dataset들을 class token embedding(diffusiion model)과 align하는 image embedding으로 만들어주는 classifier를 먼저 학습시킵니다.
a. 학습 방법은 contrastive loss를 사용해서, 각 클래스에 해당하는 토큰 임베딩과 이미지 임베딩이 가까워 지도록 학습 - 그렇게 생성된 ID embedding z를 anchor로 두고 low-likelihood embedding을 샘플링하여 OOD embedding을 샘플링합니다.
a. 위 논문에서는 다양한 방법중 non-parametric sampling method를 사용했다고 함 boundary에 존재하는 ID anchor를 선택하고, 그 주변의 point에 해당되는 새로운 embedding을 추출하는 방법을 사용.
b. 임베딩 상에서 k-th nearest neighbor를 통해 큰 k-NN distance를 가지는 ID data는 boundary에 있을 것이라고 가정
c. boundary의 ID point를 찾았다면, Gaussian kernel을 통해 새로운 embedding sample을 추출. - 이렇게 뽑은 image embedding을 condition으로 diffusion을 통해 샘플을 생성
- 뽑힌 샘플을 사용하여 모델을 학습.
아주 직관적으로 이해하기 쉬운 방식으로 Outlier를 생성하여 OODD 성능을 올린 논문으로, Text-Condition을 ID 이미지와 비슷하지만 boundary에 걸친 embedding을 사용하여 Outlier을 생성함으로써, ID와 의미적으로 비슷하지만 variance를 가지는 OOD data를 생성하여 문제를 해결해낸 논문으로 생각됩니다.
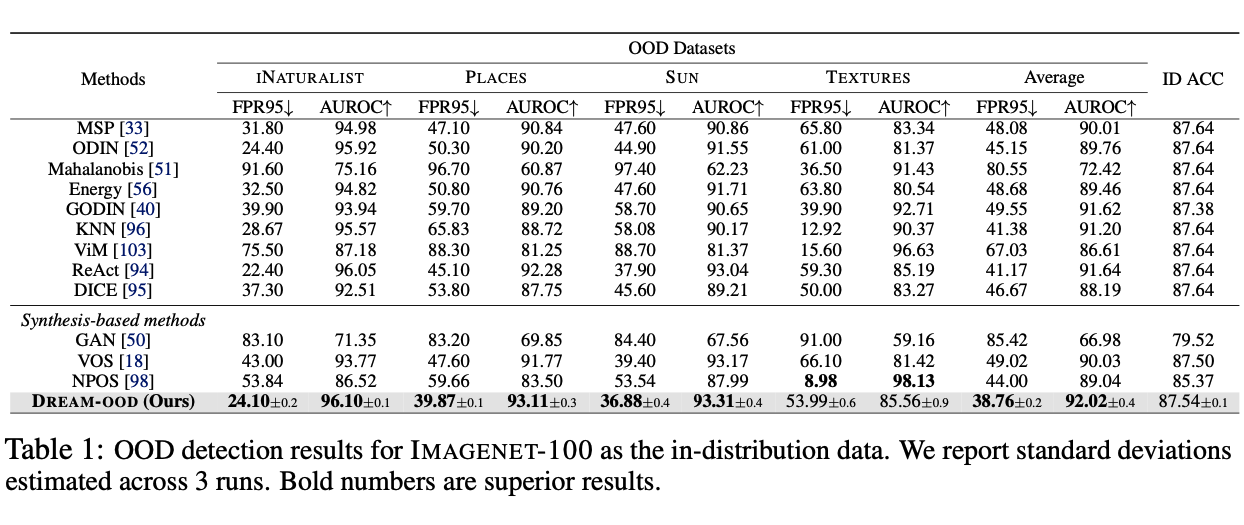
다만 해당되는 OOD image(sampling 하여 얻는)의 variance를 조절할 수 있는 방법이 Gaussian kernel의 sigma하나로, 논문의 저자들은 0.03을 사용했다고 합니다. (너무 커지면 비슷한 이미지가 아닌 아예 다른 이미지가 나와버림)


거인의 어깨에 올라서서 더 넓은 세상을 바라보라 - 아이작 뉴턴