Main Contribution
이 논문에서는 자연스럽고 간단한 방법인 contrastive pre-training 방법을 모방하는 것을 통해 일관적으로 좋은 성능을 내는 fine-tuning 방법론에 대해 소개한다. 이를 통해 위 방법이 image-text model을 fine-tuning하는 "standard" fine-tuning 방법이 될 수 있다는 것을 주장한다.
Introduction
최근 image와 text를 jointly pre-trained하는 large-scale의 모델(CLIP or ALGIN)이 개발되어졌고, zero-shot classification에서 좋은 성능을 보여주고 있다. 이러한 모델들은 image와 text의 엮인 joint embedding을 찾는 방식으로 contrastive loss를 통해 학습이 이뤄진다. 그리고나서, classification problem을 해결하기 위해, 간단하게 prompt를 설정한다. 마지막으로, image들 중에, class에 해당하는 prompt에 해당하는 embedding들의 similarity가 높은 것을 예측한다. 이러한 “zero-shot” classifier는 additional training을 필요로 하지 않고 downstream task에서 좋은 성능을 보이고 또 distribution shift에서 강건한 능력을 보인다.
그러나 대부분의 이전 방법의 경우 경우, supervised fine-tuning을 통해 성능을 향상시킬 수 있다. pre-trained된 parameter로 initialized된 모델을 labeled image를 통해 classification task에서 update하여 성능을 향상시키는 것이다.
그러나 실제로, 여러 연구들에서, standard fine-tuning (일반적으로 Image Encoder의 parameter만을 학습하는) 방법의 경우 in-distribution performance를 올릴 수 있지만, distribution shift에 대한 robustness가 떨어진다는 것을 보였다. fine-tuning process를 위한 정교한 변화를 통해 이러한 robustness의 감소를 줄일 수 있다. 예를들어 Kumar et al. (2022c) 에서는 final linear head의 initialization의 역할에 대해 설명하고 linear probing의 two-stage process에 대해 제안한다, 그리고나서 fine-tuning이 각각의 방법들 보다 낫다는 것을 말했음. 다른 예로 Wortsman et al. (2021a)의 경우 fine-tuned의 weight를 ensembling하는 것을 보여주고, zero-shot classifier가 robustness를 높은 in-distribution performance를 유지한 채 향상시킬 수 있음을 확인한다. 이러한 변화들의 역할을 이해하는 것은 어려운 일이고, 무엇이 “옳은” 방법인지에 대해 얘기하기 어렵다.
이러한 연구들의 공통적인 주제는 standard supervised training paradigm (minimize-cross-entropy-loss)에서 small change를 통해 문제를 해결했다는 점이다. 사실 이러한 선택은 natural precisely한데, 왜냐면 fine-tuning system은 classification performance를 향상시키기 위함이기 때문다. 그러나 pretraining process에 대한 고려없이 직접적으로 supervised learning 방법을 적용하는 것은 sub-optimal이다.
이 논문에서는 이러한 이전 방법들을 능가하는 직관적인 방법론을 대안으로 제안한다. 특히, classifier를 same pre-training loss를 통해 fine-tuning하는 방법이 classifier의 결과를 일관성있게 좋게 만들어 준다는 것을 보여준다. 즉, class label로 부터의 prompt를 형성하고, 직접적으로 이러한 prompt에 대해 image embedding과 text embedding의 contrastive loss를 minimize하는 것이다. 이를 Fine-tuning like you pretrain (FLYP)라고 부르며, 아래 그림과 정리한다. FLYP는 better ID와 OOD performance를 다른 방법들과 비교하였을 때 가진다. 이러한 contrastive fine-tuning은 class가 minibatch에서 겹치는 것을 무시하고, multiple prompt를 같은 class에 대해 사용한다.
Preliminaries
Task : image classification 셋팅은 image 를 label 에 매핑하는 것을 목표로 한다.
논문에서는 image-text pretrained model인 CLIP의 joint embeddings of image, text에 학습한다.
는 image encoder를 의미하며, 이 때 image-text embedding space는 -dimension을 가진다. 는 파라미터 에 의하여 파라미터화 된다. 는 image의 text description space를 의미하며, 는 model parameter 에 파라미터화 된 language encoder를 의미한다.
Contrastive pre-training with language supervision
pretraining objective는 contrastive learning이다. 이는 image embedding 와 text embedding 를 align하는 것을 목표로하며, 에 해당하는 배치안의 negative text(일치하지 않는 텍스트)는 멀리 보내버린다. 배치를 가지는 이미지에 대하여
데이터가 있을 때, pretraining objective는 다음과 같다.
는 각각 image와 text encoder의 파라미터를 의미하며, 와 는 normalized version의 와 이다. 즉, norm으로 normalized된 값. CLIP의 pretraining objective와 완전히 동일하며, 1개의 이미지에 대해 개의 클래스들에 대한 text embedding들을 classificaiton하는 task로 볼 수 있다.

Fine-tuning pretrained models
few training sample에 해당하는 를 가지고, downstream image classification task를 수행하려고 함.
- Zero-shot (ZS) : without updating any weights. 개의 클래스의 이름들 에 대해, text description 들을 만들어냅니다. (”a photo of a ”). zero-shot prediction은 이미지 에 상응하는 , 를 답으로 예측하고, 여기서 는 아까 언급했던 것 과 같음. 이를 다음과 같이 표현할 수 있다. where 는 zero-shot linear head로 ,text description 에 해당하는 클래스들에 상응하는 column을 가지고 있다.
- Linear probing (LP) : linear classifier 를 frozen 된 image embdding 위에 쌓아서 downstream distribution으로부터 얻은 labeled data에 대해 cross entropy loss를 minimize하여 형성한다.
- Full fine-tuning (FFT) : In full fine-tuning, 은 linear head 그리고 parameter 에 대해 pretrained value로 초기화 한뒤 cross entropy loss를 minimize한다. 이 때, random 하게 linear head를 초기화 하는게 아니라, 의 weight를 초기화해준다.
- LP-FT : two-stage fine-tuning으로 , linear probing을 먼저 진행한 후에, full fine-tuning을 first-stage에서 얻은 linear head를 가지고 학습을 진행
- Weight-ensembling : ensemble the weights by linearly interpolating between the weights of the zero-shot model and a fine-tunged model. Let denote the pretrained weights of the image encoder, and denote the finetuned weights. Then weights of weight ensembled model are given as :
Experiments
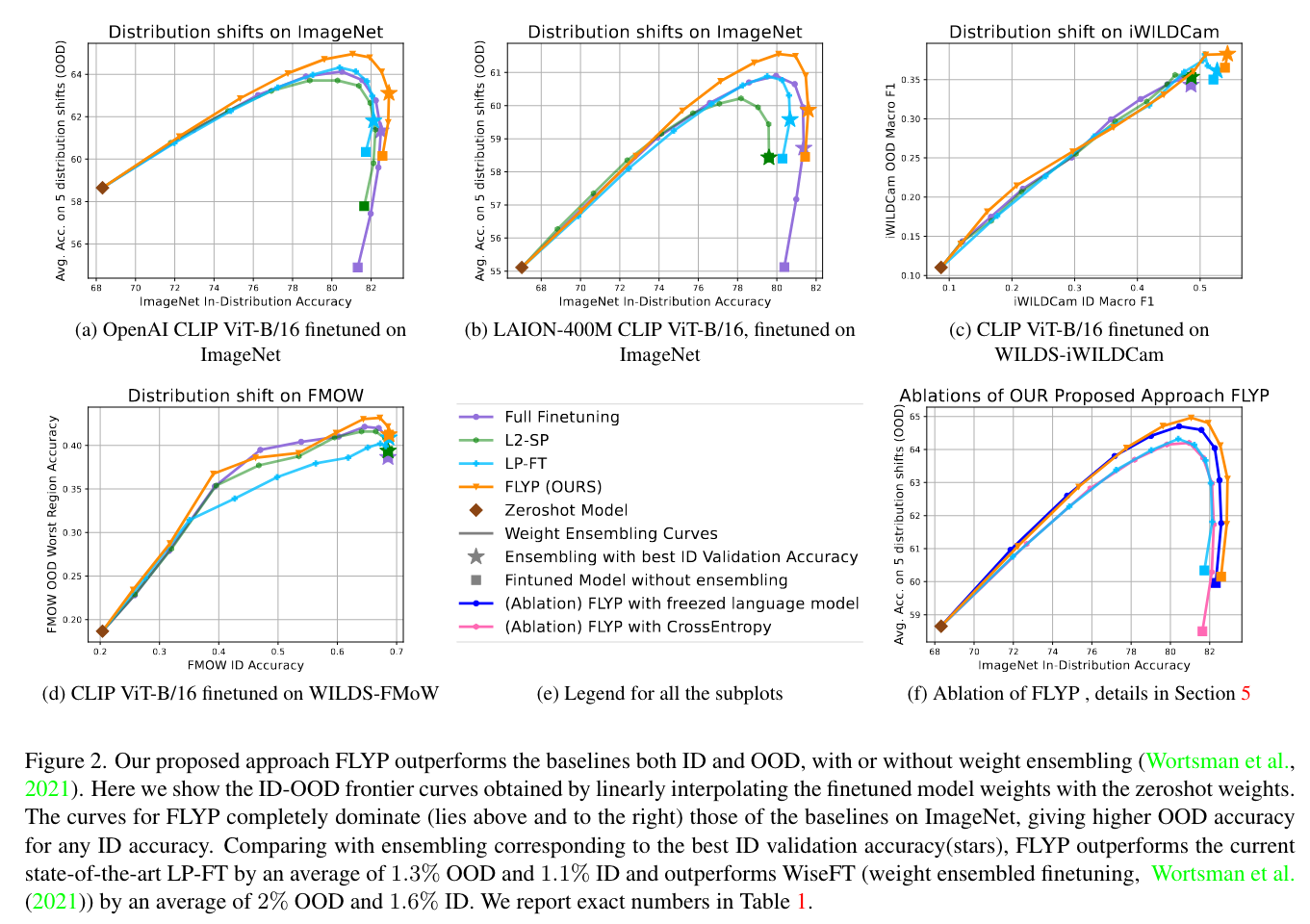
ID와 OoD accuracy가 모두 좋더라.
Ablations : Why does FLYP improve performance ?
이 논문에서 아마 가장 contribution을 가지고 있는 장이라고 볼 수 있다. 논문의 저자들은 FLYP fine-tuning 방법이 잘되는 이유를 exactly matches the pretraining이기 때문이라고 주장한다.
1. Class Collisions ( batch 내에 같은 class가 존재하는 것 )이 성능에 거의 영향을 주지 않는다.
2. FLYP는 이미지 인코더 뿐만 아니라 텍스트 인코더의 파라미터를 학습한다.
3. Cross-Entropy loss 대신에 Contrastive-loss를 사용한다.
4. prompts를 sampling하여 추가적인 stochasticity를 fine-tuning process에 입힌다.
