정보처리기사 실기
📝 2024년 1회차 기출, 1️⃣1️⃣ ~ 1️⃣5️⃣
11. C Lang. - 구조체와 곱셈 산술연산
#include <stdio.h>
typedef struct{
int accNum;
double bal;
}BankAcc;
double sim_pow(double base, int year){
int i;
double r = 1.0;
for (i=0; i< year; i++){
r = r*base;
}
return r;
}
void initAcc(BankAcc* acc, int x, double y){
acc -> accNum = x;
acc -> bal = y;
}
void xxx(BankAcc* acc, double *en){
if (*en > 0 && *en < acc -> bal) {
acc -> bal = acc -> bal - *en;
}
else {
acc -> bal = acc -> bal + *en;
}
}
void yyy(BankAcc* acc){
acc -> bal = acc -> bal * sim_pow((1+0.1),3);
}
int main(){
double amount = 100.0;
BankAcc myAcc;
initAcc(&myAcc, 9981, 2200.0);
xxx(&myAcc, &amount);
yyy(&myAcc);
printf("%d and %.2f", myAcc.accNum, myAcc.bal);
return 0;
}🖍 9981 and 2795.10
accNum= 9981bal= 2200.0
→xxx():2200.0 - 100.0= 2100.0
→yyy():2100.0 * sim_pow(1.1, 3)=2100.0 * 1.331= 2795.1
- typedef 키워드 : 이미 존재하는 타입에 새로운 이름을 붙일 때 사용.
구조체 변수를 선언하거나 사용할 때에는 매번 struct 키워드를 사용하여 구조체임을 명시해야 하지만, typedef 키워드를 사용하여 구조체에 새로운 이름을 선언하면 매번 struct 키워드를 사용하지 않아도 됨.C언어 주요 서식 문자열
%d: 정수형 10진수의 입∙출력에 사용%o: 정수형 8진수의 입∙출력에 사용%x: 정수형 16진수의 입∙출력에 사용%c: 문자의 입∙출력에 사용%s: 문자열의 입∙출력에 사용%f: 소수점을 포함한 실수의 입∙출력에 사용 (출력 시 소수점 이하는 기본적으로 6자리가 출력됨)

12. Python Lang.
a = ["Seoul", "Kyeonggi", "Incheon", "Daejun", "Daegu", "Pusan"]
str01 = "S"
for i in a:
str01 = str01 + i[1]
print(str01)🖍 Seynaau
최초의 대문제 S에서 뒤에 오는 것을 더해서 출력.
리스트의 각 요소들을 빼와서 1번 인텍스(2번째 문자)를 가져옴.
13. SQL
다음 SQL문을 해당하는 테이블을 작성하시오.
SELECT B
FROM R1
WHERE C IN (SELECT C FROM R2 WHERE D = 'k');<R1>
| A | B | C |
|---|---|---|
| 1 | a | x |
| 2 | b | x |
| 1 | c | w |
| 3 | d | w |
<R2>
| C | D | E |
|---|---|---|
| x | k | 3 |
| y | k | 3 |
| z | s | 2 |
🖍
WHERE 조건문 :SELECT C FROM R2 WHERE D = 'k'의 결과


14. 테스트 커버리지
- 개별 조건식이 다른 조건식의 영향을 받지 않고 전체 조건식의 결과에 독립적으로 영향을 주는 테스트케이스 도출 구조적 테스트 기법
- 개별 조건식이 전체 조건식의 결과에 영향을 주는 조건 조합을 찾아 커버리지를 테스트하는 방법
🖍 MC/DC(Modified Condition/Decistion Coverage, 변형 조건/결정 커버리지)
MC/DC는 개별 조건식이 다른 개별 조건식에 영향을 받지 않고 전체 조건식에 독립적으로 영향을 주도록 함으로써 조건/결정 커버리지를 향상시킨 커버리지이다.
- DC(Decision Coverage) : Branch Coverage라고도 하며, 소스 코드의 모든 조건문에 대해 조건식의 결과가 True인 경우와 False인 경우가 한 번 이상 수행되도록 테스트 케이스를 설계.
- CC(Condition Coverage) : 소스 코드의 조건문에 포함된 개별 조건식의 결과가 True인 경우와 False인 경우가 한 번 이상 수행되도록 테스트 케이스 설계.
- C/DC(C/D Coverage) : 전체 조건식뿐만 아니라 개별 조건식도 True 한 번, False 한 번 결과가 되도록 수행하는 테스트 커버리지.
- SC(Statement Coverage) : 소스 코드의 모든 구문이 한 번 이상 수행되도록 테스트 케이스를 설계
- MCC(Mutiple Conditon Coverage) : 결정 조건 내 모든 개별 조건식의 모든 가능한 조합을 100% 보장하는 커버리지
- https://velog.io/@m_ngyeong/Application-Testing
15. C Lang. - 시저 암호/카이사르 암호 알고리즘
#include <stdio.h>
#include <string.h>
void isUpper(char *str);
void isLower(char *str);
void isNum(char *str);
char str[] = "It is 8";
int main() {
int i = 0;
while(i<strlen(str)){
char ch = str[i];
if(ch >= 'A' && ch <= 'Z'){
isUpper(&str[i]);
}
else if(ch >= 'a' && ch <= 'z'){
isLower(&str[i]);
}
else if(ch >= '0' && ch <= '9'){
isNum(&str[i]);
}
i++;
}
printf("%s", str);
return 0;
}
void isUpper(char *str){
*str = (*str - 'A' + 5) % 26 + 'A';
}
void isLower(char *str){
*str = (*str - 'a' + 10) % 26 + 'a';
}
void isNum(char *str){
*str = (*str - '0' + 3) % 10 + '0';
}🖍 Nd sc 1
- ASCII Code에 따라 문자를 계산할 수 있음. (https://www.ascii-code.com/)
'0': 48 ~ '9': 57, 'A': 65, 'a': 97
❶('I' - 'A' + 5) % 26 + 'A';
= (73 - 65 + 5 ) % 26 + 65
= (8 + 5) % 26 + 65 = 13 + 65
= 78
∴ N
❷('t' - 'a' + 10) % 26 + 'a';
= (116 - 97 + 10) % 26 + 97
= (19 + 10) % 26 + 97 = 3 + 97
= 100
∴ d
❸('i' - 'a' + 10) % 26 + 'a';
= (105 - 97 + 10) % 26 + 97
= (8 + 10) % 26 + 97 = 18 + 97
= 115
∴ s
❹('s' - 'a' + 10) % 26 + 'a';
= (115 - 97 + 10) % 26 + 97
= (18 + 10) % 26 + 97 = 2 + 97
= 99
∴ c
❺('8' - '0' + 3) % 10 + '0';
= (56 - 48 + 3) % 10 + 0 = 11 % 10
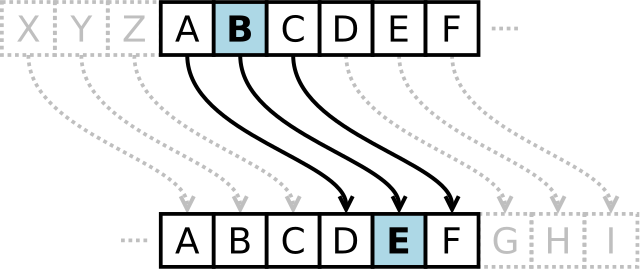
= 1시저 암호/카이사르 암호(Caesar cipher) 알고리즘
암호화하고자 하는 내용을 알파벳별로 일정한 거리만큼 밀어서 다른 알파벳으로 치환하는 방식의 알고리즘을 말한다.
[이미지 참고: https://ko.wikipedia.org/wiki/카이사르_암호]
- 카이사르 암호는 각각의 알파벳을 일정한 거리만큼 밀어 글자를 치환하는 방식으로 암호화한다. 위 예제에서는 3글자씩 밀어서 암호화하기 때문에
B는E로 치환됨.


참고,
기출 문제 : https://newbt.kr/시험/정보처리기사%2520실기
길벗알앤디. 『정보처리기사 실기 단기완성』. 길벗. 2023.
https://youtu.be/0sWcTYhi0MQ?si=8BR39eZjgtSyzg3x
https://cafe.naver.com/soojebi
구조체 : https://www.tcpschool.com/c/c_struct_intro
https://youtu.be/OObXMmXchEk?si=V5hQpF2Pa8ynzjKn

ʚȉɞ