
SQLd : 2024년 54회 기출 복원
Q. 과목 1
1. '시스템을 구축하고자 하는 업무에 대해 Key, 속성 관계 등을 정확하게 표현, 재사용성이 높은 것'은?
논리적 데이터 모델링
2. 엔터티에 특징으로 적절하지 않은 것은?
속성이 없는 엔터티가 있을 수 있다.
(엔터티는 반드시 속성이 있어야 한다.)
SQL 전문가 가이드 p.39
3. 속성의 특정으로 적절하지 않은 것은?
파생이 많을수록 좋다.
4. 식별자의 특징으로 적절하지 않은 것은?
주식별자의 값은 변경될 수 있다.
5. 식별자관계에 대한 설명으로 적절하지 않은 것은?
비식별자관계에서 부모와의 관계는 필수 조건이다.
6. 고객, 주문 관련 ERD 에 대한 설명으로 적절한 것은?
주문번호의 고객번호는 곡개 엔터티에서 상속받은 것이다.
7. 함수 종속성에 대한 설명으로 적절한 것은?
일반 속성이 주식별자에 모두 함수종속성이 있는 상태 : 제2정규형
상품번호에 상품명이 종속 → 상품명은 상품번호에 종속 (틀림)
8. '업무적으로 만들어지지는 않지만 원조식별자가 복잡한 구성을 갖고 있기 때문에 인위적으로 만든 식별자'는?
인조 식별자
9. 트랜잭션에 대한 설명으로 적절하지 않은 것은?
IE 실선, 바커 O표시를 사용하지 않는것으로 표현
(IE: O표시, 바커: 실선)
10. Null 대한 설명으로 적절하지 않은 것은?
(1) IE 에서 가능? 바커 불가능 : (맞음)
(2) NULL은 미지의 값이므로 비교 불가하다 : (맞음. 비교는 불가하나 연산자로 NULL이냐 아니냐는 판단 가능)
(3) NULL에는 연산자를 사용할 수 없다 : (틀림. SQL 연산자 "IS NULL"이 있음)
Q. 과목 2
11. CTAS 에 대한 설명으로 적절하지 않은 것은?
제약조건이 모두 복사된다.
(제약 조건 모두가 복사되지 않음)
12. View 에 대한 설명으로 적절하지 않은 것은?
컬럼 추가가 되더라도 View 를 변경하지 않아 응용프로그램 변경이 없다.
13. DATABASE 의 논리적 업무 최소 단위는?
트랜잭션
(트랜잭션을 구성하는 단위가 Query이며 트랜잭션은 분할할 수 없는 최소의 단위다.)
14. 정규형에 대한 값이 나오지 않는 것은?
[보기] 전화번호(3,4,- 있는 형태)
02)로 시작하는 형태
15. 계층형 쿼리와 결과에 대한 설명으로 적절하지 않은 것은?
역방향이다.
(Prior emp_no = mgr_no --> 순방향)
16. 서브쿼리에 대한 설명으로 적절하지 않은 것은?
(1) 1:M 에 관계일 때 M 레벨로 집계된다.
(2) 서브쿼리의 컬럼은 메인 쿼리에서 사용할 수 없다.
17. SQL 에 대한 결과와 같은 것은?
... case when col1 = 'X' then null else col1nullif (col1,'x')
18. SQL의 결과가 다른 것은? (Oralce에 한함)
①
SELECT COL1,COL2,COL3
FROM TAB
WHERE COL1 < 5;
② SELECT T.*
FROM TAB AS T
③ SELECT *
FROM TAB
④
SELECT *
FROM TAB
WHERE COL2 IN (2,3)②, 오라클에서는 FROM절에 'AS' 키워드 사용 불가
19. SQL로 작성한 것중 적절하지 않은 것은?
<지문> STADIUM 관련 설명
SELECT ..., STADIUM ...STADIUM 은 두개 테이블이 존재하므로 테이블명 표시가 필요함
20. SQL에 대한 결과로 알맞은 것은? (COALESCE 문제)
SELECT ... , COALESCE (A, 50*B, '50')
22. INNER JOIN 관련 문제
KIM,KIM 중복으로 나옴
23. LEFT OUTER JOIN 문제
SMITH ROW 가 NULL 인 문제
24. 행의 수가 가장 많은 SQL은?
CREATE TABLE TAB1
( CODE NUMBER NOT NULL,
PCOLOR VARCHAR(10) NOT NULL);
INSERT INTO TAB1 (CODE, PCOLOR)
VALUES (1, '빨강');
INSERT INTO TAB1 (CODE, PCOLOR)
VALUES (2, '노랑');
INSERT INTO TAB1 (CODE, PCOLOR)
VALUES (3, '파랑');
INSERT INTO TAB1 (CODE, PCOLOR)
VALUES (4, '검정');
CREATE TABLE TAB2
( CODE NUMBER NOT NULL,
PSIZE VARCHAR(10) NOT NULL);
INSERT INTO TAB2 (CODE, PSIZE)
VALUES (1, '소');
INSERT INTO TAB2 (CODE, PSIZE)
VALUES (2, '중');
INSERT INTO TAB2 (CODE, PSIZE)
VALUES (3, '대');
INSERT INTO TAB2 (CODE, PSIZE)
VALUES (4, '특대');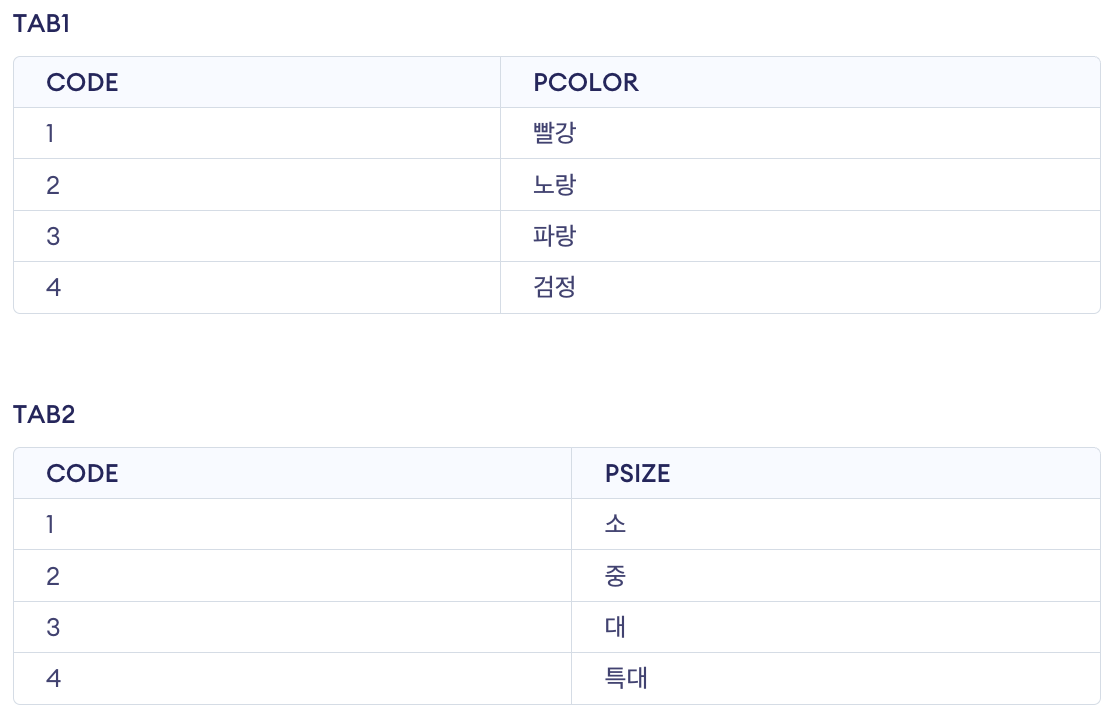
①
SELECT CODE
FROM TAB1
UNIOR ALL
SELECT CODE
FROM TAB2;
②
SELECT *
FROM TAB1 * TAB2
WHERE TAB1.CODE = TAB2.CODE;
③
SELECT *
FROM TAB1, TAB2
WHERE TAB1.PCOLOR
IN ('노랑','파랑','검정')
AND TAB1.PCOLOR IN('소','중','대');
④
SELECT *
FROM TAB1 FULL OUTER JOIN TAB2
ON TAB1.CODE = TAB2.CODE;③
①, ②, ④의 행수는 8개이고, ③의 행수는 9개로 다른 구문보다 1개 많음.
FROM절에table * table은 존재하지 않음(Oracle에서 에러 발생)
25. 제약 조건에 대한 설명으로 적절하지 않은 것은?
UK 는 NOT NULL 이다.
26. 아래의 SQL과 같은 SQL은? (IN - EXISTS 전환 문제)
WHERE 번호 IN (SELECT 번호 FROM ... WHERE A.성별 = B.성별)EXISTS (SELECT 'X' FROM ... WHERE A.성별 = B.성별 AND A.번호 = B.번호)
27. SQL 결과로 알맞은 것은?
SELECT COUNT(*)
FROM ...
WHERE ... NOT IN (SELECT COL1 FROM ... ) --COL1에 NULL이 포함됨0
28. SQL 결과로 알맞은 것은? (IN - NULL 조건)
<SQL>
SELECT ...
FROM ...
WHERE ... IN ( 'A','B',NULL)'A', 'B' 만 만족하는 로우
29. SQL 결과로 알맞은 것은? (나이 - 평균)
[Table]
| 나이 |
|---|
| 10 |
| 20 |
| 20 |
| 30 |
| 30 |
SELECT AVG(나이) ...10,10,15
30. GROUPING SET 문제
DATA: COL1, COL2 집계
COL2: NULL이 있는 집계
GROUPING SET((COL1, COL2), COL2)
31. Window Function
파티션별 윈도우의 전체 건수에서 현재 행보다 작거나 같은 건수에 대한 누적 백분율을 구하는 함수
cume_dist
32. Window Function
연봉은 오름차순, -100 ~ 200 사이의 연봉자 수 구하기
SELECT employee_id,
first_name,
salary,
( )
FROM hr.employees
WJERE 1=1 AND department_id = 30
ORDER BY salaryCOUNT(*) OVER(PARTITION BY department_id ORDER BY salary RANGE BETWEEN 100 PRECEDING AND 200 FOLLOWING)
33. SQL에서 7783번의 결과는? (ROW_NUMBER, RANK, DENSE_RANK)
[TABLE]
...
SELECT ROW_NUMBER..
RANK..
DENSE_RANK..4, 4, 3
34. 강좌번호가 100, 101 인 과목을 동시에 듣는 학번을 구하는 SQL로 알맞은 것은?
① ... WHERE 강의번호 = 100 AND 강의번호 = 101
② SELECT ... INTERSECT ...
③ ... WHERE 강의번호 IN(100,101)
④ ... WHERE 강의번호 = 100 OR 101②, 교집합
35. 아래의 결과를 출력하는 SQL의 빈칸에 적절한 것은? (SELF JOIN 으로 등수 구하기)
SELECT 이름,
점수,
(SELECT ( ① )
FROM t1 t2
WHERE ( ② ) AS 순위
FROM t1
ORDER BY 순위;① COUNT( * )+1, ② T1.점수 < T2.점수
36. 행이 2건인 테이블에서 결과가 다른 SQ 은?
SELECT .. .FROM ... WHERE .. ROWNUM = 2
(ROWNUM = 2는 데이터 0건 발생)
37. SQL에 대한 설명으로 알맞은 것은? (UPDATE 구문)
CREATE TABLE emp_test AS select * from hr.employees;
UPDATE emp_test a SET salary =
(SELECT salary * 1.1 FROM emp_test b
WHERE a.employee_id = b.employee_id
AND b.department_id = 60);
SELECT * FROM emp_test WHERE department_id = 90;[보기]
① DEPTNO가 10인 사원들의 월급을 10% 인상하는 쿼리이다
② UPDATE ...WHERE DEPTNO = 10과 동일한 의미이다
③ 오류가 발생한다
④ DEPTNO가 10이 아닌 모든 사원들의 월급이 NULL로 수정된다
④
38. TABLE에 대한 SQL 수행 시 최종 결과는? (제약 조건 체크)
[TABLE]
COL1 PK
COL2 CHECK > 500
INSERT ....
UPDATE .... (CHECK 조건 위반)
INSERT .... (PK 조건 위반)
INSERT ....
SELECT SUM(..)770
39. 아래의 SQL 결과로 알맞은 것은?
SELECT COL1,
SUM(매출) 총매출
FROM ...
GROUP BY COL1
ORDER BY 총매출부서2 11300
부서1 18000
40. SQL에 대한 결과로 알맞은 것은? (NULL + 집계 연산)
[TABLE]
...
SELECT COL1, MIN(COL2), MAX(COL2), SUM(COL2+ COL3)
...NULL NULL NULL NULL
41. 입력, 수정, 삭제한 데이터에 대해 전혀 문제가 없다고 판단됐을 경우 ( ) 명령어로 트랜잭션을 완료할 수 있다.
COMMIT
43. 테이블의 데이터와 종속된 테이블을 지우는 명령어로 알맞은 것은?
DROP / CASCADE
44. SQL 에 대한 결과로 알맞은 것은?
SELECT CASE WHEN ...
ELSE '취급안함' ..
FROM ...취급안함 나오는 보기
45. SQL에 대한 설명으로 알맞은 것은? (LIKE 문제)
SELECT .. FROM . WHERE COL1 LIKE 'A%'대문자 A로 시작하는 모든 ROW
46. SQL 결과를 출력하는 SQL로 알맞은 것은?
[DATA]
| COL1 | COL2 |
|---|---|
| 1 | NULL |
| 2 | 1 |
| 3 | 2 |
LAG
47. SQL의 결과로 알맞은 것은? (집계 Count 결과)
SELECT COUNT(*) + COUNT(col1) + COUNT(DISTINCT col2)
FROM ...5+3+2 = 10
48. 단일행 함수에 대한 설명으로 적절하지 않은 것은?
[보기]
① 각 행에 개별적으로 적용된다.
② 여러 인자를 넣을 수 있다.
③ 중첩 사용이 가능하다.
④ GROUP BY에 사용할 수 없다.
④, GROUP BY에 사용 가능함
49. Inner join에 대한 설명 중 적절하지 않은 것은?
조인으로 사용되는 컬럼은 컬러명이 반드시 컬럼명이 같아야 한다.
50. SQL에 대한 결과로 알맞은 것은? (Inner join 후 각 테이블에 대한 조건 체크)
[T1]
| COL1 | COL2 | COL3 |
|---|---|---|
| 가 | A | 2 |
| 나 | B | 3 |
| 다 | C | NULL |
[T2]
| COL1 | COL2 |
|---|---|
| 2 | A |
| 3 | C |
CREATE TABLE T1(
COL1 VARCHER(5) NOT NULL,
COL2 VARCHER(5) NOT NULL,
COL3 NUMBER NULL);
INSERT INTO T1(COL1,COL2,COL3)
VALUES ('가','A',2);
INSERT INTO T1(COL1,COL2,COL3)
VALUES ('나','B',3);
INSERT INTO T1(COL1,COL2,COL3)
VALUES ('다','C',NULL);
CREATE TABLE T2(
COL1 NUMBER NOT NULL,
COL2 VARCHER(5) NOT NULL);
INSERT INTO T2(COL1,COL2)
VALUES (2,'A');
INSERT INTO T2(COL1,COL2)
VALUES (3,'C');
SELECT *
FROM T1 INNER JOIN T2 ON T1.COL2 = T2.COL2
WHERE 1=1
AND T1.COL3 >= 3
AND T2.COL2 IN ('A','B')SELECT * FROM T1 INNER JOIN T2 ON T1.COL2 = T2.COL2
WHERE 1=1 AND T1.COL3 >= 3


참고,
https://yunamom.tistory.com/388
SQLOnline Compiler : https://www.programiz.com/sql/online-compiler
