
II. SQL 기본 활용
제 1장 SQL 기본 - 개념
문자형 함수
SUBSTR('ABCDE', '-4', 3) → BCDE
INSTR('A#B#C#', '#', 3, 2) → 6 (세번째부터 두번째 발견된 #위치)
-- 다른 문자 사이에 있는 지정 문자는 제거되지 않음
LTRIM('xxYYZZxYZxx', 'x'); → YYZZxYZxx
RTRIM('xxYYZZxYZxx', 'x'); → xxYYZZxYZ
TRIM('xxYYZZxYZxx', 'x'); → YYZZxYZ
case문
예제1)
SELECT DEPTNO,
CASE DEPTNO WHEN 10 THEN '인사부'
CASE DEPTNO WHEN 20 THEN '총무부'
CASE DEPTNO WHEN 20 THEN '재무부'
ELSE '기타'
END AS DNAME1,
-- 동일한 대상의 조건이면서 조건이 동등(=)일 경우 위의처럼 축약 가능
CASE WHEN DEPTNO = 10 THEN '인사부'
WHEN DEPTNO = 20 THEN '총무부'
WHEN DEPTNO = 20 THEN '재무부'
ELSE '기타'
END AS DNAME2,
FROM EMP예제2)
-- 검색 CASE 표현식
SELECT LOC,
CASE WHEN LOC = 'NEW YORK' THEN 'EAST'
ELSE 'ETC'
END as AREA,
FROM DEPT;
-- 단순 CASE 표현식
-- 동일한 대상의 조건 & 조건이 동등(=)일 경우 축약 가능
SELECT LOC,
CASE LOC WHEN 'NEW YORK' THEN 'EAST'
ELSE 'ETC'
END as AREA,
FROM DEPT;
-- DECODE
SELECT LOC,
DECODE(LOC, 'NEW YORK', 'EAST', 'ETC')
as AREA,
FROM DEPT;ORDER BY절
SELECT 칼럼명 [ALIAS명]
FROM 테이블명
[WHERE 조건식]
[GROUP BY 칼럼(Column)이나 표현식]
[HAVING 그룹조건식]
[ORDER BY 칼럼(Column)이나 표현식 [ASC|DESC]];제 1장 SQL 기본 - 문제
문제 9.
CREATE TABLE TAB_A
( COL1 NUMBER NULL,
COL2 NUMBER NULL,
COL3 NUMBER NULL);
INSERT INTO TAB_A (COL1, COL2, COL3)
VALUES (30, NULL, 20);
INSERT INTO TAB_A (COL1, COL2, COL3)
VALUES (NULL, 50, 10);
INSERT INTO TAB_A (COL1, COL2, COL3)
VALUES (0, 10, NULL);
-- 문제
SELECT SUM(COL2) + SUM(COL3) FROM TAB_A;
SELECT SUM(COL2) + SUM(COL3) FROM TAB_A WHERE COL1 > 0;
SELECT SUM(COL2) + SUM(COL3) FROM TAB_A WHERE COL1 IS NOT NULL;
SELECT SUM(COL2) + SUM(COL3) FROM TAB_A WHERE COL1 IS NULL;[TAB_A]
| COL1 | COL2 | COL3 |
|---|---|---|
| 30 | NULL | 20 |
| NULL | 50 | 10 |
| 0 | 10 | NULL |
수행결과:
SELECT SUM(COL2) + SUM(COL3) FROM TAB_A; /* COL2의 NULL과 COL3의 NULL은 SUM연산 대상에서 제외됨. ∴ (50+10) + (20+10) = 90 */
COL2 COL3 NULL 20 50 10 10 NULL
SELECT SUM(COL2) + SUM(COL3) FROM TAB_A WHERE COL1 > 0; /* COL1이 NULL인 두 번째 행은 NULL 연산 제외 조건으로 0인 세 번째 행은 0>0 조건으로 연산 대상에서 제외됨. ∴ NULL + 20 = NULL */
COL1 COL2 COL3 30 NULL 20
SELECT SUM(COL2) + SUM(COL3) FROM TAB_A WHERE COL1 IS NOT NULL; /* COL1이 NULL인 두번 째 행은 NOT NULL 조건으로 제외됨. ∴ 10 + 20 = 30 */
COL1 COL2 COL3 30 NULL 20 0 10 NULL
SELECT SUM(COL2) + SUM(COL3) FROM TAB_A WHERE COL1 IS NULL; ∴ 50 + 10 = 60
COL1 COL2 COL3 NULL 50 10
문제 11.
CREATE TABLE 서비스
( 서비스번호 VARCHAR(100) PRIMARY KEY,
서비스일자 VARCHAR(100) NULL,
개시일자 DATE NOT NULL);
[SQL]
① SELECT * FROM 서비스 WHERE 서비스번호 = 1;
② INSERT INTO 서비스 VALUES ('999', '', '2015-11-11');
③ SELECT * FROM 서비스 WHERE 서비스명 = ''; -- SQL Server
④ SELECT * FROM 서비스 WHERE 서비스명 IS NULL; -- Oracle① 서비스번호 칼럼의 모든 레코드가 '001'과 같은 숫자형식으로 입력되어야 오류가 발생하지 않음.
②과 같이 데이터를 입력하면 서비스명 칼럼의 데이터에 대해서 오라클에서는 NULL로 입력됨.
②과 같이 데이트를 입력하고 SQL Server에서 데이터를 조회하려면서비스명 = ''조건으로 조회되어야 함.
②과 같이 데이트를 입력하고 Oracle에서 데이터를 조회하려면서비스명 IS NULL조건으로 조회되어야 함.
문제 13.
CREATE TABLE SVC_JOIN
( CUST_ID VARCHAR2(10) NOT NULL,
SVC_ID VARCHAR2(5) NOT NULL,
JOIN_YMD VARCHAR2(8) NOT NULL,
JOIN_HH VARCHAR2(4) NOT NULL,
SVC_START_DATE DATE NULL,
SVC_END_DATE DATE NULL);
①
SELECT SVC_ID, COUNT(*) AS CNT
FROM SVC_JOIN
WHERE SVC_START_DATE >= TO_DATE('20150101000000', 'YYYYMMDDHH24MISS')
AND SVC_END_DATE <= TO_DATE('20150131000000', 'YYYYMMDDHH24MISS')
AND CONCAT(JOIN_YMD,, JOIN_HH) = '2014120100'
GROUP BY SVC_ID;
②
SELECT SVC_ID, COUNT(*) AS CNT
FROM SVC_JOIN
WHERE SVC_START_DATE >= TO_DATE('20150101', 'YYYYMMDD')
AND SVC_END_DATE < TO_DATE('20150131', 'YYYYMMDD')
AND CONCAT(JOIN_YMD,, JOIN_HH) IN ('2014120100', '00')
GROUP BY SVC_ID;
③
SELECT SVC_ID, COUNT(*) AS CNT
FROM SVC_JOIN
WHERE '201501' = TO_CHAR(SVC_END_DATE, 'YYYYMM') -- TO_CHAR: 날짜 형싱 변화
AND JOIN_YMD = '20141201'
AND JOIN_HH = '00'
GROUP BY SVC_ID;
/* ①②③ : 모두 가입이 2014년 12월 01일 00시에 발생했고
서비스 종료일시가 2015년 01월 01일 00시 00분 00초와
2015년 01월 31일 23시 59분 59초 사이에 만료되는 데이터를 찾는 조건 */
④
SELECT SVC_ID, COUNT(*) AS CNT
FROM SVC_JOIN
WHERE TO_DATE('201501', 'YYYYMM') = SVC_END_DATE
AND JOIN_YMD || JOIN_HH = '2014120100'
GROUP BY SVC_ID;
/*④ 가입 조건은 동일하지만, 서비스 종료일시가 2015년 01월 01일 00시 00분 00초에 종료되는 SQL를 찾는 조건*/문제 16.
SELECT TO_CHAR(TO_DATE('2023.01.10 10', 'YYYYMMDD HH/24')
+ 1/24(60/10), 'YYYY.MM.DD HH24:MI:SS') FROM DUAL;
/* 실행 결과: 2023.01.10 10:10:00
Oracle에서 날짜의 연산은 숫자의 연산과 같다. '1/24/60 = 1분'을 의미
'1/24(60/10) = 10분'과 같으므로 2023.01.10 10시에 10을 더한 결과와 같음 */문제 25.
광고매체 ID별 최초로 게시한 광고명과 광고시작일자를 출력하기 위한 SQL

[SQL]
SELECT C.광고매체명, B.광고명, A.광고시작일자
FROM 광고게시 A, 광고 B, 광고매체 C
( ) D
WHERE A.광고시작일자 = D.광고시작일자
AND A.광고매체ID = D.광고매체ID
AND A.광고ID = B.광고ID
AND A.광고매체ID = C.광고매체ID
ORDER BY C.광고매체명;해설:
광고게시 테이블에서 광고매체ID별로 광고시작일자가 가장 빠른 데이터를 추출하는 SQL를 작성해야 함SELECT 광고매체ID, MIN(광고시작일자) AS 광고시작일자 FROM 광고게시 GROUP BY 광고매체ID
문제 27.
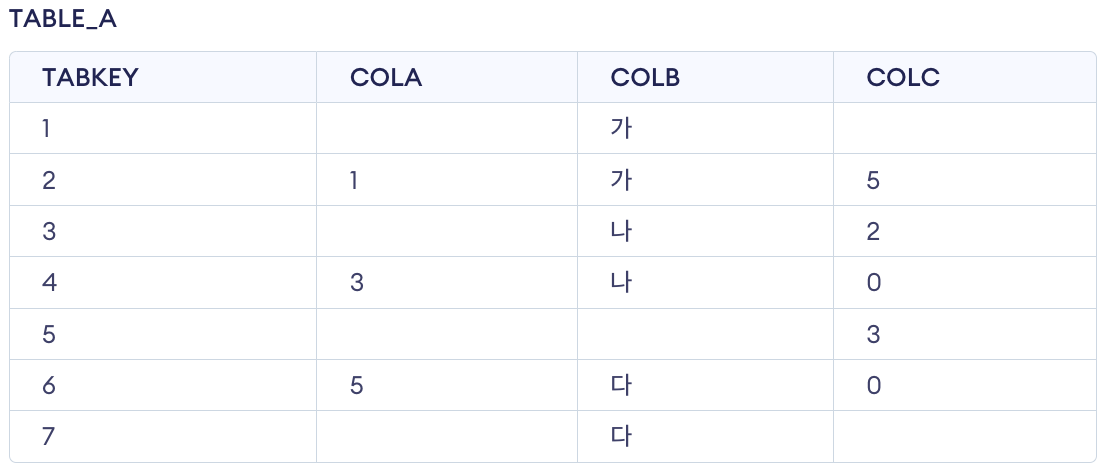
CREATE TABLE TABLE_A
( TABKEY NUMBER NOT NULL,
COLA NUMBER NULL,
COLB VARCHAR(5) NULL,
COLC NUMBER NULL);
INSERT INTO TABLE_A (TABKEY, COLA, COLB, COLC)
VALUES (1, NULL, '가', NULL);
INSERT INTO TABLE_A (TABKEY, COLA, COLB, COLC)
VALUES (2, 1, '가', 5);
INSERT INTO TABLE_A (TABKEY, COLA, COLB, COLC)
VALUES (3, NULL, '나', 2);
INSERT INTO TABLE_A (TABKEY, COLA, COLB, COLC)
VALUES (4, 3, '나', 0);
INSERT INTO TABLE_A (TABKEY, COLA, COLB, COLC)
VALUES (5, NULL, NULL, 3);
INSERT INTO TABLE_A (TABKEY, COLA, COLB, COLC)
VALUES (6, 5, '다', 0);
INSERT INTO TABLE_A (TABKEY, COLA, COLB, COLC)
VALUES (7, NULL, '다', NULL);
--문제
[SQL]
SELECT COLB,
MAX(COLA) AS COLA1,
MIN(COLA) AS COLA2,
SUM(COLA + COLC) AS SUMAC
FROM TABLE_A
GROUP BY COLB;해설:
- GROUP BY절은 NULL 데이터도 집계에 포함하므로 COLB칼럼의 값에 NULL이 있는 행도 결과로 출력됨
- MIN, MAX함수는 칼럼의 값이 NULL이 아닌 행 중에서의 최소, 최대값을 추출
- NULL과의 사칙연산 결과는 NULL

참고,
SQL 자격검정 실전문제, Kdata 한국데이터산업진흥원
SQLOnline Compiler : https://www.programiz.com/sql/online-compiler

ʚȉɞ