# 현상 이해하기 : 탐색적 데이터 분석🔍
: 주어진 데이터를 다양한 각도에서 관찰하고 이해하는 과정
<탐색적 데이터 분석이 필요한 이유>
- 우선 데이터의 분포 및 값을 검토함으로써 데이터가 표현하는 현상을 더 잘 이해하고, 데이터에 대한 잠재적인 문제를 발견할 수 있다.
- 이를 통해 본격적인 분석에 들어가기에 앞서 데이터를 다시 수집하거나 추가로 수집하는 등의 결정을 내릴 수 있다.
- 또한 데이터를 다양한 각도에서 살펴보는 과정을 통해 문제 정의 단계에서 미처 발생하지 못했을 다양한 패턴을 발견하고, 이를 바탕으로 기존의 가설을 수정하거나 새로운 가설을 세울 수 있다.
- 데이터에 대한 이런 지식은 이후에 통계적 추론을 시도하거나 예측 모델을 만들 때 유용하게 사용된다.
1. 탐색적 분석 단계
: 문제 정의 단계에서 세웠던 연구 질문과 가설을 바탕으로 분석 계획 세우기
: 이를 바탕으로 본격적인 분석을 시작 (데이터 살펴보기, 데이터의 개별 속성값 관찰)
<데이터 분석의 주된 수단>
- 원본 데이터 관찰 - 데이터 각 항목과 속성의 값을 꼼꼼히 관찰할 수 있는 반면 큰 그림을 놓치기 쉽다.
- 요약 통계값 - 숲은 보지만 나무는 보지 못하는 우를 범할 수 있다.
- 시각화 - 스케터플롯은 나무와 숲을 모두 볼 수 있는 유용한 도구이다.
※ 순환적 사용 : 원본 데이터를 보다가 의심이 가는 부분이 있으면 적절한 시각화나 통계값을 통해 검정하고, 반대로 시각화나 통계값을 통해 발견한 패턴을 해당 원본 데이터값에서 추가로 검정해야 한다는 뜻
[1] 데이터 개관
: 데이터를 상세하게 분석하기에 앞서 불러들인 데이터에 문제가 없는지 전체적으로 살펴본다.
: 우선 확인할 사항은 데이터에 속한 항목 개수와 속성 목록이 예상과 일치하는지의 여부
: 데이터의 각 속성이 가지는 데이터형을 확인한다.
: 수치, 카테고리, 텍스트, 시간 등이 해당
: 데이터형에 따라 어떤 분석 및 시각화 방법을 적용할 수 있는지를 결정할 수 있다.
[2] 속성 분석하기
: 개별 속성을 살펴본다.
: 데이터를 구성하는 각 속성값이 우리가 예측한 범위와 분포를 갖는지, 만약 그렇지 않는다면 이유는 무엇인지를 알아볼 수 있다.
: 이상값을 찾아낸다.
[2] 속성 간 관계 분석하기
: 서로 의미 있는 상관 관계를 갖는 속성의 조합을 찾아내는 것
: 속성이 많은 데이터의 경우 속성의 조합에 따라 무수히 다양한 종류의 분석을 수행할 수 있다.
↓ 데이터형의 조합에 따라 주로 사용되는 요약 통계 및 시각화 방법
| 데이터형 | 요약 통계 | 시각화 |
|---|---|---|
| 카테고리-카테고리 | 교차 테이블 | 모자이크플롯 |
| 수치-수치 | 상관 계수 | 스케터플롯 |
| 카테고리-수치 | 카테고리별 통계값 | 박스플롯 |
: 두 카테고리형 속성 간의 관계를 분석 하는 데는 각 속성값의 쌍에 해당하는 값 개수를 표시하는 교차 테이블이나 같은 정보를 시각적으로 나타내는 모자이크 플롯을 사용한다.
: 엑셀의 피벗 테이블이나 R의 table() 명령을 사용
: 상관계수는 두 속성값의 연관성을 나타내는 수치로 -1은 음의 상관관계, 0은 상관관계 없음, 1은 양의 상관관계를 나타낸다.
: 같은 상관계수를 갖는 두 속성의 관계도 다양한 양상을 띌 수 있는데, 이를 시각적으로 나타내는 것이 스케터플롯이다.
: 카테고리형과 수치형 속성의 관계를 분석하기 위해서는 각 카테고리별 통계값을 관찰할 수 있다.
# 실습 - 엑셀로 해보는 탐색적 데이터 분석
: 다양한 제조사 및 모델별로 1999년형과 2008년형 자동차의 연비를 기록한 MPG 데이터 셋 사용
manufacturer : 제조사
model : 차명
trans : 변속기 방식
drv : 구동 방식 (f: 전륜, r: 후륜, 4: 4륜)
displ : 배기량(리터)
year : 출시 연도
cyl : 실린더 개수
cty : 도시 주행 연비
hwy : 고속도로 주행 연비
Class : 차량 유형
fl : 연료 종류 (r: 일반 경유, p: 고급 경유, d: 디젤, e: 에탄올, c: 천연가스)
↓ MPG 데이터 셋에 표 서식 적용
↓ 데이터에서 표본추출을 하여 한눈에 들어오는 크기로 줄인다.
-
표의 가장 오른쪽(L1셀) 위에 'sample'이라고 입력한다.
-
표 서식이 적용된 상태라면 자동으로 표가 확장될 것이다.
-
속성값에 임의의 난수를 발생시키는 rand() 함수를 입력한다.
-
역시 표 서식의 효과로 한 셀에 값을 입력하면 모든 값에 동일한 값이 입력된다.
-
sample 속성이 선택된 상태에서 숫자 오름차순 정렬 메뉴를 선택한다.
-
그럼 임의의 난수 값을 기준으로 데이터가 정렬된다.
-
정렬된 표의 위에서부터 31개의 행을 선택한다.
-
sample이라는 워크시트를 만들고 선택한 데이터를 붙여넣으면 원본 데이터에서 30개를 무작위로 추출한 표본이 완성된다.
1. 개별 속성 분석하기
: 피벗 테이블을 삽입하고 '행' 필드에 실린더 수(cyl), '값' 필드에 도시 연비(cty), 집계 방법은 '개수'를 선택한다. 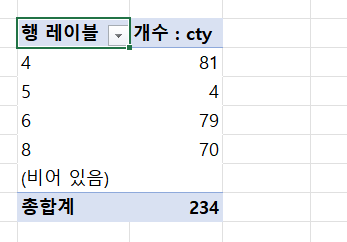
※ 피벗 테이블을 복사 붙여넣기 한 후 '행' 속성을 바꿔가면서 새로운 피벗 테이블을 만들 수 있다.
+) 피벗 테이블을 사용하여 다양한 카테고리형 속성값의 분포를 확인할 수 있다.
: 엑셀은 수치형 속성의 분포를 확인하는 히스토그램 기능을 제공한다.
