# R로 데이터 과학 맛보기
: 데이터 처리에 유용한 R의 기본 기능을 실습으로 알아볼 것이다.
1. R 작업을 위한 환경 구축
R : 실제 통계 및 시각화를 처리하는 프로그램
Rstudio : R을 편리하게 사용할 수 있는 환경을 제공
↓ 몇 가지 기본 변수 선언해보기 : Ctrl + Enter 실행
↓ 프로젝트 생성 및 디렉토리 설정, 데이터 불러오기
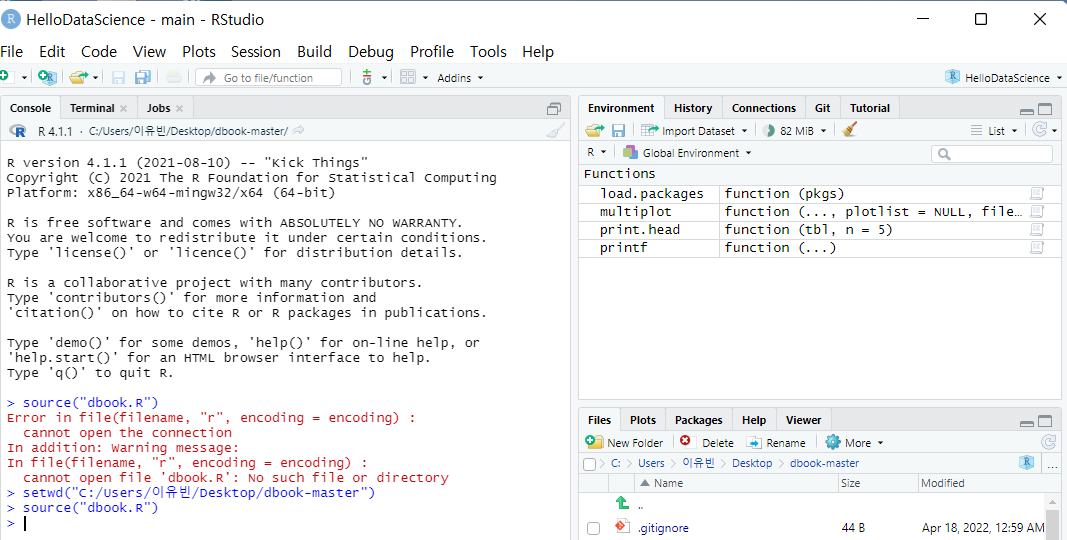 ※ 디렉토리를 설정하지 않고 데이터를 불러오려고 하면 위 사진과 같이 오류가 발생함.
※ 디렉토리를 설정하지 않고 데이터를 불러오려고 하면 위 사진과 같이 오류가 발생함.
: 데이터가 포함되어 있는 파일의 경로로 설정해야 한다.
↓ 패키지 설치
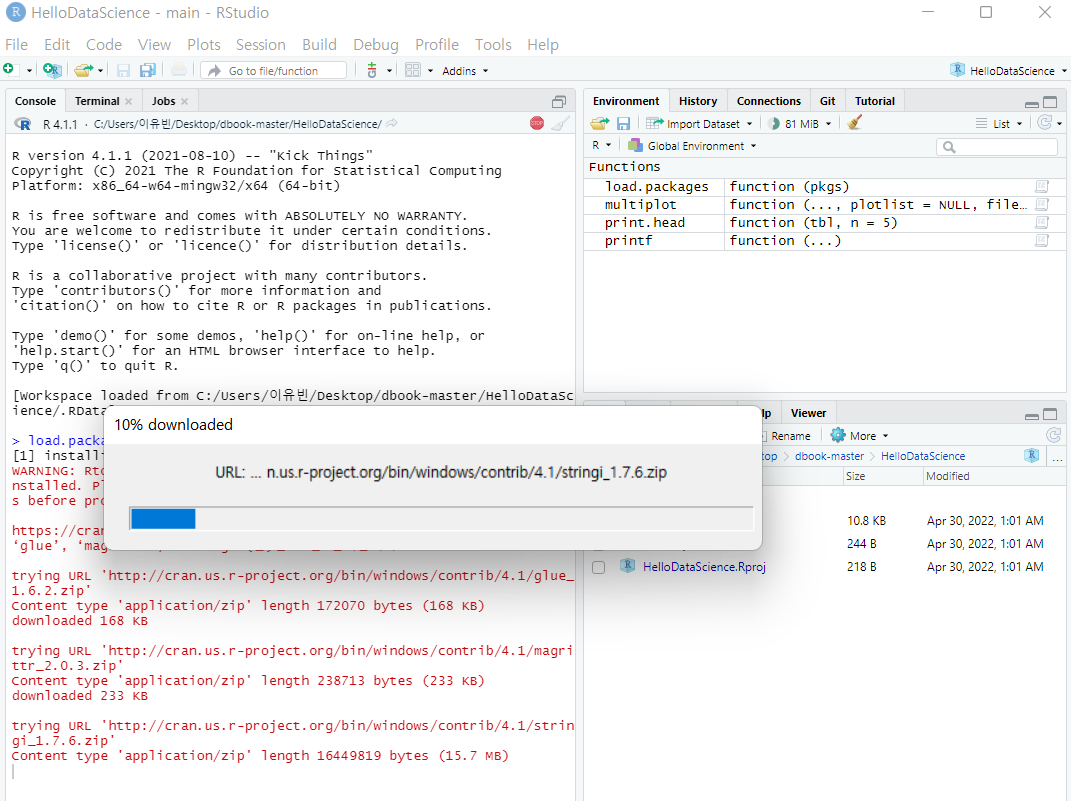 ※ R과 Rstudio를 옛날에 설치해두고 사용해서 그런지, 패키지를 설치하고 로드하는데 많은 시간이 걸렸다.
※ R과 Rstudio를 옛날에 설치해두고 사용해서 그런지, 패키지를 설치하고 로드하는데 많은 시간이 걸렸다.
+) 관리자 권한으로 Rstudio를 실행해야 패키지 설치가 가능했다.
2. R의 기본 기능
1. 데이터 읽고 쓰기
-> summary() 사용 : 속성별로 값 분포를 볼 수 있다.
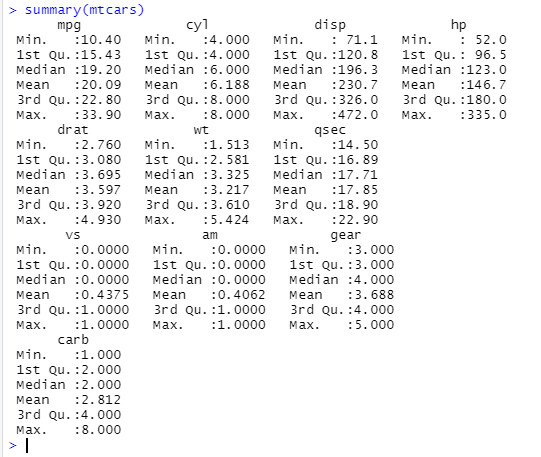
-> mtcars 데이터를 파일로 저장하고 읽어보자.
 ※ header=T 옵션은 데이터 파일의 첫 줄을 속성 목록으로 사용한다는 의미
※ header=T 옵션은 데이터 파일의 첫 줄을 속성 목록으로 사용한다는 의미
+) 함수에 대한 설명을 보고 싶으면 "?함수명"을 입력하면 된다.
write.table(cars, "clipboard")
# 원본 데이터 대신 cars를 사용
# 저장한 데이터를 엑셀에 불러들일 경우2. 데이터 살펴보기
-> head() 사용 : 데이터의 첫 몇 항목만 보기 위해
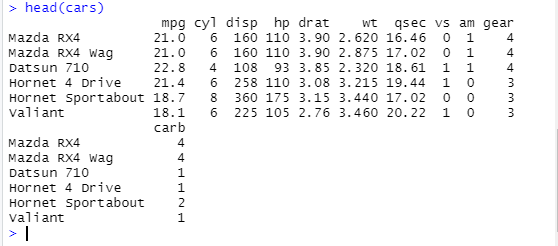
-> 10줄을 보고 싶은 경우
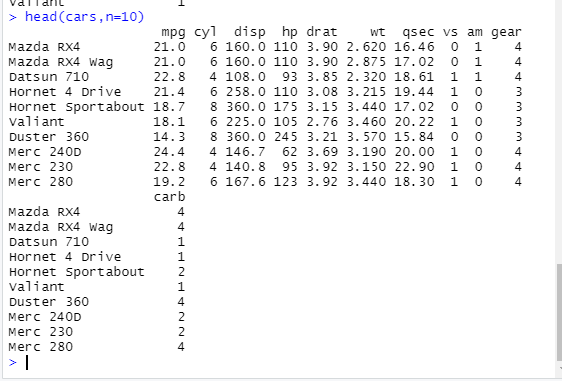
-> tail() 사용 : 데이터의 마지막 몇 항목만 보기 위해
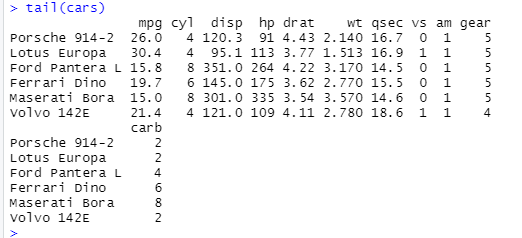
-> rownames(), colnames() : 각 행과 열에 대한 이름 확인

-> mpg 속성을 보는 명령어

3. 데이터 준비하기
1. 기본 가공법
-> stringr 라이브러리의 word() : 문자열 형태의 속성에서 단어를 추출하는 기능 제공
-> model 속성의 첫 단어를 추출하여 maker라는 속성을 만든다.
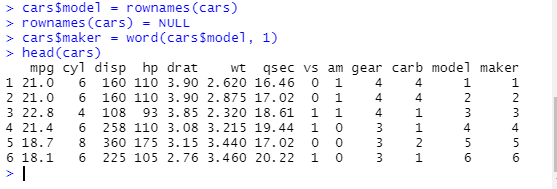
2. 고급 가공법(dplyr)
-> dplyr 라이브러리 사용 : 개별 연산에 해당하는 다양한 함수 제공
-> %>% : 데이터 가공 과정에서 여러 기본 연산을 조합하는데 사용

 ※ 위에서 만든 cars 데이터에서 실린더 개수(cyl)가 4개인 차의 제조사, 모델, 연비를 선택
※ 위에서 만든 cars 데이터에서 실린더 개수(cyl)가 4개인 차의 제조사, 모델, 연비를 선택
-> 데이터 집계
-> 집계를 위한 기준 속성 선택 후 집계된 그룹별로 계산할 통계 값을 적어줌
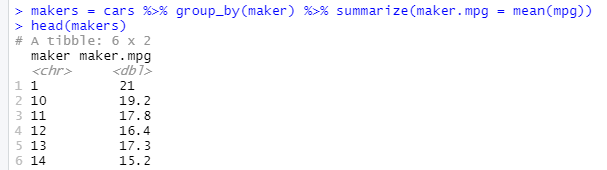
 ※ cars 데이터를 제조사별로 집계하고, mean() 함수를 사용하여 각 그룹별로 연비의 평균을 구함
※ cars 데이터를 제조사별로 집계하고, mean() 함수를 사용하여 각 그룹별로 연비의 평균을 구함
+) group_by(maker) : 제조사 기준으로 데이터를 집계한다는 의미
-> 두 테이블을 특정한 속성값을 기준으로 병합
-> 원본 데이터인 cars와 제조사별 집계 데이터인 makers를 제조사명을 기준으로 병합
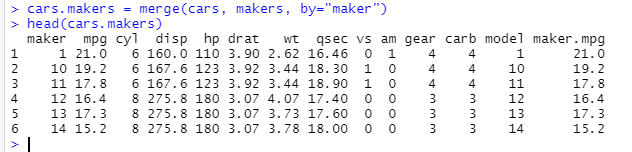
 ※ by="maker" : 제조사명을 기준으로 두 테이블을 병합하라는 뜻
※ by="maker" : 제조사명을 기준으로 두 테이블을 병합하라는 뜻
3. 데이터 분석하기
1. 요약 통계
-> cyl 속성값의 분포, cyl 및 gear 속성 간의 관계를 살펴보는 명령
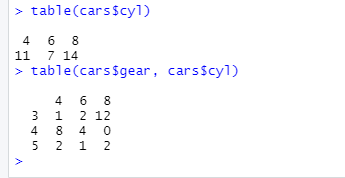
2. 기본 시각화
-> 수치형 속성의 분포를 보기 위해서는 보통 히스토그램 사용
-> mpg 속성값 시각화
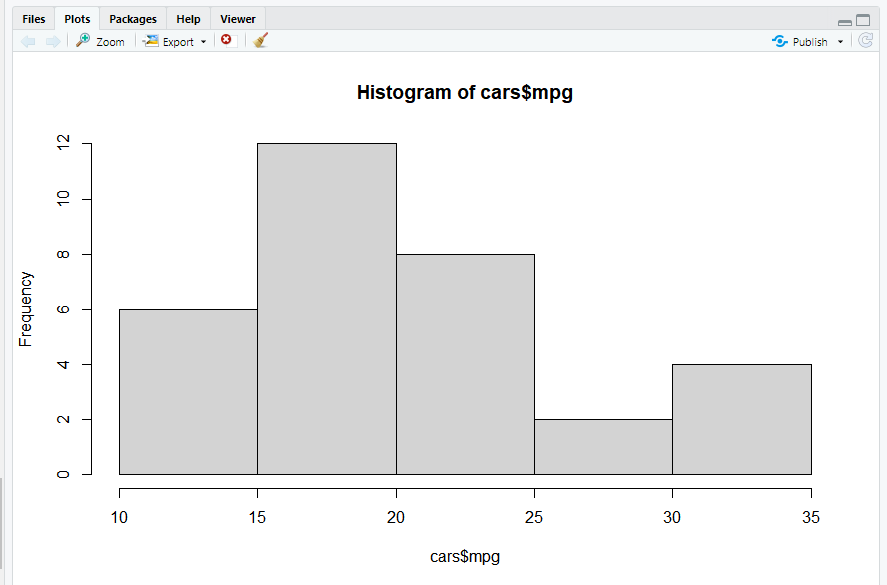 ※ 15~20, 20~25 사이에 가장 많은 속성값 위치
※ 15~20, 20~25 사이에 가장 많은 속성값 위치
-> 두 속성간의 관계를 한눈에 보여주는 분산 차트
-> 무게(wt)와 연비(mpg) 속성 간의 관계를 보여주는 스케터플롯
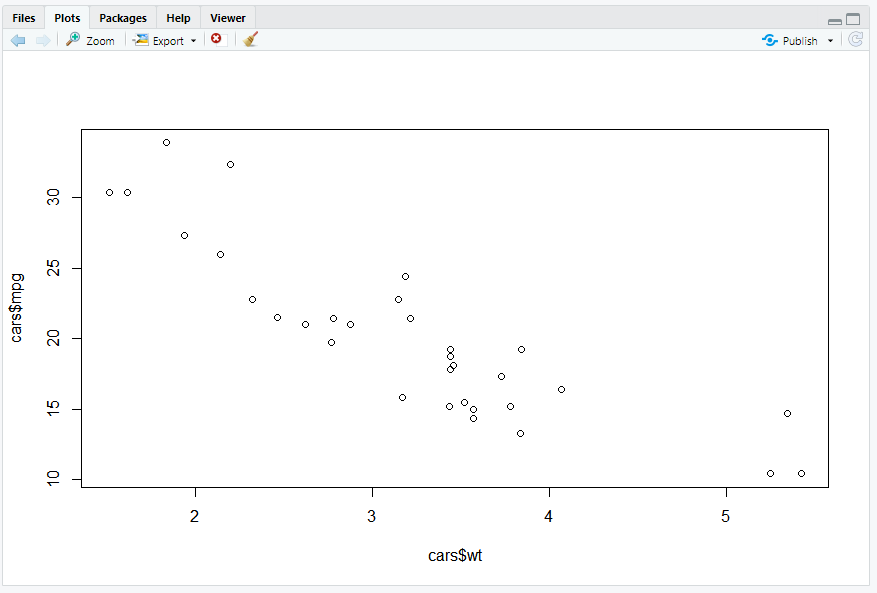 ※ 무게 증가에 따라 연비가 떨어지는 추세가 확연히 나타남
※ 무게 증가에 따라 연비가 떨어지는 추세가 확연히 나타남
3. 고급 시각화(ggplot2)
-> ggplot2 라이브러리에서 제공하는 qplot() 명령어 사용 : 세 가지 이상의 속성 관계를 한눈에 볼 수 있음
-> wt와 mpg 속성 간의 관계를 XY축에 나타내고, cyl값을 모양으로 표시
-> factor() : 숫자를 카테고리 형태의 데이터로 인식하라는 명령
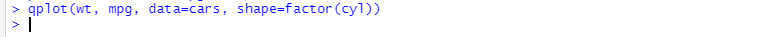
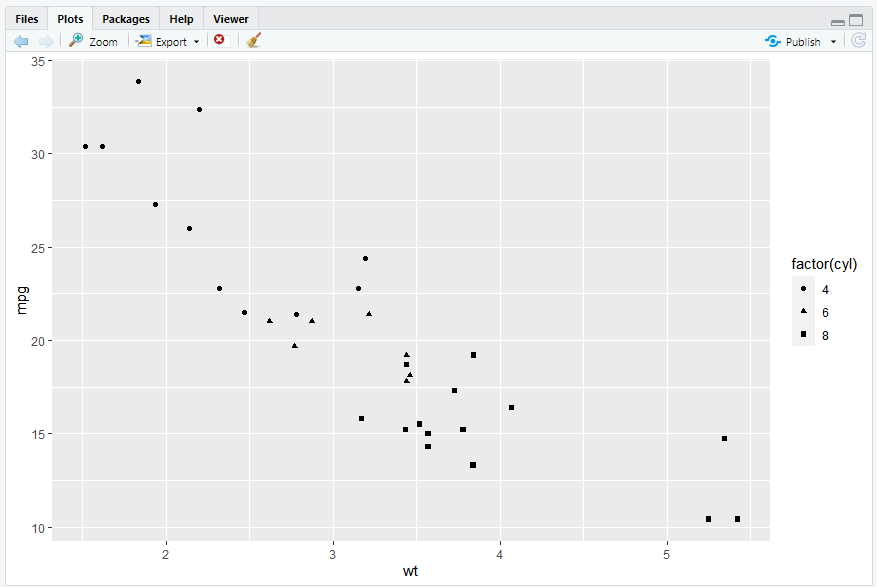 ※ 연비(mpg)가 실린더 개수(cyl) 및 무게(wt)와 상관 관계가 높음을 알 수 있다.
※ 연비(mpg)가 실린더 개수(cyl) 및 무게(wt)와 상관 관계가 높음을 알 수 있다.
+) 이런 종류의 시각화는 엑셀에서 지원하지 않음.
