# CNN Basics Convolution
Convolutional Neural Network
: image classification에서 가장 널리 사용되는 NN
: 3가지 종류의 layer로 구성 - convolution layer, pooling layer, fully-connected layer
: Convolution, Pooling layer - feature extraction 역할
: Fully-connected layer - classification 역할
2D Convolution Layer
: image 입력을 받을 때에는 2D Convolution Layer를 많이 사용
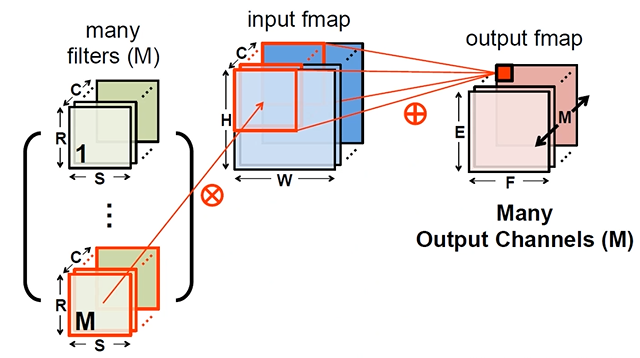
 : 32x32x3 image, 5x5x3 filter
: 32x32x3 image, 5x5x3 filter
: 3 -> channel
: convolution layer의 특징 1 -> convolution layer의 입력으로 들어오는 것의 channel이 항상 convolution filter channel과 같아야 한다.
: convolution filter 수 : 5x5x3 = 75
: 왼쪽 위에 75개의 숫자를 갖는 filter가 놓이게 되고, feature map의 input image에도 존재하는 75개 숫자들끼리 각각 곱한다음에 더해서 하나의 숫자를 만듬 -> dot product (내적 연산)
: 출력들을 모으면 한 장의 image같은 형태가 나옴. 28x28
: feature map, Activation map이라고 함
: convolution layer의 특징 2 -> output feature map의 채널 수는 convolution layer에 사용한 convolution filter의 개수와 같다.
2D Convolution Layer - Computation
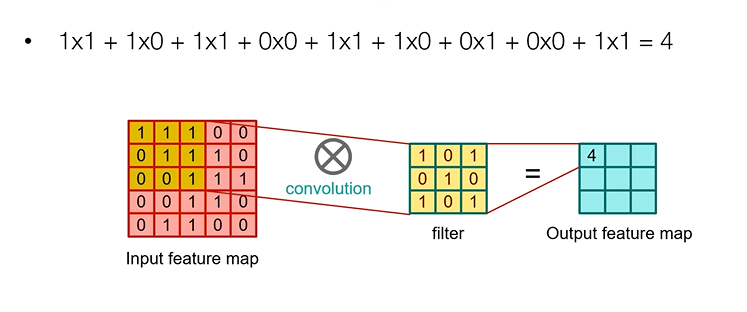 : input feature map의 channel을 1로 설정
: input feature map의 channel을 1로 설정
: filter의 채널도 1이 된다.
: convolution filter 1개만 쓰면 output feature map의 channel도 1이 된다.
: 각 자리의 숫자끼리 곱한 후 다 더해줌
: 오른쪽으로 이동해주면서 연산해줌
2D Convolution Layer - Multi Channel, Many Filters
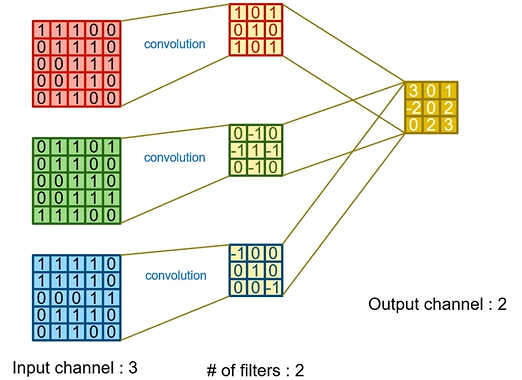
2D Convolution Layer
 : 실제로 input feature map은 3D - 3차원
: 실제로 input feature map은 3D - 3차원
: filter하나는 3차원, 여러 개의 filter를 사용하면 4D - 4차원
: output feature map은 3D - 3차원
2D Convolution Layer - 4D Tensors
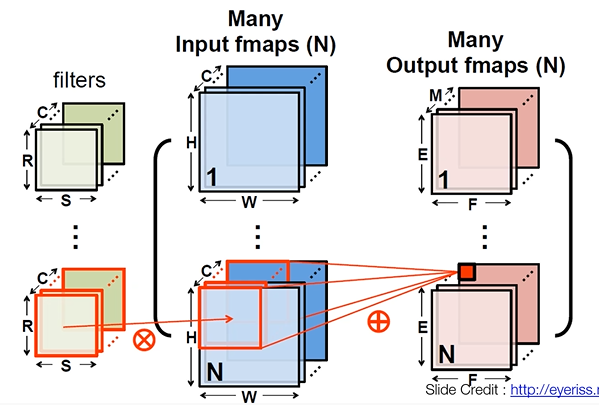 : 미니 배치 학습법 : image data를 한 장만 사용하지 않고 학습할 때 여러 개의 이미지를 동시에 사용해서 학습을 하는 것
: 미니 배치 학습법 : image data를 한 장만 사용하지 않고 학습할 때 여러 개의 이미지를 동시에 사용해서 학습을 하는 것
: 미니 배치 개수가 N개라고 나타냄.
: 입력 이미지도 3차원이 아니라 실제로는 N개의 3차원 이미지가 있으니까 4차원이다.
: output feature map도 4차원이 된다.
: 2D convolution이라고 한 것은 연산을 할 때 feature를 가로와 세로 방향으로만 즉, 2D 방향으로만 슬라이딩 하기 때문이다.
: 실제로 사용되는 데이터들은 다 4D Tensor 형태로 들어가고 나오게 된다.
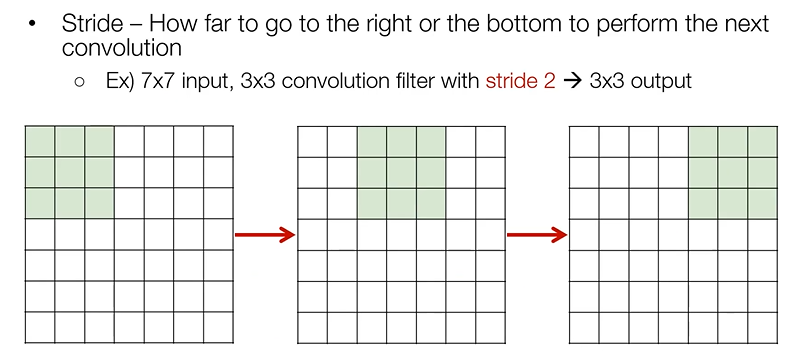
Options of Convolution - Stride
: Stride - 한 번 convolution 연산을 하고 나서 옆으로 이동해서 convolution 할 때 몇 칸 옆으로 이동할건지에 대한 부분
Options of Convolution - Zero Padding
: 32x32 image, 5x5 convolution, 28x28 output
: padding을 안하고 convolution 연산을 하면 image가 줄어들게 되는데, 이러면 layer를 깊게 쌓는데 지장이 있음
: 이를 막기 위해서 주변을 0으로 padding

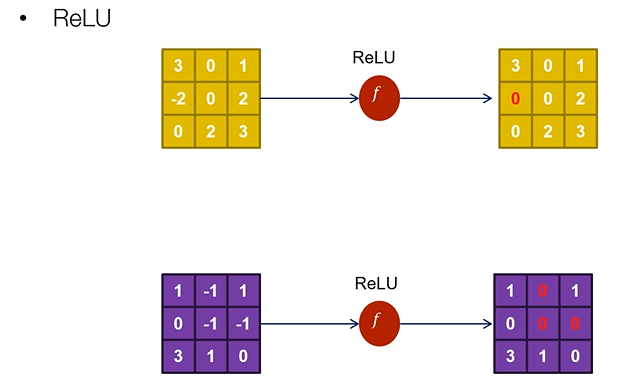
Activation function - ReLU
: convolution 연산을 하고 나면 Activation function을 통과시키게 된다.
: 음수는 0으로 양수는 그대로 통과
tf.keras.layers.Conv2D
 : tf.keras.layers.Conv2D API 사용
: tf.keras.layers.Conv2D API 사용
 : filters - convolution filter의 수 -> output feature map의 channel을 몇으로 할 건지에 대한 부분
: filters - convolution filter의 수 -> output feature map의 channel을 몇으로 할 건지에 대한 부분
: kernel_size - convolution filter를 3x3으로 할건지 5x5로 할건지에 대한 부분
: strides - stride를 무엇으로 할 것인지에 대한 부분
: padding - "valid" / "same"
: data_format - channels_last (빨간 박스 순서로 구성) / channels_first
Padding - SAME vs VALID
: Valid - padding을 안하는 것
: Same - Stride가 1인 경우를 기준으로 했을 때 입력과 출력이 같아지도록 함.
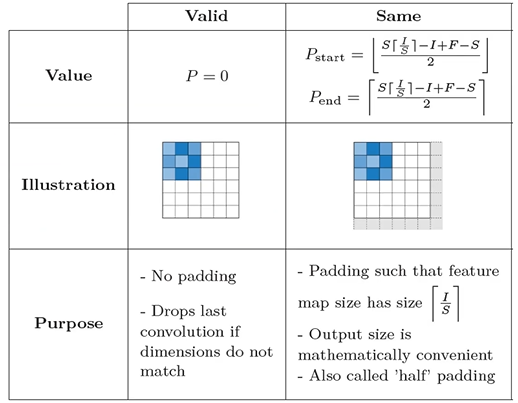
: start - 왼쪽, 위쪽 padding 하는 개수
: end - 오른쪽, 아래쪽 padding 하는 개수
: S - stride
: I - input feature map의 가로나 세로 사이즈
: F - filter의 가로나 세로 사이즈
: ㄴ - 버림
: r - 올림
 : activation - activation function
: activation - activation function
: use_bias - bias를 쓸건지에 대한 부분
: kernel_initializer, bias_initializer - convolution filter와 bias를 initializer할 때 어떤 initializer를 쓸건지에 대한 부분
: kernel_regularizer, bias_regularizer - L2 Regularization 등을 기술해주는 부분
Importing Libraries & Enable Eager Mode

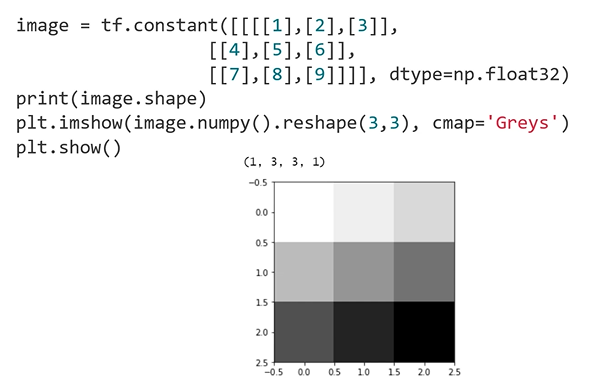
Toy Image
: batch, width, height, channel
Simple Convolution Layer
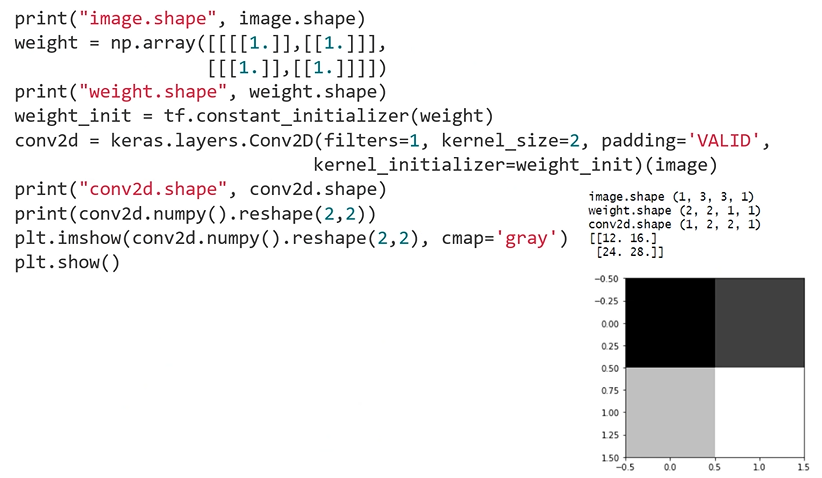
: Stride - 1, Padding - VALID
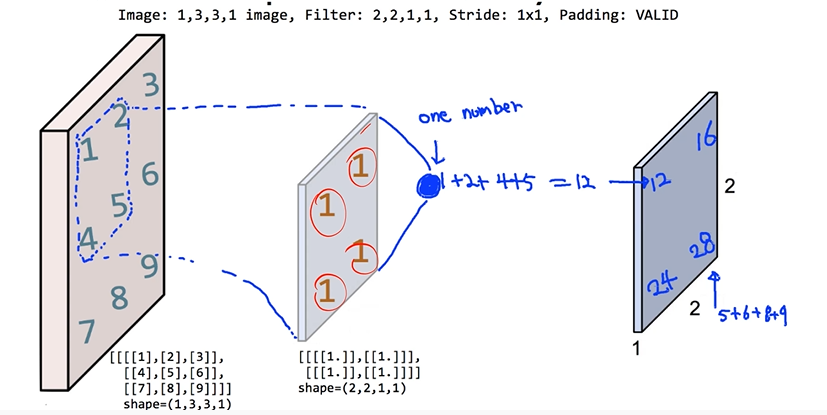
: weight의 initial값을 1로 채움
: weight.shape - (convolution filter의 height, width, channel, convolution filter의 개수)
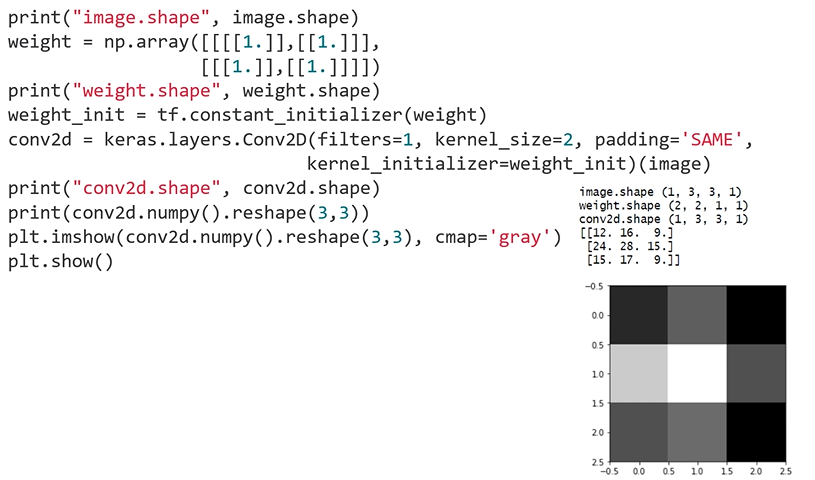
: Padding - SAME으로 바꾸고 연산
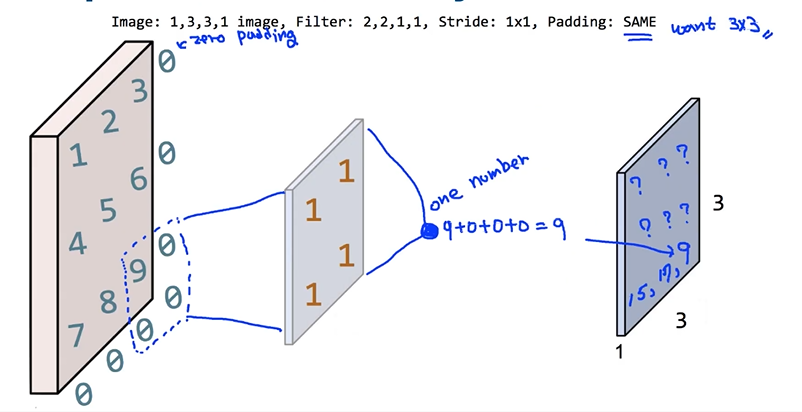
: 3x3의 출력 형태가 나옴
3 Filters
: 2 , 2 , 1 , 3 - ( height , width , channel , filter개수 )
: 하나는 1로, 두 번째는 10으로, 마지막은 -1로 채워진 filter를 만듬
: conv2d.shape(1,3,3,3) - (batch, height, width, channel)
: output도 channel의 개수가 3이 된다는 것을 볼 수 있음

# CNN Basics Pooling
Pooling Layer
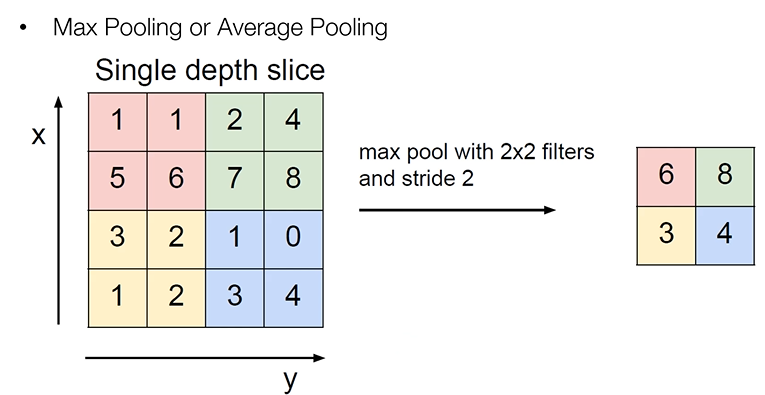
: Max Pooling / Average Pooling
: 아래 그림은 Max Pooling을 나타냄
: 16개 4x4는 convolution layer에서 나온 출력
: 4개의 숫자 중 제일 큰 숫자를 뽑음
: 4x4 -> 2x2 (중요한 정보를 뽑아서 사이즈를 줄임) = Sub Sampling
: Average Pooling - 평균을 구함
tf.keras.layers.MaxPool2D
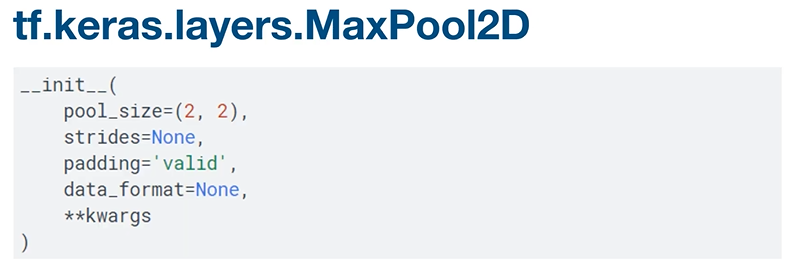 : tf.keras.layers.MaxPool2D API 사용
: tf.keras.layers.MaxPool2D API 사용
 : pool_size - pooling할 때 filter 사이즈
: pool_size - pooling할 때 filter 사이즈
: 나머지 모두 convolution과 동일
Max Pooling
: 2x2 4개의 숫자를 갖는 image
: VALID - padding 안함
 : SAME
: SAME

Loading MNIST Data
Convolution Layer - Output Feature Maps
: image를 convolution 연산에 집어 넣으려면 4차원으로 바꿔주어야 함
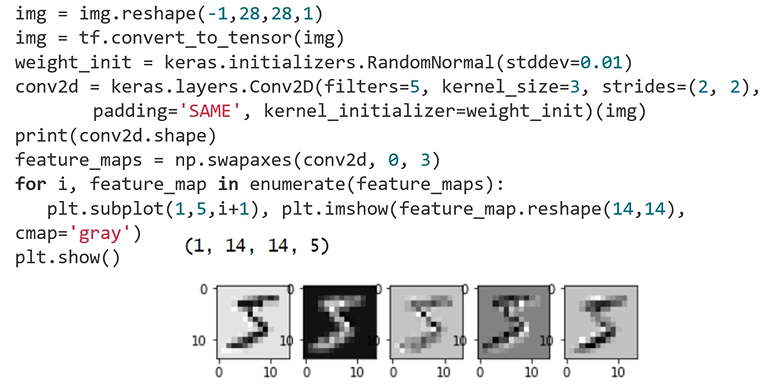 : batch -1(알아서 채워줌) - image 1개 사용
: batch -1(알아서 채워줌) - image 1개 사용
: padding = 'SAME', sride = 2
: 28x28 -> 14x14
: 1 , 14 , 14 , 5 - ( batch , height , width , channel )
Pooling Layer - Output Feature Maps
 : padding = 'SAME', sride = 2
: padding = 'SAME', sride = 2
: 14x14 -> 7x7
Fully Connected(Dense) Layer
: CNN을 구성하는 3가지 종류의 layer 중 하나
: CNN에서 fully connected layer로 아래 그림과 같이 연결된다.
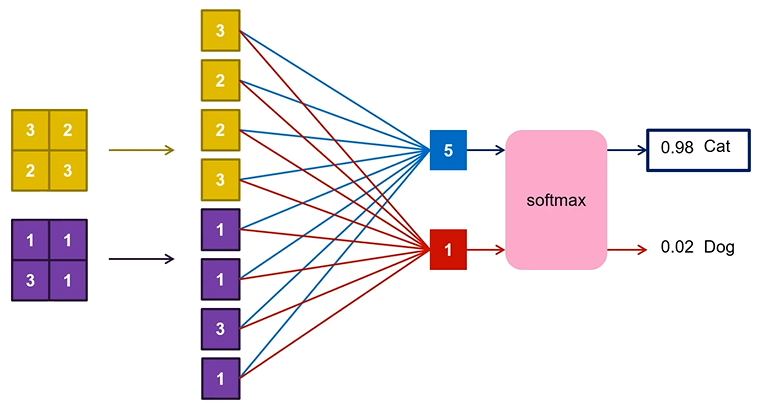
Convolutional Neural Network
: Convolution Layer와 Pooling Layer를 통해서 feature extraction하는 역할을 함
: 마지막에 Fully Connected Layer에서 실제 classification하는 역할을 함

# CNN with MNIST Dataset using tf.keras.Sequential APIs
 : data pipelining - dataset을 로드하고, 그 dataset에서 앞에서 설정했던 batch size만큼 data를 가져와서 뒤에서 만들 network에 공급해주는 것
: data pipelining - dataset을 로드하고, 그 dataset에서 앞에서 설정했던 batch size만큼 data를 가져와서 뒤에서 만들 network에 공급해주는 것
: neural network model을 만들었다면 나온 output과 정답을 비교해서 loss값을 만듬. -> loss function 정의
: weight에 대한 gradient를 미분하여 학습
: 모델의 성능을 측정할 수 있는 metrix를 classification에서는 주로 accuracy 사용
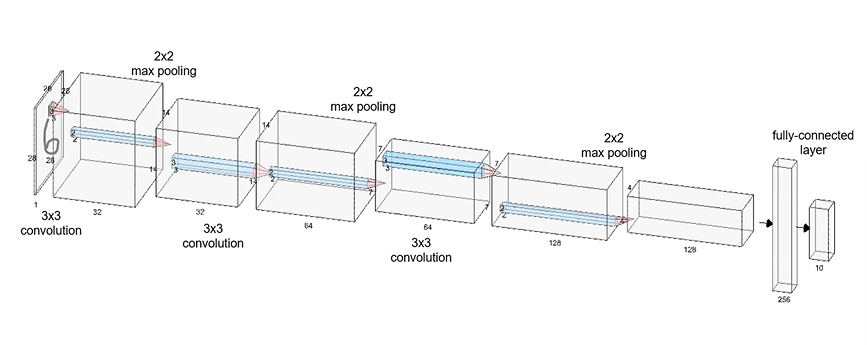
CNN with MNIST Data
: 28x28 MNIST Image가 들어옴
: 3x3 convolution, stride = 1, padding = 'SAME'
: 2x2 max pooling, stride = 2, padding = 'SAME'
: convolution filter 2배 씩 늘려서 사용
: pooling을 해서 가로 세로 사이즈는 절반으로 줄어듬
0. Import Libraries

1. Set Hyper Parameters
2. Make a Data Pipelining
 : train data, test data는 255로 나누어 0~1 사이 값으로 scaling 해줌
: train data, test data는 255로 나누어 0~1 사이 값으로 scaling 해줌
: expand_dims - channel이 빠져 있는 3차원을 4차원으로 만들어줌
: to_categorical - one hot encoding
: train_images, train_labels를 batch_size만큼 잘라서 공급해줌
3. Build a Neural Network Model - Sequential API
 : input_shape - 디버깅할때 편리
: input_shape - 디버깅할때 편리

4. Define a Loss Function
5. Caculate a Gradient

6. Select an Optimizer
7. Define a Metric for Model's Performance
8. Make a Checkpoint for Saving

9. Train and Validate a Neural Network Model


- Accuracy : 99.36%
# CNN with MNIST Dataset using tf.keras.Functional APIs

CNN with MNIST Data
: 28x28 MNIST Image가 들어옴
: 3x3 convolution, stride = 1, padding = 'SAME'
: 2x2 max pooling, stride = 2, padding = 'SAME'
: convolution filter 2배 씩 늘려서 사용
: pooling을 해서 가로 세로 사이즈는 절반으로 줄어듬
0. Import Libraries
1. Set Hyper Parameters
2. Make a Data Pipelining
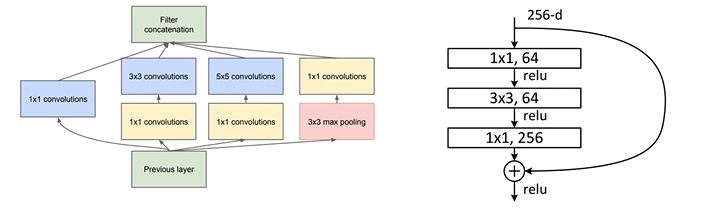
Limitation of Sequential API
: Multi-input models
: Multi-output models
: Models with shared layers (the same layer called several times) - 하나의 layer를 share, 같은 layer를 여러 번 반복해서 call
: Models with non-sequential data flow(e.g.Residual connections)
: 위와 같은 case 구현 불가능
3. Build a Neural Network Model - Functional API
 : convolution layer에 입력(inputs)을 명시해주는게 Functional API의 특징
: convolution layer에 입력(inputs)을 명시해주는게 Functional API의 특징

Implementation of Residual Block
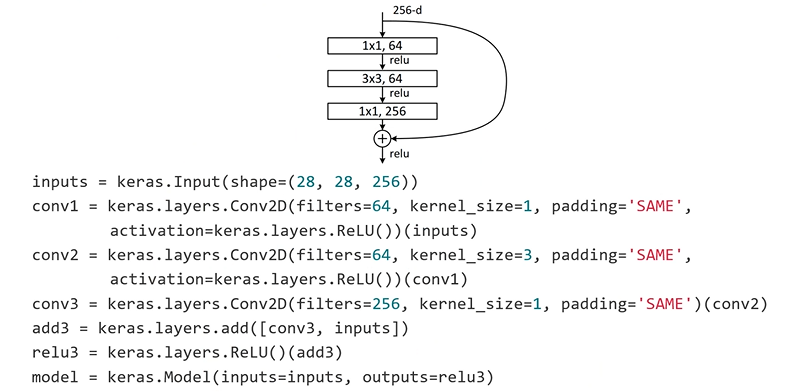
4. Define a Loss Function
5. Caculate a Gradient
6. Select an Optimizer
7. Define a Metric for Model's Performance
8. Make a Checkpoint for Saving
9. Train and Validate a Neural Network Model
- Accuracy : 99.35%
# CNN with MNIST Dataset using tf.keras.Model Subclassing

CNN with MNIST Data
: 28x28 MNIST Image가 들어옴
: 3x3 convolution, stride = 1, padding = 'SAME'
: 2x2 max pooling, stride = 2, padding = 'SAME'
: convolution filter 2배 씩 늘려서 사용
: pooling을 해서 가로 세로 사이즈는 절반으로 줄어듬
0. Import Libraries
1. Set Hyper Parameters
2. Make a Data Pipelining
Model Subclassing
: fully-customizable model을 만들 수 있다.
: class 형태로 만든 다음에 layer 부분을 __init__ method 부분에 선언해준다.
: call method에서 그 부분의 입력을 연결해줌
3. Build a Neural Network Model - Model Subclassing
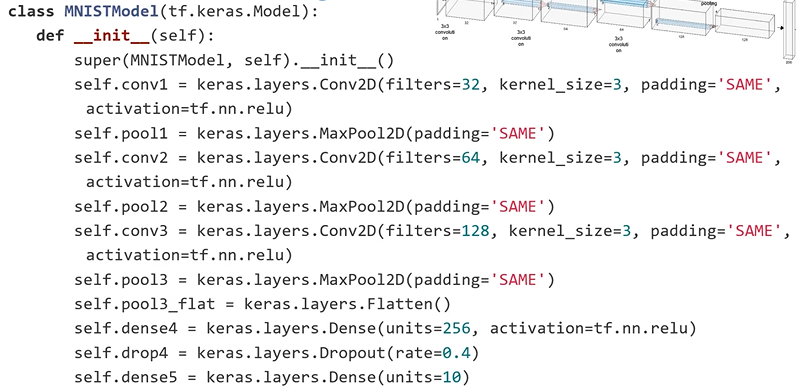
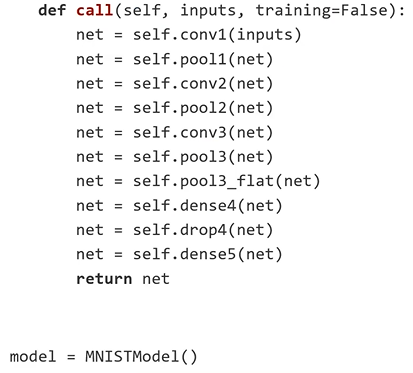
4. Define a Loss Function
5. Caculate a Gradient
6. Select an Optimizer
7. Define a Metric for Model's Performance
8. Make a Checkpoint for Saving
9. Train and Validate a Neural Network Model
- Accuracy : 99.35%
# CNN with MNIST Dataset using Model Ensemble

CNN Model Ensemble with MNIST Data
: 3개의 CNN을 만듬
: 똑같은 dataset을 3개의 모델에 넣어주면서 학습은 각각 실행할 것
: 학습하는 중간중간 혹은 학습이 끝날 때 inference 할 때 같은 image를 넣어줌
: 각각의 모델이 output을 주면 다 합쳐서 0~9중 무엇인지 판단하도록 구현
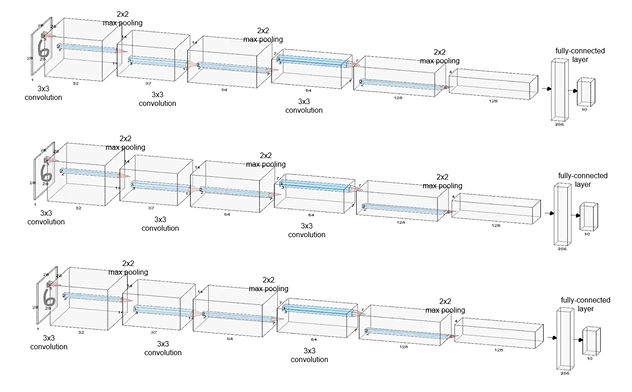
0. Import Libraries
1. Set Hyper Parameters
2. Make a Data Pipelining
3. Build a Neural Network Model - Model Subclassing

4. Define a Loss Function
5. Caculate a Gradient
6. Select an Optimizer
7. Define a Metric for Model's Performance
8. Make a Checkpoint for Saving
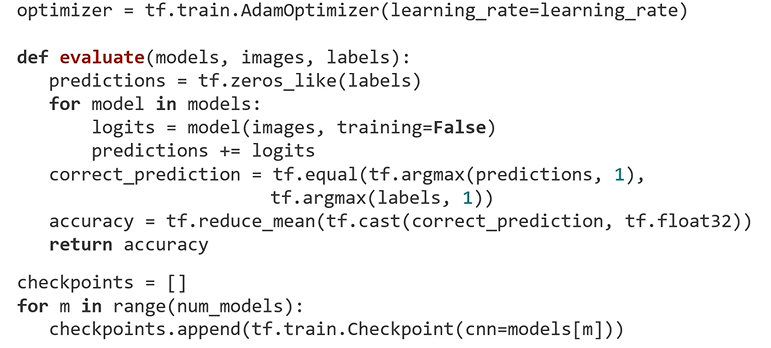 : model 한 개가 아니라 models라고 하는 앞에서 만들었던 list를 받음
: model 한 개가 아니라 models라고 하는 앞에서 만들었던 list를 받음
: predictions을 만듬 - 모델 3개에서 나오는 output을 종합한 결과
9. Train and Validate a Neural Network Model
: model을 바꿔가면서 각각 학습을 진행하는 for문 추가

 : Ensemble로 학습은 각각 한 다음, 각각 학습된 model이 힘을 합쳐서 inference 하는 식으로 구현
: Ensemble로 학습은 각각 한 다음, 각각 학습된 model이 힘을 합쳐서 inference 하는 식으로 구현
- Accuracy : 99.47%
# Best CNN with MNIST Dataset
CNN Model Ensemble with MNIST Data
: 3개의 CNN을 만듬
: 똑같은 dataset을 3개의 모델에 넣어주면서 학습은 각각 실행할 것
: 학습하는 중간중간 혹은 학습이 끝날 때 inference 할 때 같은 image를 넣어줌
: 각각의 모델이 output을 주면 다 합쳐서 0~9중 무엇인지 판단하도록 구현
How to Get the BEST Performance
- Data Augmentation - 데이터의 양을 늘리는 방법
- Batch Normalization
- Model Ensemble
- Learning Rate Decay

0. Import Libraries

1. Set Hyper Parameters
2. Data Augmentation
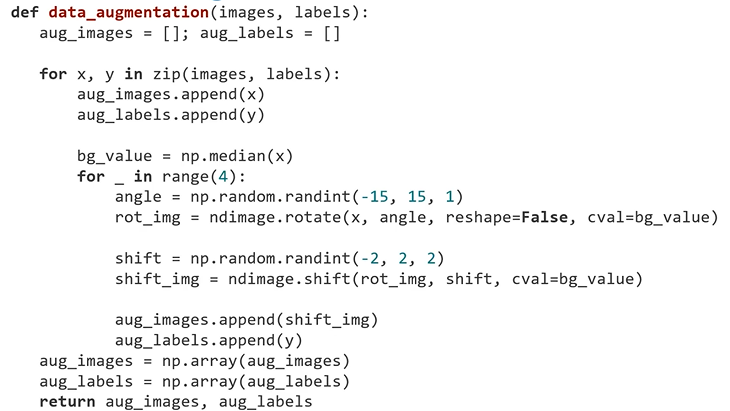 : for문 4번 반복 - 4배의 데이터 만듬
: for문 4번 반복 - 4배의 데이터 만듬
: orginal data 한 번 저장 - 총 5배의 데이터
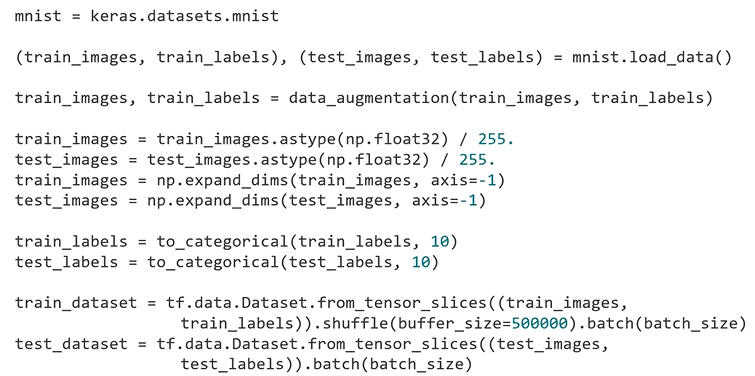
3. Make a Data Pipelining
4. Build a Neural Network Model
: ConvBNRelu class 생성
: Batch Normalization
: Convolution, Batch Normalization, ReLU를 하나의 세트로 묶인 layer를 자체적으로 만듬

:Fully Connected layer에서도 DenseBNRelu class 생성



5. Define a Loss Function
6. Caculate a Gradient
7. Select an Optimizer
8. Define a Metric for Model's Performance
9. Make a Checkpoint for Saving

: 5번 epoch이 지나면 0.5로 learning rate를 줄임
10. Train and Validate a Neural Network Model

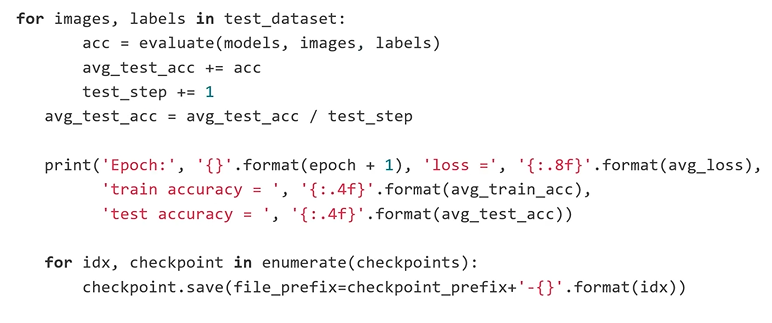
- Accuracy : 99.68%
