# Relu
Problem of Sigmoid
: output과 실제 정답 데이터(=ground-truth)와 얼마만큼 차이가 나는지를 loss라고 부름
: loss를 미분한 것을 backpropagation하면서 network를 학습 시킴
: backpropagation으로 전달되는 loss를 미분한 것을 gradient라고 부름
: gradient는 그래프 관점에서 봤을 때 그래프의 기울기라고 할 수 있음
: sigmoid 함수가 여러 개 있을 때 매우 작은 gradient 값(그래프의 양쪽 부분)이 여러 번 곱해진다면 gradient가 소실되는 현상이 발생하게 됨
= Vanishing Gradient
Why Relu?
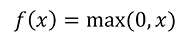
: 어떠한 숫자 값 x를 받았을 때 이 x가 0보다 큰 양수 값을 가진다면 그대로 x를 output값으로 추출
: 만약에 x가 0보다 작은 음수의 값을 갖는다면 그 값을 0으로 바꿔서 output으로 추출
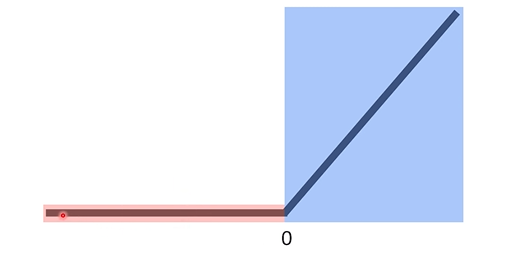
: 파란색 영역은 0보다 큰 영역으로 그대로 값을 도출하기 때문에 gradient가 1이다. (y = x)
: 빨간색 영역은 0보다 작은 음수의 값을 가지기 때문에 gradient가 0이므로 아예 전달이 되지 않음
: 그럼에도 사용하는 이유 - 간단하면서 좋은 성능 향상을 일으키기 때문에
: tf.keras.activations -> sigmoid, tanh, relu, elu, selu
: relu함수의 음수쪽일때의 문제점을 해결한 leaky relu라는 activation function은 keras.layers에서 불러야 함.
: leaky relu는 0보다 작은 음수값을 가질 때 어떤 알파에 x를 곱한 값을 추출함. 알파는 0.01 혹은 0.02정도로 매우 작은 값임.
Load mnist
import tensorflow as tf
import numpy as np
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import mnist # fashion_mnist, cifar, cifar
tf.enable_eager_execution()
def load_mnist() :
(train_data, train_labels), (test_data, test_labels) = mnist.laod_data() # train data는 60000장, test data는 10000장으로 구성
train_data = np.expand_dims(train_data, axis=-1) # [N, 28, 28] -> [N, 28, 28, 1] # expand_dims은 채널을 하나 만들어주는 역할 # axis=-1 축의 맨끝에 채널을 만든다는 뜻
test_data = np.expand_dims(test_data, axis=-1) # [N, 28, 28] -> [N, 28, 28, 1]
train_data, test_data = normalize(train_data, test_data) # [0~255] -> [0~1]
# One hot incoding
train_labels = to_categorical(train_labels, 10) # [N,] -> [N, 10]
test_labels = to_categorical(test_labels, 10) # [N,] -> [N, 10]
return train_data, train_labels, test_data, test_labels
def normalize(train_data, test_data):
train_data = train_data.astype(np.float32) / 255.0
test_data = test_data.astype(np.float32) / 255.0
return train_data, test_dataCreate network
def flatten() :
return tf.keras.layers.Flatten()
def dense(channel, weight_init) :
return tf.keras.layers.Dense(units=channel, use_bias=True, kernel_initializer=weight_init) # unit : output으로 나가는 channel을 몇 개로 설정할 것인지에 대한 것, bias : true면 사용 false면 사용하지 않음
def relu() :
return tf.keras.layers.Activation(tf.keras.activations.relu)
class create_model(tf.keras.Model) # tf.keras.Model 상속 필수
def __init__(self, label_dim):
super(create_model, self).__init__()
weight_init = tf.keras.initializers.RandomNormal()
self.model = tf.keras.Sequential()
self.model.add(flatten()) # [N, 28, 28, 1] -> [N, 784]
for i in range(2):
# [N, 784] -> [N, 256] -> [N, 256]
self.model.add(dense(256, weight_init))
self.model.add(relu())
self.model.add(dense(label_dim, weight_init)) # [N, 256] -> [N, 10]
def call(self, x, training=None, mask=None):
x = self.model(x)
return xDefine loss
def loss_fn(model, images, labels):
logits = model(images, training=True)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits, labels=labels))
return loss
def accuracy_fn(model, images, labels):
logits = model(images, training=False)
prediction = tf.equal(tf.argmax(logits, -1), tf.argmax(labels, -1)) # argmax : logit과 label에서 가장 숫자가 큰 값의 위치가 무엇인지를 알려달라고 요청하는 함수
accuracy = tf.reduce_mean(tf.cast(prediction, tf.float32))
return accuracy
def grad(model, images, labels):
with tf.GradientTape() as tape:
loss = loss_fn(model, images, labels)
return tape.gradient(loss, model.variables)Experiments (parmeters)
""" dataset """
train_x, train_y, test_x, test_y = load_mnist()
""" parmeters """
learning_rate = 0.001
batch_size = 128
training_epochs = 1
training_iterations = len(train_x) // batch_size
label_dim = 10
""" Graph Input using Dataset API """
train_dataset = tf.data.Dataset.from_tensor_slices((train_x, train_y)).\shuffle(buffer_size=100000).\
prefetch(buffer_size=batch_size).\
batch(batch_size).\
repeat()
train_dataset = tf.data.Dataset.from_tensor_slices((train_x, train_y)).\shuffle(buffer_size=100000).\
prefetch(buffer_size=len(test_x)).\
batch(len(test_x)).\
repeat()Experiments (model)
""" Dataset Iterator """
train_iterator = train_dataset.make_one_shot_iterator()
test_iterator = test_dataset.make_one_shot_iterator()
""" Model """
network = create_model(label_dim)
""" Training """
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)Experiments (Eager mode)
checkpoint = tf.train.Checkpoint(dnn=network)
global_step = tf.train.create_global_step()
for epoch in range(start_epoch, training_epochs):
for idx in range(start_iteration, training_iterations):
train_input, train_label = train_iterator.get_next()
grads = grad(network, train_input, train_label)
optimizer.apply_gradients(grads_and_vars=zip(grads, network.variables), global_step=global_step)
train_loss = loss_fn(network, train_input, train_label)
train_accuracy = accuracy_fn(network, train_input, train_label)
test_input, test_label = test_iterator.get_next()
test_accuracy = accuracy_fn(network, test_input, test_label)
print("Epoch: [%2d] [%5d/%5d], train_loss: %.8f, train_accuracy: %.4f, test_Accuracy: %.4f \% (epoch, idx, training_iterations, train_loss, train_accuracy, test_accuracy))
counter += 1
checkpoint.save(file_prefix=checkpoint_prefix + '-{}'.format(counter))# Weight Initialization
Xavier Initialization
: Loss가 가장 최저인 지점을 찾는 것이 Network의 목표
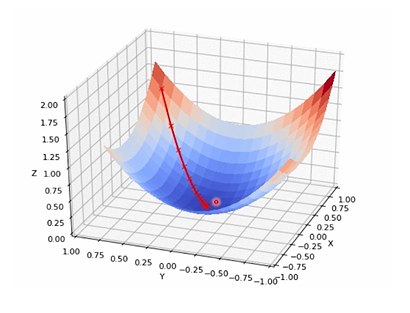
: 실제 loss 그래프는 굉장히 복잡함
: Local Minima에 빠지게 될 위험이 존재
: Global Minima에 가지 못하고 Saddle Point에 도달할 수 있음
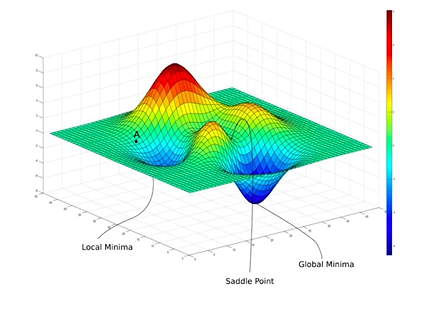
: Xavier는 좋은 출발점을 설정해줌
: Xavier의 평균 = 0 분산 = 2 / (Channel_in + Channel_out)
: Relu = He initialization
: He initialization의 평균 = 0 분산 = Xavier의 2배로 설정
Xavier / He Tensorflow Code
: Relu와 동일
: Xavier를 이용하고 싶다면 -> Create network 부분 수정
weight_init = tf.keras.initializers.glorot_uniform()
: He를 이용하고 싶다면 -> Create network 부분 수정
weight_init = tf.keras.initializers.he_uniform()
: Random : 85.35% -> Xavier : 96.50%
: weight 초기화만 바꾸어도 10%의 성능향상이 이루어짐
# Dropout
Dropout
: 모든 뉴런을 이용해서 학습하는 것이 아닌 일부만을 사용하여 학습하는 것
: test할때는 모든 뉴런을 사용해서 learning 결과 확인
: Regularization

Code
: Relu와 동일
: Create network 부분 아래의 코드 추가
def dropout(rate) :
return tf.keras.layers.Dropout(rate): Create network 부분 class의 for문에 아래의 코드 추가
self.model.add(dropout(rate=0.5))# Batch Normalization
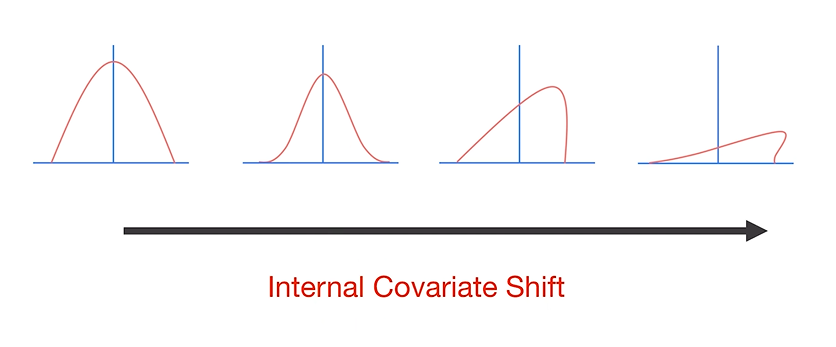
Batch Normalization
: Iternal Covariate Shift를 막고자 함
: Layer의 input으로 들어오는 distribution을 항상 Normalization해주어서 distribution을 일정하게 해줌
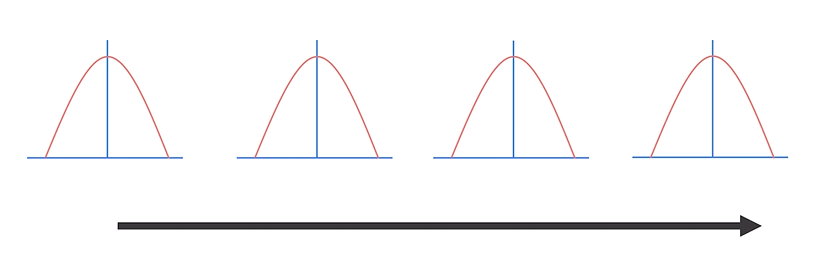
: Normalization 과정을 거친 후
Code
: Relu와 동일
: Create network 부분 아래의 코드 추가
def batch_norm() :
return tf.keras.layers.BatchNormalization(): Create network 부분 class의 for문에 아래의 코드 추가 및 수정
# layer -> norm -> activation 순서 주로 사용
# norm -> activation -> layer
self.model.add(batch_norm())
self.model.add(relu())