Reinforcement Learning (강화 학습)
: 현재 상태 S에서 행동 a를 결정하고 그에 따른 보상을 받아 행동을 수정한다.
: Q테이블은 각 상태집합에서 행동에 따른 우선순위가 있는 테이블이다.
: Q(S, a)는 상태 S에서 a라는 행동을 했을때의 이득값이다.
: 현재 상태의 모든 행동 a에 대해서 Q값을 구해 가장 높은 우선순위의 행동을 수행한다.
: 보통 Q테이블을 배열로 설정하는데 이를 딥러닝 CNN으로 변경한 것이 DQN이다.
-> 그렇기 때문에 상태나 행동이 큰 집합도 학습이 잘 된다.
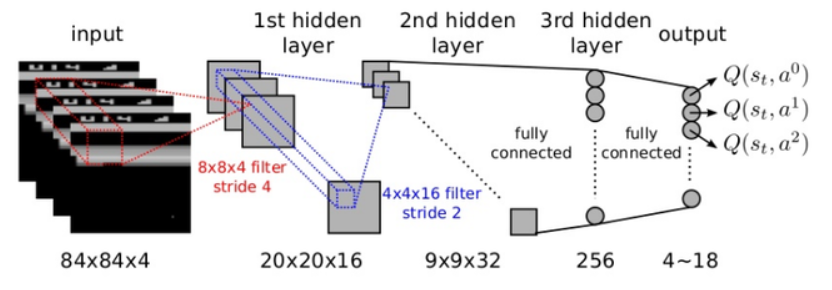
DQN
: Deep Q-Network - 강화학습 알고리즘
: Google Deepmind에서 개발한 알고리즘
: state-action value Q값을 Deep Learning을 통해서 Approximate하는 방식
- Problem
: Deep Learning 적용시 아래의 문제점으로 인해 학습이 잘 되지 않음
1) Correlations between samples
- Deep Learning은 Data Sample이 i.i.d (서로 독립적)이라는 가정을 하지만, Reinforcement Learning에서는 다음 State가 현재 State와 연관성 (Correlation)이 크기 때문에 이 가정이 성립하지 않는다.
2) Non-stationary targets
- prediction을 최적화하기 위해서 Weight를 변경시키며 prediction 값을 수정하지만, target과 같은 network를 사용하기 때문에 prediction이 update되면 target도 움직이게 되는 상황 발생
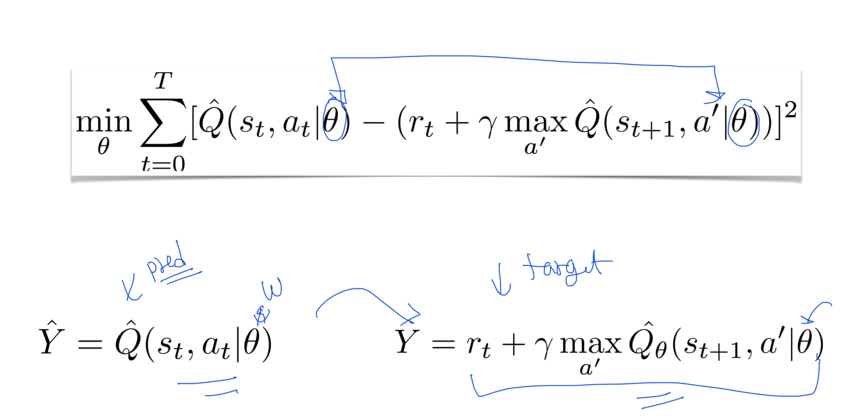
- Solution
1) Go deep
- Convolution layer, Fully connected layer를 사용하여 깊은 network 사용

2) experience replay
- agent에게 action을 취하는 loop를 돌면서 상태를 받아옴, 학습을 하지 않고 버퍼에 저장한 후, 버퍼에서 random하게 몇 개를 가져와서 학습을 시킴.
 : 한 번 액션을 취한 다음, DL의 Weight를 학습 시키지 말고 D라는 buffer에 (S(Current State), A(Action), R (Reward), S'(Next State))값들을 store함.
: 한 번 액션을 취한 다음, DL의 Weight를 학습 시키지 말고 D라는 buffer에 (S(Current State), A(Action), R (Reward), S'(Next State))값들을 store함.
: 학습을 시킬 때, D라는 buffer에서 random하게 sampling을 해서 minibatch 만들어서 이를 기반으로 학습하라는 뜻
3) separate target network, copy network
- network을 하나 더 만들어서 예측한 후에 copy하여 target을 가져옴.
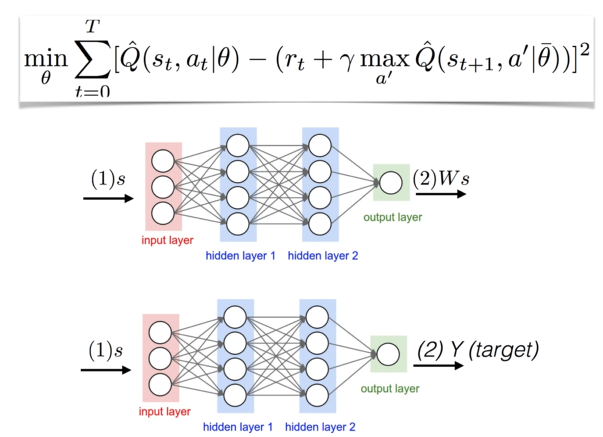
 : Q' network에서 가져오는 target y를 만들고, 예측하는 prediction은 다른 network에서 가져온다.
: Q' network에서 가져오는 target y를 만들고, 예측하는 prediction은 다른 network에서 가져온다.
: 이 network만 gradient descent하고, y는 건들지 않는다.
: 어느정도 시간이 지난 후, 모든 C step에 새로운 network를 복사
- Nature, 'Human-level control through deep reinforcement learning'
 : replay memory buffer D를 만든다.
: replay memory buffer D를 만든다.
: Q network와 Q' network 두 개의 network를 만든다.
: 초기에는 같게 두 network를 만들고, initialize 함.
: Q network을 이용하여 random하게 action을 선택한다.
: action이 선택되면 선택된 action을 실행시키며, 어떤 환경(이미지)과 상을 받아옴.
: 그것을 preprocess한 다음, 바로 학습하지 않고 D라는 buffer로 모두 복사하여 저장
: 일정 시간이 지나면 D라는 buffer에서 random한 sample을 가져와서 학습을 시킴.
: 학습을 시킬 때 두 개의 network는 분리함.
: Set yj -> target network이라고 할 수 있음. target network는 세타'에서 가져올 수 있음.
: 세타'에서 가져온 target network와 세타에서 가져온 예측한 값을 비교해서 세타를 update 시킴
: 시간이 지나면 Q'의 세타' network를 update 시켜라. -> copy
참고 자료
Lecture 7: DQN - Sung Kim, youtube channel
