본 자료는 심민경 코치님의 자료와 Elice 플랫폼의 자료를 사용하여 정리하였습니다.
자료구조 2
딕셔너리
딕셔너리 특징
- 키와 값의 순서쌍으로 구성
- 키는 중복 X
딕셔너리 이름 = {키1:값1, 키2:값2, ..., 키n:값n}형태
딕셔너리 메소드
.get(key): 키에 해당하는 값 반환.keys(): 키 전부 출력.values(): 값 전부 출력.items(): 딕셔너리 출력
갯수 확인
len(딕셔너리)
요소 추가
딕셔너리이름[새로 추가할 키] = 값
요소 수정
딕셔너리이름[수정할 키] = 새로운 값
요소 삭제
- 특정요소 삭제
del 딕셔너리이름[삭제할 키] - 모든 요소 삭제
딕셔너리이름.clear()
Set
Set 특징
- 순서도, 중복도 없는 자료형
set이름 = {값1, 값2, ..., 값3}형태
Set 메소드
.add('새요소'): 요소 1개 추가.update('새요소1', '새요소2', ..., '새요소n'): 요소 여러 개 추가.remove('기존요소'): 특정요소 삭제.clear(): 전체요소 삭제
Set : 교집합/합집합/차집합
- 교집합 연산
set1 & set2 set1.intersection(set2) - 합집합 연산
set1 | set2 set1.union(set2) - 차집합 연산
set1 - set2 set1.difference(set2) - XOR도 가능하다.
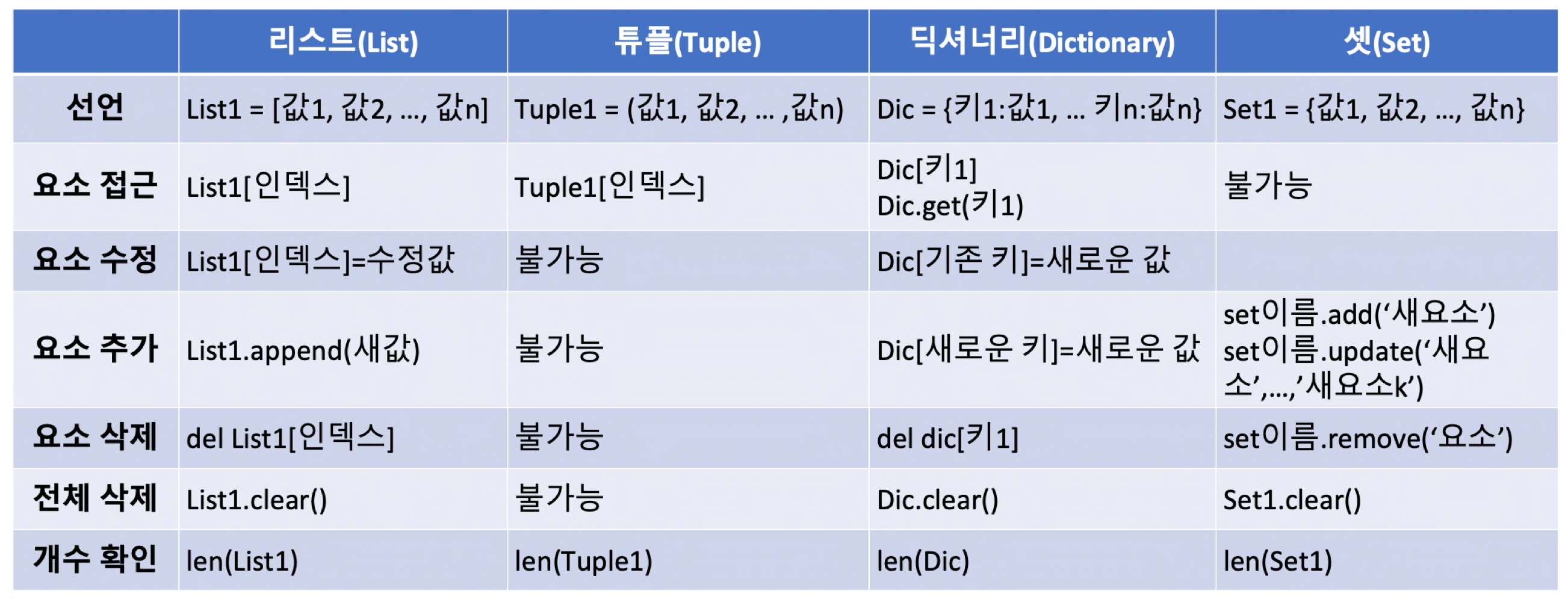
복합자료형 비교
파일 입/출력
CSV
CSV 장점
- 같은 데이터를 저장하는 데 용량을 적게 소모한다.
CSV 단점
- 데이터 오염에 취약하다.
python에서 CSV 열기
import csv
with open('movies.csv') as file:
reader = csv.reader(file, delimiter = ',')
for row in reader:
print(row[0])판다스로 CSV 열기
import pandas as pd
변수명 = pd.read_csv(파일경로)JSON
JSON이란?
- "키-값"으로 이루어진 데이터 오브젝트를 전달
- 사람이 읽고 쓰고, 기계가 분석하고 생성하기 용이
- 개방형 표준 포맷이고, 구조에 제한이 없다.
- 웹 환경에서 데이터를 주고받는 가장 표준적인 방식
- 키를 이용하여 원하는 데이터만 빠르게 추출 가능
- 데이터가 쉽게 오염되지 않는다.
- 다른 포맷에 비해 용량이 조금 큰 편이다.
JSON 라이브러리 호출
import json
JSON을 Python 딕셔너리로 변환
변수명 = json.loads(json명, strict = False)
Python 딕셔너리를 JSON으로 변환
변수명 = json.dumps(딕셔너리, ensure_ascii = False)
JSON 파일 읽어오기
변수명 = json.load(open(json명, 'r', encoding = 'utf-8'))
- with open을 사용하는 경우
with open(json명, 'r', encoding = 'utf-8') as f: 변수명 = json.load(f)
대용량 데이터 처리
Iterable
- 차례로 하나 씩 반복해서 반환할 수 있는 객체
- List, Set, Tuple, Dictionary
Iterator
- 값을 차례대로 꺼낼 수 있는 객체
- next() 메소드로 데이터를 순차적으로 호출할 수 있다.
- List는 iterator가 아니지만, for문에서 임시로 iterator로 쓰인다
y = iter(x)
next(y)Generator
- Iterator를 생성해주는 함수
유용한 파이썬 함수
Lambda 함수
- 한 줄짜리 이름 없는 함수
lambda 필요한 동작, 인수형태
lambda r: r*r*pi
assert 함수
- assert안에 연산을 검증해준다.
map 함수
- 원소를 함수에 대입한 결과를 반환
map(함수, 인자가 들어있는 리스트) - 함수부분에 lambda를 사용해도 된다.
filter 함수
- 함수 결과가 True인 경우 결과를 반환
filter(함수, 인자가 들어있는 리스트) - 함수부분에 lambda를 사용해도 된다.

열심히