본 자료는 심민경 코치님의 자료를 사용하여 정리하였습니다.
Python Review
객체 지향 프로그래밍
- 클래스에서 정의한 객체를 상호연결해 문제를 해결하는 과정
객체란?
- 클래스에서 정의한 것을 토대로 메모리(실제 저장공간)에 할당된 것
- 프로그램에서 사용되는 데이터 또는 식별자에 의해 참조되는 공간을 의미
- 변수, 자료구조, 함수 또는 메소드가 될 수 있다.
객체의 구성요소
- 속성 : 자신의 상태를 표현하는 정적인 성질
- 행위 : 객체 내부 혹은 다른 객체와 상호작용하는 행위
- 같은 속성, 다른 속성값
- 미리 지정된 행위 : 외부요청에 따라 객체는 미리 정해진 일을 스스로 처리
자신의 데이터를 가지고 필요한 처리를 스스로 수행하는 연관된 정보(변수, 함수)들의 묶음
클래스
- 공통의 속성을 갖되, 서로 다른 속성값을 지니면서 공통의 행위를 수행하는 같은 종류의 객체를 생성하기 위해 정의되는 틀
함수(Function) vs 메소드(Method)
함수
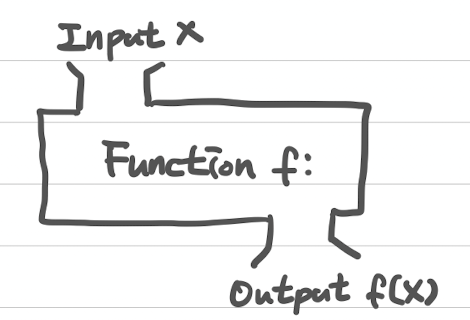
- 내장함수
- 파이썬 내부에 호출 형태와 동작 내용이 미리 정의된 함수
- print 등
메소드
- 함수와 다르게 인자를 넣어 주지 않아도 된다.
모듈
- 전역변수, 함수, 클래드 등을 모아놓은 .py확장자를 가진 파일
- 다른 파이썬 파일에서 모듈을 import명령어를 이용해 불러올 수 있다.
패키지(라이브러리)
- 모듈을 모아놓은 폴더
자료구조 1
자료형(Data Type)
- 하나의 값을 나타내는 데이터의 유형
- 기본자료형(데이터 하나)
- 정수형, 실수형, 복소수형, 논리형, 문자열
- 복합자료형(다수의 데이터 묶음)
- 리스트, 튜플, 딕셔너리, 집합
문자열
- 문자 혹은 문자들의 묶음
- 같은 종류의 따옴표로 감싸진 문자들
- 문자열 조작
- 인덱싱
- 문자열을 구성하는 문자들의 순번(인덱스 값)에 따라 해당문자를 얻어오는 연산
- 첫 번째 문자에 대한 인덱스 값이
0번 - 마지막 문자는
-1로 시작, 왼쪽으로 하나씩 이동(세글자의 경우-3,-2,-1) 문자열[인덱스]형태
- 슬라이싱
- 범위 표현으로 문자열을 구성하는 부분 문자열을 얻는 연산
- 문자열의 시작 인덱스부터 끝 인덱스이전까지 부분문자열
문자열[시작:끝]형태
- 인덱싱
- 문자열 메소드
문자열.upper(): 대문자로 변환문자열.lower(): 소문자로 변환문자열.replace(찾을 문자열, 새 문자열): 문자열 대체문자열.startswith(특정 문자열): 시작문자열 체크문자열.split(구분자): 구분자를 기준으로 잘라서 리스트로 반환
리스트
- 저장 순서가 있는 변수들의 묶음
- 다수의 데이터를 모아 하나의 이름으로 저장
- 반복문과 함께 사용하면 효율적으로 데이터에 접근할 수 있다.
- n개의 요소(element)를 갖는 리스트 선언문
리스트 이름 = [값1, 값2, ..., 값3]형태- 리스트 조작
- 인덱싱
- 유효한 순번에 따라 각 요소 데이터를 개별적으로 선택해 접근가능
리스트이름[인덱스]형태
- 슬라이싱
- 범위를 지정해서 리스트를 구성하는 일부요소를 또 다른 리스트로 생성하는 연산
리스트이름[시작 인덱스:끝 인덱스]형태
- 인덱싱
- 리스트 내장함수
len(리스트 이름): 데이터의 개수 확인sorted(리스트 이름, reverse=false): 정렬- reverse가 true면 내림차순 정렬
리스트이름.append(값): 맨 마지막에 값 추가
For 반복문
- 지정된 횟수만큼 반복하거나, 일정 범위를 일정한 간격으로 증감하며 반복
for 변수 in 범위표현식: 수행할 문장 - 범위 for 반복문
for 변수 in range(start, end, step): 수행할 문장 - List for 반복문
for 변수 in list: 수행할 문장
튜플
- 리스트와 유사한 복합자료형
- 한 번 정의된 이후, 튜플에 포함된 요소를 수정, 삭제가 불가능하다.
- 튜플에 새 요소를 추가할 수 없다.
튜플이름 = (값1, 값2, ..., 값n)형태- 튜플 인덱싱, 슬라이싱, 연결
- 리스트와 같은 방식으로 인덱싱, 슬라이싱 가능
- 튜플에 정의된 후 요소를 수정하거나, 추가할 수 없지만 연결은 가능
새로운 튜플이름 = 튜플1 + 튜플2형태새로운 튜플이름 = 튜플 * 반복 수형태
파일 입/출력
- pandas 라이브러리를 활용해 csv파일을 데이터프레임으로 읽어올 수 있다.
- 판다스 라이브러리 호출
import pandas as pd - 특정 경로에 저장된 csv파일을 데이터 프레임으로 생성
변수명 = pd.read_csv(파일경로)
데이터 시각화
- matplotlib 라이브러리 활용(numpy 배열 기반)
import numpy as np import matplotlib as mpl or import matplotlib.pyplot as plt - 데이터프레임에 저장된 특정컬럼을 리스트 or 배열로 저장
변수명 = list(데이터프레임 명[컬럼명]) or 변수명 = np.array(데이터프레임 명[컬럼명]) - 히스토그램 그리기
plt.hist(변수명, bins=18, color='#800080')

열심히