Intent
Provide a way to access the elements of an aggregator object sequentially w/o exposing its underlying representation
Also Known As
Cursor
Motivation
An aggregate object needs a way to access elems w/o exposing details. And you might also need different ways to traverse it too. But you don't want to bloat the interface w/ too many options for traversals.
The key idea in this pattern is to take the responsibility for access and traversal out of the list object and put it into an iterator object. Iterator class will define interface to traverse a List object, as well as keeping track of current elem.
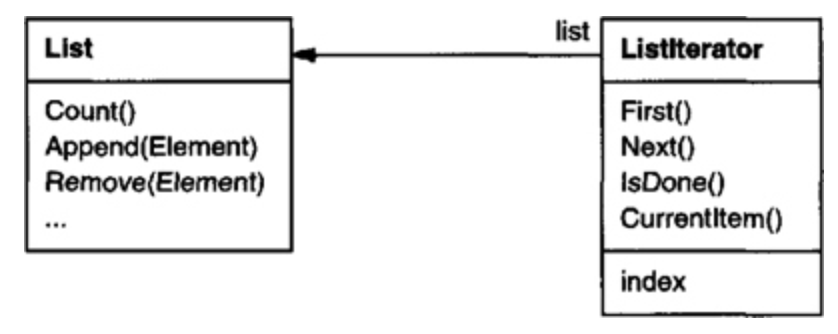
Separating the traversal mechanism from the List object lets us define iterators for different traversal policies without enumerating them in the List interface. For example, FilteringListIterator might provide access only to those elements that satisfy specific filtering constraints.
Notice that the iterator and the list are coupled, and the client must know that it is a list that’s traversed as opposed to some other aggregate structure. Hence the client commits to a particular aggregate structure. It would be better if we could change the aggregate class without changing client code. We can do this by generalizing the iterator concept to support polymorphic iteration.
Then an abstract class may be defined, making iterator mechanism become independent of concrete aggregate classes.
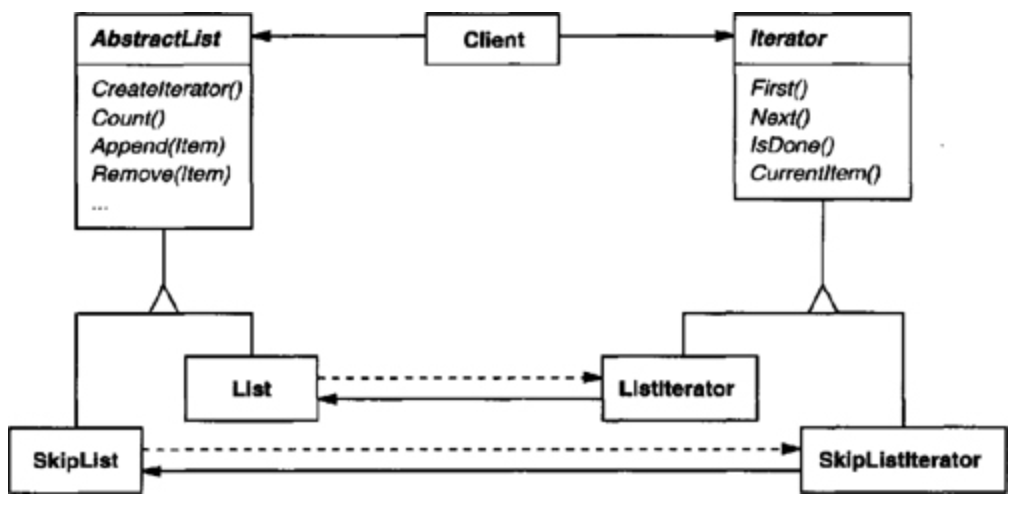
The remaining problem is how to create the iterator. Since we want to write code that’s independent of the concrete List subclasses, we cannot simply instantiate a specific class. Instead, we make the list objects responsible for creating their corresponding iterator. This requires an operation like CreateIterator through which clients request an iterator object.
CreateIterator is an example of a Factory Method. We use it here to let a client ask a list object for the appropriate iterator. The Factory Method approach give rise to two class hierarchies, one for lists and another for iterators. The CreateIterator factory method “connects” the two hierarchies.
Applicability
Use the Iterator pattern
• to access an aggregate object’s contents without exposing its internal representation.
• to support multiple traversals of aggregate objects.
• to provide a uniform interface for traversing different aggregate structures (that is, to support polymorphic iteration).
Structure
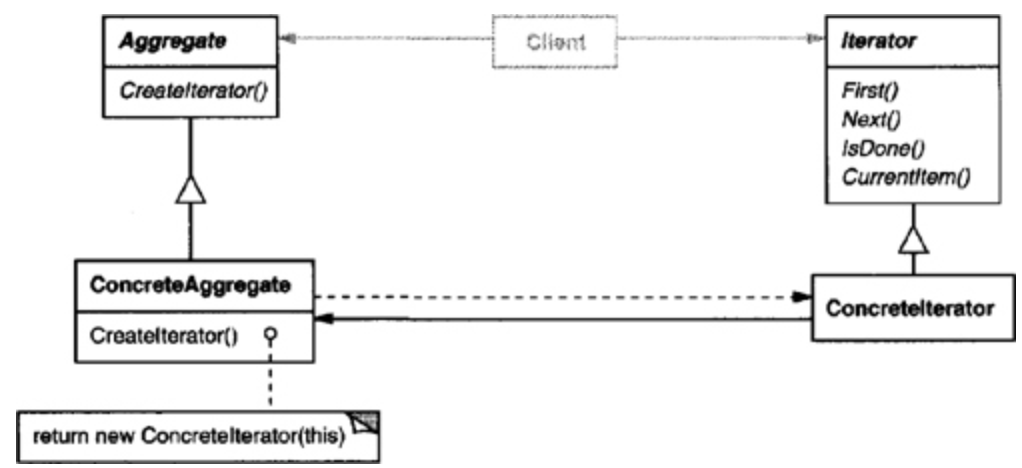
Participants
- Iterator
- defines an interface for accessing and traversing elements.
- ConcreteIterator
- implements the Iterator interface.
- keeps track of the current position in the traversal of the aggregate.
- Aggregate
- defines an interface for creating an Iterator object.
- ConcreteAggregate
- implements the Iterator creation interface to return an instance of the proper ConcreteIterator.
Collaborations
- A ConcreteIterator keeps track of the current object in the aggregate and can compute the succeeding object in the traversal.
Consequences
The Iterator pattern has three important consequences:
- It supports variations in the traversal of an aggregate. Complex aggregates may be traversed in many ways.
- Iterators simplify the Aggregate interface. Iterator’s traversal interface obviates the need for a similar interface in Aggregate, thereby simplifying the aggregate’s interface.
- More than one traversal can be pending on an aggregate. An iterator keeps track of its own traversal state. Therefore you can have more than one traversal in progress at once.
Implementation (Long)
Iterator has many implementation variants and alternatives. Some important ones follow. The trade-offs often depend on the control structures your language provides. Some languages even support this pattern directly.
-
Who controls the iteration? Internal iterator are usually easier to use, as they define the iteration logic. External iterator, meaning client advance traversal, request next elem explicitly, are more flexible.
-
Who defines the traversal algorithm? The iterator is not the only place where the traversal algorithm can be defined. The aggregate might define the traversal algorithm and use the iterator to store just the state of the iteration. This kind of iterator is a cursor, since it merely points to the current position in the aggregate. A client will invoke the Next operation on the aggregate with the cursor as an argument, and the Next operation will change the state of the cursor.
If the iterator is responsible for the traversal algorithm, then it’s easy to use different iteration algorithms on the same aggregate, and it can also be easier to reuse the same algorithm on different aggregates (perhaps strategy pattern?). On the other hand, the traversal algorithm might need to access the private variables of the aggregate. If so, putting the traversal algorithm in the iterator violates the encapsulation of the aggregate.
-
How robust is the iterator? It can be dangerous to modify an aggregate while you’re traversing it. If elements are added or deleted from the aggregate, you might end up accessing an element twice or missing it completely. A simple solution is to copy the aggregate and traverse the copy, but that’s too expensive to do in general.
A robust iterator ensures that insertions and removals won’t interfere with traversal, and it does it without copying the aggregate. There are many ways to implement robust iterators. Most rely on registering the iterator with the aggregate. On insertion or removal, the aggregate either adjusts the internal state of iterators it has produced, or it maintains information internally to ensure proper traversal.
(some examples from book. Not sure what an ET++ is even.. Kofler provides a good discussion of how robust iterators are implemented in ET++ [Kof93]. Murray discusses the implementation of robust iterators for the USL StandardComponents’ List class [Mur93].) -
Additional Iterator operations. The minimal interface to Iterator consists of the operations First, Next, IsDone, and CurrentItem. (We can make this interface even smaller by merging Next, IsDone, and CurrentItem into a single operation that advances to the next object and returns it. If the traversal is finished, then this operation returns a special value (0, for instance) that marks the end of the iteration.)
Some additional operations might prove useful. For example, ordered aggregates can have a Previous operation that positions the iterator to the previous element. A SkipTo operation is useful for sorted or indexed collections. SkipTo positions the iterator to an object matching specific criteria.
-
Using polymorphic iterators in C++. (I think this is irrelevant for js or python) Polymorphic iterators have their cost. They require the iterator object to be allocated dynamically by a factory method. Hence they should be used only when there’s a need for polymorphism. Otherwise use concrete iterators, which can be allocated on the stack.
Polymorphic iterators have another drawback: the client is responsible for deleting them. This is error-prone, because it’s easy to forget to free a heap-allocated iterator object when you’re finished with it. That’s especially likely when there are multiple exit points in an operation. And if an exception is triggered, the iterator object will never be freed.
The Proxy pattern provides a remedy. We can use a stack-allocated proxy as a stand-in for the real iterator. The proxy deletes the iterator in its destructor. Thus when the proxy goes out of scope, the real iterator will get deallocated along with it. The proxy ensures proper cleanup, even in the face of exceptions. This is an application of the well-known C++ technique “resource allocation is initialization” [ES90]. The Sample Code gives an example.
-
Iterators may have privileged access. An iterator can be viewed as an extension of the aggregate that created it. The iterator and the aggregate are tightly coupled. We can express this close relationship in C++ by making the iterator a friend of its aggregate. Then you don’t need to define aggregate operations whose sole purpose is to let iterators implement traversal efficiently.
However, such privileged access can make defining new traversals difficult, since it’ll require changing the aggregate interface to add another friend. To avoid this problem, the Iterator class can include protected operations for accessing important but publicly unavailable members of the aggregate. Iterator subclasses (and only Iterator subclasses) may use these protected operations to gain privileged access to the aggregate.
-
Iterators for composites. External iterators can be difficult to implement over recursive aggregate structures like those in the Composite pattern, because a position in the structure may span many levels of nested aggregates. Therefore an external iterator has to store a path through the Composite to keep track of the current object. Sometimes it’s easier just to use an internal iterator. It can record the current position simply by calling itself recursively, thereby storing the path implicitly in the call stack.
If the nodes in a Composite have an interface for moving from a node to its siblings, parents, and children, then a cursor-based iterator may offer a better alternative. The cursor only needs to keep track of the current node; it can rely on the node interface to traverse the Composite.
Composites often need to be traversed in more than one way. Preorder, postorder, inorder, and breadth-first traversals are common. You can support each kind of traversal with a different class of iterator. -
Null iterators. (wow a base case) A NullIterator is a degenerate iterator that’s helpful for handling boundary conditions. By definition, a NullIterator is always done with traversal; that is, its IsDone operation always evaluates to true.
NullIterator can make traversing tree-structured aggregates (like Composites) easier. At each point in the traversal, we ask the current element for an iterator for its children. Aggregate elements return a concrete iterator as usual. But leaf elements return an instance of NullIterator. That lets us implement traversal over the entire structure in a uniform way.
Sample code
in book as C++, me trying to rewrite in python3
Known Uses
Iterators are common in object-oriented systems. Most collection class libraries offer iterators in one form or another. So, refer to docs on collections for your language of choice?
Related Patterns
Composite: Iterators are often applied to recursive structures such as Composites.
Factory Method: Polymorphic iterators rely on factory methods to instantiate the appropriate Iterator subclass.
Memento: is often used in conjunction with the Iterator pattern. An iterator can use a memento to capture the state of an iteration. The iterator stores the memento internally.
